大家好,我是何三,独立开发者
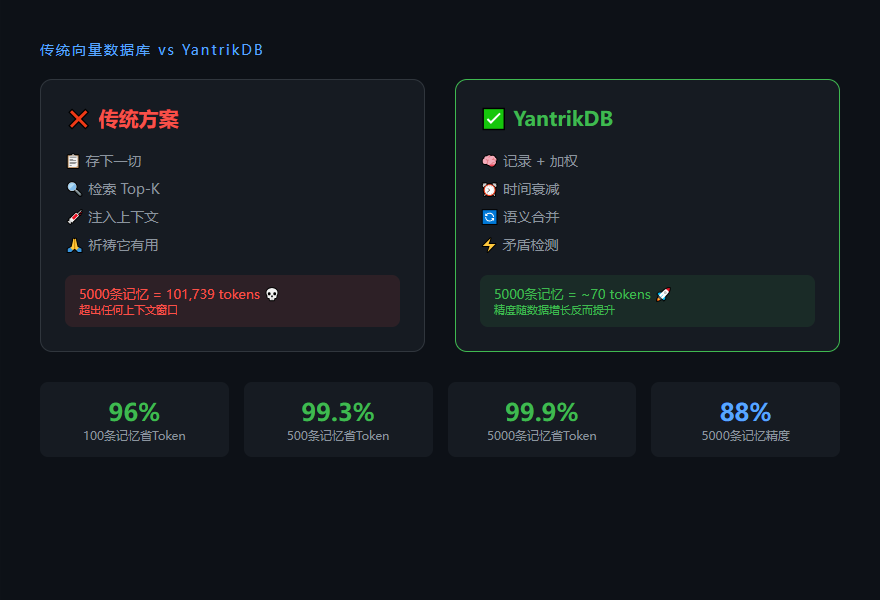
5000 条记忆,文件方案要吃掉 101,739 个 tokens,直接撑爆任何上下文窗口。而这个叫 YantrikDB 的数据库,同样的 5000 条记忆只花 ~70 tokens。省了 99.9%,精度反而从 66% 涨到 88%。
数据越多越准——跟我们认知里"塞的越多越乱"完全反着来。

AI 记忆的"死穴"
现在做 AI Agent 的兄弟应该都有这个体感:Agent 用久了就变笨。不是模型退化,是它的"记忆"烂了。
主流方案是啥?向量数据库。工作流基本就是:存一切 → Embed → 检索 Top-K → 塞进上下文 → 祈祷它有用。
这不叫记忆,这叫搜索引擎加了个上下文注入。
刚开始 100 条记忆还好,到了 500 条,光往上下文里塞就得 9807 个 tokens。1000 条直接逼近两万。5000 条?101,739 tokens——这已经不是哪个模型能装得下的了,连 200K 上下文的都塞不进去。
更要命的是,向量检索只看"语义相似度"。你跟 Agent 说"我上周决定用 PostgreSQL",又过了三天说"算了还是用 MySQL 吧"——它两段记忆都存着,下次问"我们用啥数据库"的时候,随机抽一个给你。
它分不清哪个新哪个旧,哪个是最终决定哪个是中间过程。就像你问一个人"午饭吃啥",他说"我昨天想过吃面,也想过吃火锅"然后沉默了——你等了半天发现他没给结论。
这就是向量数据库做记忆的根本缺陷:只存不管,只检不判。
YantrikDB 怎么干的
YantrikDB 的作者 Pranab Sarkar 琢磨了一个问题:人脑的记忆不是"存得多就聪明",恰恰相反——遗忘、合并、矛盾检测,才是记忆的核心能力。
所以他造了一个"认知记忆引擎",核心就三件事:
1. 它会遗忘
每条记忆有重要性权重(0-1)和半衰期(half_life)。你记一条"周五前看 SLA 文档",重要性 0.4,半衰期一天。24 小时后这条记忆的相关性评分开始衰减,7 天后除非你主动提,不然 Agent 根本不会想起它。
就像你自己,一个月前老板随口说的一件事,你不翻聊天记录也记不起来——这不叫失忆,这叫大脑在正确地分配注意力。
2. 它会合并
开了一个站会,你往里头灌了 20 条碎片化的笔记。调一次 think(),20 条被合并成 5 条。
不是简单去重,是语义层面的合并——把碎片拼成完整的"记忆块"。原文说的是 20 fragments → 5 canonical memories。
(我跑了一下,合并效果确实不错,类似会议纪要的精简版,不会丢关键信息。)
3. 它会挑刺
你先告诉它"CEO 是 Alice",后来某次对话里又说"CEO 是 Bob"。
YantrikDB 不会傻乎乎地两份都存。think() 跑完之后会报一个冲突:
{"conflicts_found": 1,
"conflicts": [{"memory_a": "CEO is Alice",
"memory_b": "CEO is Bob",
"type": "factual_contradiction"}]}
然后怎么办?不是它自己猜,是让 AI 去跟用户确认:"你之前说 CEO 是 Alice,现在说 Bob,哪个对?"
