大家好,我是何三,独立开发者
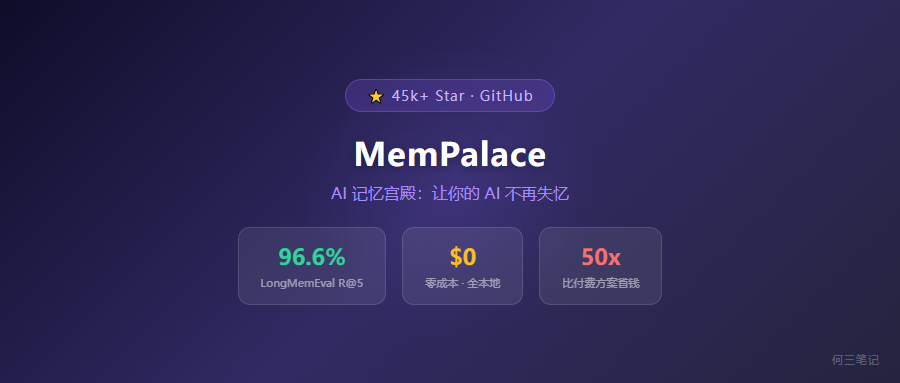
$507/年 vs $10/年。
50 倍的差距。就差在"给 AI 加个记忆"这件事上。
你有没有算过,你跟 AI 聊了多久了?我算了一下,从去年开始重度用 Claude Code 到现在,差不多 6 个月。每天 3-4 小时的对话量,累计大概 1950 万 token。
这些对话里,每一个架构决策、每一次 debug 的过程、每一场"为什么选 Postgres 而不是 MongoDB"的争论——全都在会话结束的那一刻,蒸发了。
你换一个新会话,AI 像个失忆症患者,之前聊过什么一概不知。得从头介绍项目背景、技术栈、甚至你个人写代码的习惯。
这种感觉,就像跟一个每天失忆的同事协作。能力很强,但每次见面都得重新做自我介绍。
有人给这个问题算了笔账
MemPalace 的 README 里有个对比表,我看完愣了一下:
| 方案 | 每年成本 |
|---|---|
| 把所有对话粘贴进去 | 不现实,19.5M token 塞不进上下文 |
| 用 LLM 做摘要 | ~$507/年 |
| MemPalace wake-up | ~$0.70/年 |
| MemPalace + 5 次搜索 | ~$10/年 |
说白了,AI 记忆这件事,不该花这么多钱。
而市面上现有的"AI 记忆"产品——Mem0、Zep、Letta——都在收月费。最便宜的 Mem0 也要 $19/月,Zep $25/月起,Letta 直接干到 $20-200/月。
MemPalace 全部免费,全部本地,零数据上传。
GitHub 上线 10 天,4.5 万 Star(近 5 万)。(我写到这的时候还在涨)
它怎么做到的?
名字就泄露了原理——MemPalace,记忆宫殿。
古希腊演说家 memorize 整篇演讲稿的方法:把要记的内容放进一栋想象中的建筑的各个房间里。走到哪个房间,就想起那个知识点。
说实话第一次看到这个命名的时候,我以为是个装修类项目。点进去才发现是给 AI 做记忆的。(那个瞬间挺离谱的。)
MemPalace 把这个概念搬到了 AI 记忆系统上:
- Wing(翼):一个项目或一个人就是一栋翼
- Room(房间):翼里面的具体话题,比如"auth 迁移"、"GraphQL 切换"
- Hall(走廊):连接同一翼内的房间,分为 facts(决定)、events(事件)、discoveries(发现)、preferences(偏好)、advice(建议)五类
- Tunnel(隧道):连接不同翼的同一个房间——比如你和同事张三都有个"auth 迁移"房间,隧道会把两边的记忆串起来
底下是 ChromaDB 做语义搜索,SQLite 做知识图谱。没有 Neo4j,没有云端,你电脑上跑就行。话说隔壁 Notion 的 AI 也开始搞本地化了,大厂终于知道隐私这事儿用户在意的。
有一说一,这个架构确实优雅。但实测数据摆在那里:
全量搜索:60.9% R@10
按翼搜索:73.1% R@10
翼+走廊:84.8% R@10
翼+房间:94.8% R@10
结构不是摆设,是真的在提升检索准确率。
最狠的是 $0,还不用 API
LongMemEval 是 AI 记忆系统的标准 benchmark。MemPalace 跑出了 96.6% R@5。
这是什么概念?比 Mastra(94.87%,但需要调 GPT API)高,比 Mem0(~85%,$19-249/月)高,比 Zep(~85%,$25+/月)高。
而且 MemPalace 这个分数是 raw 模式——不调任何 LLM API,纯 ChromaDB 语义搜索。零 API 调用,零成本。
有人在 HN 上独立复现了这个结果,在 M2 Ultra 上跑了不到 5 分钟。(Issue #39,感兴趣的可以自己去看)
用 HN 评论里一位开发者的话说:"We still think there's a real product here, just not the one the README is selling."
