大家好,我是何三,独立开发者
32KB。一行 script 标签。 让 AI 操控你的网页。
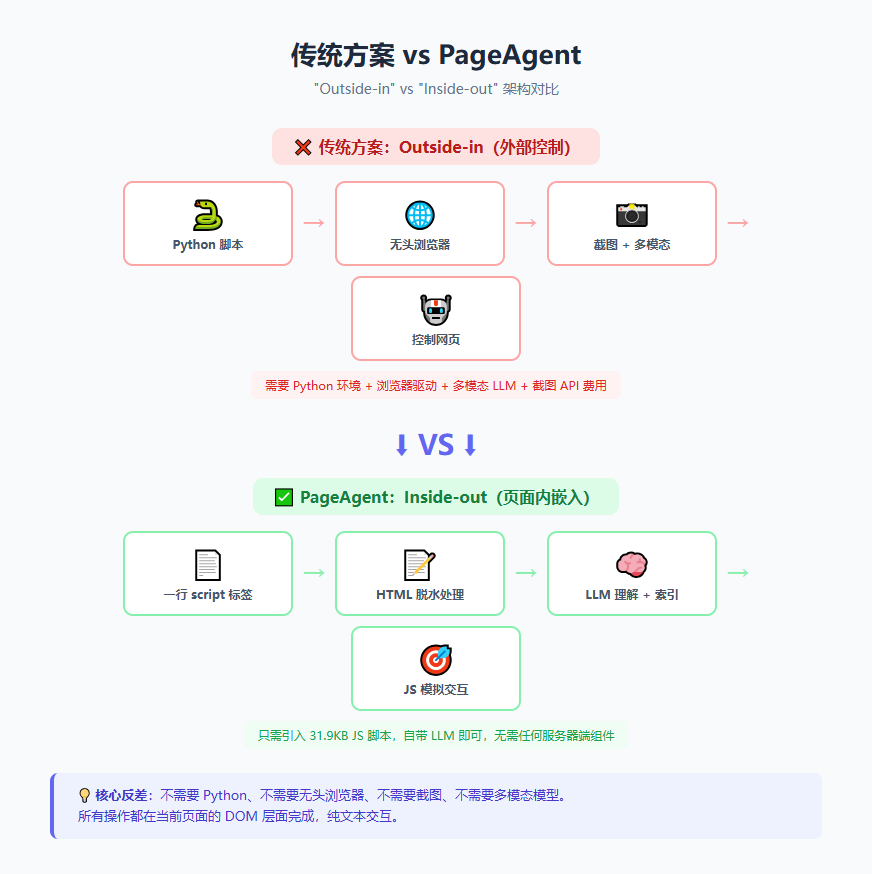
没跟你开玩笑。阿里的开源项目 page-agent,gzip 压缩后只有 31.9KB,做到的事跟 browser-use 这种 Python 全家桶差不多——甚至某些场景更好。而 browser-use 呢?装 Python、配环境、搞无头浏览器、还要多模态 LLM 烧 API 额度……
这反差,怎么说呢,就是离谱他妈给离谱开门。
Page-agent 目前在 GitHub 上已经 19.2k Star(近 2 万),NPM 月下载 4 万多,Hacker News 上也是 Show HN 热门,147 points 加 76 条讨论。一个阿里员工在工作之余搞的项目,MIT 协议开源,纯 TypeScript 写的。
简单说,你往网页里塞一个 script 标签,你的页面就变成了一个 AI Agent。
比如你做了一个 ERP 后台,用户说"帮我查上个月华南区的销售数据,做个图表",以前你得写一堆点击联动逻辑。现在,PageAgent 帮你理解这句话,然后直接在页面上操作 DOM 元素,找到对应的按钮、输入框、表格,完成整个流程。
这个理念叫 "inside-out"——让 AI 活在网页内部,而不是从外部操控。
想想以前那些方案:Python 脚本启动一个无头浏览器,截图发给多模态模型,模型说"这里有点击",脚本再去找坐标……鬼都知道这玩意儿有多脆弱。截图糊了怎么办?坐标偏移了呢?页面重绘了呢?
