大家好,我是何三,独立开发者
Redis 之父 Salvatore Sanfilippo(antirez)——对,就是那个写了 Redis、被全球开发者供在神坛上的男人——前两天突然在 GitHub 丢了个新项目。
名字叫 ds4.c。一个专门为 DeepSeek V4 Flash 写的推理引擎,纯 C 语言,只跑在 Apple Silicon 上。
项目上线不到 48 小时,Star 数逼近 2000。
等等,他不是搞数据库的吗?怎么跑去给大模型写推理引擎了?
更离谱的是——284B 参数的模型,他硬是让它跑在了 MacBook 上。
一个大佬,为什么要「重复造轮子」
这年头搞本地推理,llama.cpp 已经是事实标准了。GGUF 格式、多后端支持、社区庞大,几乎什么模型都能跑。
按理说,antirez 直接提个 PR 给 llama.cpp 加 DeepSeek V4 支持就完事了。事实上他确实这么干过——他还专门 fork 了一个 llama.cpp-deepseek-v4-flash 的实验分支。
但他后来做了个大胆的决定:另起炉灶,单独写一个引擎。
为什么?他的原话是:
"DeepSeek V4 Flash 太特别了,值得拥有一个独立的引擎。"
说白了,他觉得通用框架绑手绑脚,不如针对这个模型「量身定制」一把。
你还别说,这很 Redis 风格——单一职责、极致简单、不搞花架子。
DeepSeek V4 Flash 到底特别在哪?
我直接说结论:这是目前最适合本地部署的「准前沿模型」。
DeepSeek V4 Flash 是 DeepSeek 最新发布的 MoE(混合专家)模型,总参数量 284B,但每次推理只激活约 37B 参数。这意味着什么?
大白话来说就是它长着一副千亿级模型的大脑,但干活的时候只用小脑,所以又快又省内存。
但这还不是最炸裂的。antirez 列了 8 个理由,我挑几个最让人心动的:
- 思考长度跟问题复杂度成正比。问简单问题它思考短,问难问题它思考长——不会像其他模型那样无论啥问题都疯狂打几千字小作文。同样的思考模式,其他模型思考 5000 token,它只花 1000。
- 上下文 100 万 tokens。什么概念?你扔三本《三体》进去它都记得住。
- 2-bit 量化后效果出奇地好。一般模型压到 3-bit 以下基本就变智障了,但它 2-bit 量化后还能当编程助手用。
- KV 缓存压缩率极高,甚至可以存到硬盘上随时恢复。
就是这种种特性让 antirez 觉得:这模型值得我单独为它写个引擎。
ds4.c 到底干了件什么事
说白了这个项目就做了一件事:让 DeepSeek V4 Flash 在 Mac 上跑得飞快。
它没有用 Python,没有用 PyTorch,没有套一层 llama.cpp——而是直接用 C + Metal(苹果的 GPU 计算框架) 从底层写起。
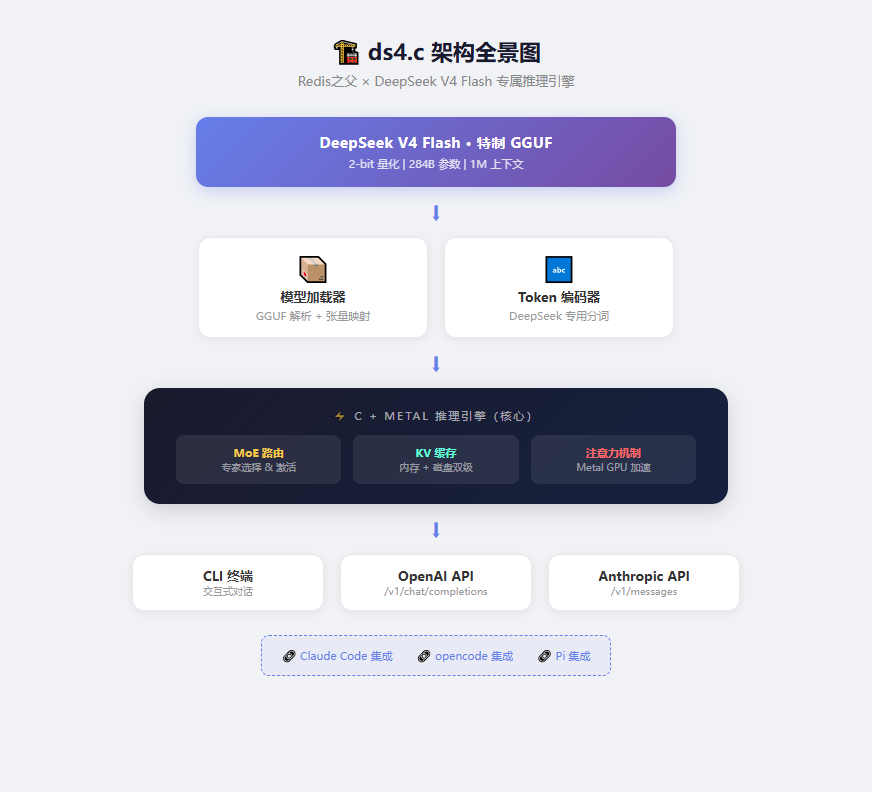
整个项目就几个核心概念:
1. 不是通用的 GGUF 加载器
ds4.c 只能跑 antirez 特制的 GGUF 文件。他专门搞了一套很「偏心」的量化方案——路由专家(routed MoE experts)用超低精度(IQ2_XXS 和 Q2_K),但共享专家、投影层等关键部件保持高精度。
这样既把模型塞进了 128GB 内存,又保住了推理质量。
2. KV 缓存是硬盘的一等公民
这可能是最颠覆性的设计。一般推理引擎把 KV 缓存当内存数据对待,但 antirez 受 Redis 影响,觉得这东西应该像数据库一样持久化到磁盘。
他实现了磁盘 KV 缓存机制:当你跑同一段对话的不同分支时,不用重新处理整个上下文,直接从磁盘恢复之前的缓存状态就行。