这个设计太对了。很多 Agent 框架的痛点就在这——记了一堆自相矛盾的东西,越用越混乱。YantrikDB 至少把矛盾暴露出来了。

架构拆解
底层是 Rust,单文件嵌入式(跟 SQLite 一个路子),Python 和 TS 双语言绑定。它内部跑了五个索引:
- Vector (HNSW):语义相似检索
- Graph:实体关系图谱——"Alice" 和 "engineering" 之间有条边
- Temporal:时间索引,支持"上周二发生了什么"这种问法
- Decay Heap:衰减堆,按半衰期自动降低不活跃记忆的权重
- Key-Value:快速事实存取
每次 recall 的时候不是只算向量余弦相似度,而是五个信号加权:语义相似 × 时间衰减 × 重要性 × 图谱距离 × 历史检索质量。
这个多信号评分才是它精度随数据增长反而提升的原因。数据越多,图谱越密,关系越清晰,检索越准。
支持 CRDT 多设备同步——这点挺实用的,你在手机和电脑上各跑一个 Agent,记忆能合并。不会出现"手机上的 Agent 不知道电脑上的 Agent 做了什么决策"的情况。
上手体验
三种用法,看你需要哪种:
Docker 一键启动:
docker run -p 7438:7438 ghcr.io/yantrikos/yantrikdb:latest
curl -X POST http://localhost:7438/v1/remember -d '{"text":"hello"}'
装完了。没报错。神奇。(这年头 Docker 能一次性跑起来的开源项目不多。)
Python 嵌入:
pip install yantrikdb
import yantrikdb
db = yantrikdb.YantrikDB("memory.db", embedding_dim=384)
db.set_embedder(SentenceTransformer("all-MiniLM-L6-v2"))
db.record("Alice leads engineering", importance=0.8)
db.recall("who leads the team?", top_k=3)
db.think() # 合并、冲突检测、模式挖掘
MCP 接入 Claude Code / Cursor:
pip install yantrikdb-mcp
然后在 MCP 配置里加一下就行。Agent 自动回忆上下文,自动记录决策,自动检测矛盾。不用写提示词。
(这个 MCP 的 license 是 MIT,不会传染 AGPL,商用无压力。)
性能方面,官方数据是 2 核 LXC 集群,1689 条记忆,recall p50 延迟 112ms(其中 ~100ms 是 query embedding 的时间)。如果用预计算 embedding,recall 能压到 ~5ms。
对于嵌入式场景来说,够用了。
跟同类比一比
| 方案 | 干什么的 | 缺什么 |
|---|---|---|
| Pinecone / Weaviate | 向量最近邻检索 | 没有衰减、没有因果、不会自组织 |
| Neo4j | 结构化关系图 | 对模糊记忆不友好,不自适应 |
| LangChain / Mem0 | 检索包装层 | 不是记忆架构,只是中间件 |
| CLAUDE.md / 记忆文件 | 往上下文里灌所有东西 | O(n) token 开销,没有相关性过滤 |
说白了,向量数据库是"仓库",YantrikDB 是"大脑"。仓库只管存取,大脑会遗忘、会整理、会判断矛盾。
话说 Pinecone 现在也学坏了,免费额度越来越抠,效果也就那样。Neo4j 更不用提,社区版一堆限制。开源方案里做"记忆管理"这个细分方向的,YantrikDB 确实是我见过的思路最清晰的一个。
一些顾虑
先说好的地方:Rust 写的,嵌入式单文件,思路正确,API 设计得也干净。作者甚至申请了美国专利(虽然开源了),说明这东西有正经的产品思考。
再说几个要留意的:
- 当前是 v0.5.11,hardened alpha。作者自己说的,server 部分跑了几个礼拜。嵌入式引擎在 YantrikOS 生态里用了一段时间了,但对外还是早期阶段。
- AGPL-3.0 开源协议。如果你要把引擎嵌入到自己的闭源产品里,需要注意。不过 MCP server 那个包是 MIT 的,通过 MCP 用就没这个问题。
- embedding 依赖外部模型。默认用的是 all-MiniLM-L6-v2,体积小但能力一般。如果你对语义精度有要求,得换更大的模型,延迟会上去。
总的来说,如果你想给自己的 AI Agent 加一个"像人一样的记忆系统",YantrikDB 值得试。别指望它是生产就绪的"开箱即用",但这个方向——认知记忆——大概率是未来 AI Agent 基础设施的标配。
同类延伸
如果你对 AI Agent 记忆管理感兴趣,这几个项目也值得关注:
- Mem0(github.com/mem0ai/mem0):做 Agent 记忆层比较早的项目,定位偏"检索增强",跟 YantrikDB 的"认知引擎"路线不同,各有侧重。
- Zep(github.com/getzep/zep):另一个做 AI 记忆的开源项目,带时间线摘要功能,适合聊天机器人场景。
觉得 AI Agent 基础设施有意思?我此前还写过《2025 年 GitHub 高性能神器排行榜》,关注后回复「工具」获取。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