PageAgent 的思路完全不一样——它直接读取 活的 DOM 树,拿到的是页面最底层的结构数据,不是一张图片。然后它把 DOM 简化成 LLM 能理解的文本格式(作者管这叫"HTML 脱水"),让模型通过索引去操作具体元素。
说白了,以前是让 AI "看"你的网页,现在是让 AI "读"你的网页。
不用截图,不用多模态,token 消耗直线下降。
说实话,这个脱水逻辑具体怎么实现的,我看了源码也没完全搞懂——涉及到很多 DOM 解析和语义压缩的细节。但核心思路我能讲明白:就是把
原理大概是这样,细节可能有出入——有懂的大佬欢迎指正。
说到这个"inside-out",我突然想到一个事儿。以前玩《黑客帝国》的时候,总在想:为什么 AI 要从外部控制世界?后来明白了,因为从内部控制太危险——权限太大了。PageAgent 本质上就是在做这件事:它直接在页面内部运行,拥有当前用户的所有会话权限。所以它才不需要装插件、不需要无头浏览器、不需要重新登录。
但是!这也意味着安全问题确实存在——一个第三方的 script 标签能访问你页面上的一切。不过作者也说了,这跟你引入任何其他第三方 JS 库的风险是一样的,并不是 PageAgent 独有的问题。而且它可以配合 CSP、白名单机制来控制。
我真的吹爆这个集成体验。
一行 CDN:
<script src="https://cdn.jsdelivr.net/npm/page-agent@1.10.0/dist/iife/page-agent.demo.js" crossorigin="true"></script>
就这。你的页面就有 AI 了。
不过这个 Demo 版用的是阿里的免费测试 LLM(Qwen 模型),仅供体验。生产环境你得自己配 LLM:
npm install page-agent
import { PageAgent } from 'page-agent' const agent = new PageAgent({ model: 'qwen3.5-plus', baseURL: 'https://dashscope.aliyuncs.com/compatible-mode/v1', apiKey: 'YOUR_API_KEY', language: 'zh-CN', }) await agent.execute('点击登录按钮')
看到没?await agent.execute('点击登录按钮')——真的就是一句话。
await agent.execute('点击登录按钮')
你还可以把 LLM 换成任何 OpenAI 兼容的 API,甚至本地的 Ollama 都行。作者说测试过 Qwen3.5 4B 的小模型也能跑,不过大模型效果更好就是了。
还提供了一个 Bookmarklet 的方式——你从官网拖一个小书签到书签栏,在任何页面上点击,就能临时注入 PageAgent 试玩。这个设计真的绝,不用装任何东西就能体验。
说实话,我翻了一遍它的用例文档,脑子里蹦出好几个"卧槽这个可以"的瞬间。
给 SaaS 产品加 AI Copilot——几行代码给你的产品加上"帮我做这个"的功能,不用重写后端。CRM 里说"帮我导出今天所有成交客户的联系方式",它自己操作页面去完成。
智能表单填充——ERP 系统里 20 步的填表流程,一句话搞定。"帮我创建一个采购订单,供应商是 XXX,金额 5 万以下,走常规审批。"
无障碍增强——让视障用户用语音就能操作网页。PageAgent 在内部跑,语音输入→LLM 理解→操作 DOM,整个链路都在前端完成。
跨页面 Agent——通过可选的 Chrome 扩展,PageAgent 可以跨浏览器标签页工作。比如"从 A 系统的客户列表复制数据,到 B 系统的后台创建订单"这种骚操作也能实现。
还支持 MCP 协议(测试阶段),可以让你自己的 Agent 客户端通过 MCP 控制浏览器。
没懂为什么有人会觉得这玩意儿会被浏览器内置的 Agent 取代——恰恰相反,我觉得这种"可嵌入的 Agent"才是未来。浏览器内置的 Agent 你没法定制,没法控制数据流向,没法跟自己现有的系统打通。
PageAgent 的思想基础来自 browser-use(Python 那个很有名的项目),但做了个 180 度大转弯——从 Python 后端自动化变成了前端嵌入式。如果你的场景是服务端爬虫,browser-use 可能更合适;如果你想给自己的 Web 应用加 AI,那 PageAgent 是更好的选择。
另一个方向是 Playwright 和 Puppeteer——它们是浏览器自动化的事实标准,但定位完全不同。它们是为测试和爬虫设计的,不可能嵌入到你的产品里当 AI Copilot。
GitHub: https://github.com/alibaba/page-agent
在线 Demo(无需注册就能玩): https://alibaba.github.io/page-agent/
官方文档: https://alibaba.github.io/page-agent/docs/introduction/overview
一个忠告:不要直接把 API Key 写在前端代码里。老老实实整个代理后端,把 Key 藏好。这跟 PageAgent 无关,是所有前端调用 LLM 的基本常识。
除此之外,这个项目真的值得你去 Star 一下。31.9KB 的 JS,打开了一个全新的设计空间。未来你的每个网页应用里都住着一个 AI Agent,这个想象空间,我觉得挺带感的。
本文使用 MGO 编辑并发布
关注“何三笔记”,回复“mgo” 免费下载使用
版权声明:如无特殊说明,文章均为何三笔记原创,转载请注明出处 本文链接:https://www.h3blog.com/article/873/
版权声明:如无特殊说明,文章均为何三笔记原创,转载请注明出处
本文链接:https://www.h3blog.com/article/873/
请使用支付宝扫一扫