为什么这么设计?别问我,问作者去。反正他在 README 里写得很直白:"那个压缩后的 KV 缓存,配合现代 MacBook 的高速 SSD,让我觉得 KV 缓存属于磁盘而不是内存。"
3. 自带 OpenAI/Anthropic 兼容 API
这不是一个让你在终端里玩的玩具。它跑起来后直接提供 /v1/chat/completions(OpenAI 风格)和 /v1/messages(Anthropic 风格)的 API 接口。
这意味着——你可以用 Claude Code、opencode、Pi 这些编程 Agent 直接连到本地跑的 DeepSeek V4 上,完全免费,数据不出本机。
上手试试
说实话,配置要求有点硬核——至少需要 128GB 内存的 MacBook Pro 或 Mac Studio。不过考虑到它跑的是 284B 参数的模型……这要求反而显得挺良心的。
下载和运行非常简单:
# 下载 2-bit 量化模型(128GB 内存机型用这个)
./download_model.sh q2
# 编译
make
# 启动交互式对话(默认开启思考模式)
./ds4
# 启动 API 服务器
./ds4-server --ctx 100000 --kv-disk-dir /tmp/ds4-kv --kv-disk-space-mb 8192
然后你就可以用 curl 跟它对话了:
curl http://127.0.0.1:8000/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model":"deepseek-v4-flash",
"messages":[{"role":"user","content":"用一句话解释 Redis 的持久化机制"}],
"stream":true
}'
速度如何?antirez 放出了实测数据,老实说,有点猛:
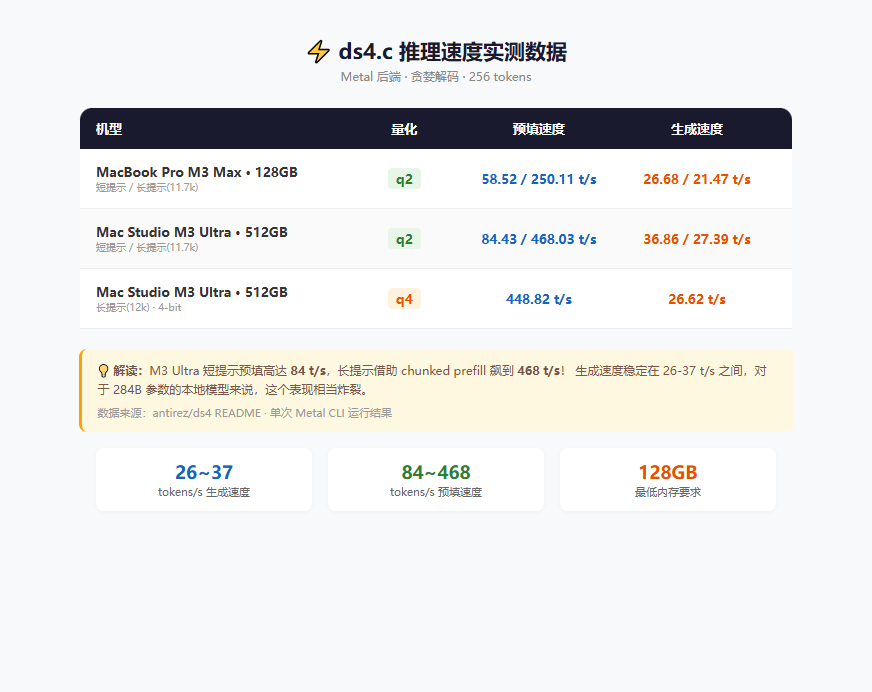
拿 M3 Ultra Mac Studio 来说,2-bit 量化下短提示的生成速度达到 36.86 tokens/s,预填速度更是高达 84.43 t/s。对于本地推理来说,这个速度已经可以用「流畅」来形容了。
有一说一,也有槽点
目前 ds4.c 还只是 alpha 质量。antirez 自己也说了这几点:
- 只支持 Metal,没有 CUDA 版本,N 卡用户暂时别想了
- 不支持多请求并发批处理,多个请求会排队
- 在 macOS 上跑 CPU 模式会触发苹果的虚拟内存 bug,导致内核崩溃
- 那个 MTP(推测解码)功能目前还只是个摆设,加速效果微乎其微
但怎么说呢……这个项目才发布 2 天。以 antirez 的更新速度,后面肯定会有大动作。
如果你对本地大模型部署感兴趣,我此前还整理过一篇《2025 年本地跑大模型方案横评》,关注公众号后回复「本地AI」获取。
觉得这项目有意思?完整代码在这里:
项目刚起步,才近 2000 Star,但以 antirez 的影响力,破万是早晚的事。
最后说句心里话。
一个写了 Redis 这种载入史册的项目的人,退休后又回来写 C 语言的推理引擎——不是因为他需要证明什么,而是因为他觉得「这事有意思」。
说实话,这块我也没完全搞懂……为什么一个数据库大神会对 AI 推理引擎这么上劲?但看他 README 里那句 "This software is developed with strong assistance from GPT 5.5 and with humans leading the ideas",我突然懂了:
他不是在写代码,而是在用代码探索 AI 的边界。
这才是真正的极客精神吧。
本文使用 MGO 编辑并发布
关注“何三笔记”,回复“mgo” 免费下载使用