翻译一下:东西确实好用,但 README 吹过头了。
聊聊那个争议
说到 README 吹过头这件事,得展开讲讲。
MemPalace 上线 48 小时内,HN 上就被扒了好几个问题:
- AAAK 压缩语言的 token 计数是错的——作者用了
len(text)//3这种粗略估算,而不是真正的 tokenizer。实际算下来,AAAK 在小文本上反而比原文还长 - "30 倍无损压缩"是虚假宣传——AAAK 是有损的,而且 benchmark 上分数从 96.6% 降到了 84.2%
- "+34% palace boost"有点误导——本质就是 ChromaDB 的元数据过滤,不算什么创新
创始人 Ben Sigman(对,不是那个演电影的 Milla Jovovich,README 里写错了)48 小时内发了一封公开信,逐条认错,态度相当坦诚:
"Brutal honest criticism is exactly what makes open source work. We're listening, we're fixing, and we'd rather be right than impressive."
翻译:被喷就认,该修就修。宁可做对了,也不装厉害。
这种态度,在开源社区其实挺难得的。(说到这里突然想起来,某些拿了融资的项目 PR 翻车了之后可没这么痛快认)
另外还有个离谱的事:有人开始仿冒 MemPalace 官网,甚至投放恶意软件。作者不得不专门发公告说"我们没有官网,任何声称是官网的都是假的"。
项目火了之后果然啥事都有。
实际怎么用?
我试了一下,核心就三步:
pip install mempalace
# 初始化你的记忆世界
mempalace init ~/projects/myapp
# 挖掘你的对话历史
mempalace mine ~/chats/ --mode convos
# 搜索
mempalace search "why did we switch to GraphQL"
支持 Claude Code、ChatGPT、Slack 的对话导出。三种挖掘模式:项目文件(代码和文档)、对话(convos)、通用(自动分类成决定、偏好、里程碑、问题、情感上下文)。
如果用 Claude Code,装起来更简单:
claude plugin marketplace add milla-jovovich/mempalace
claude plugin install --scope user mempalace
重启 Claude Code,AI 就自动有记忆了。29 个 MCP 工具可以直接调,你问"上个月我们关于 auth 做了什么决定",Claude 自动调 mempalace_search 返回原话给你。
不用手动敲命令,AI 自己会用。
装完了。没报错。神奇。
对了,它还支持本地模型。两种用法:mempalace wake-up 把关键信息灌进 system prompt,或者 mempalace search 按需查。全离线,Llama、Mistral 都行。
几个有意思的功能
知识图谱——时间感知的实体关系三元组,用 SQLite 实现。可以查"2026 年 1 月张三在做什么",带时间窗口的。比 Zep 的 Graphiti(Neo4j 云端)轻量太多。
Specialist Agents——可以给不同的 AI Agent 分配不同的"翼"和日记。比如 reviewer agent 只记 bug 模式,architect agent 只记设计决策。Letta 收 $20-200/月干这事,MemPalace 一个翼搞定。
矛盾检测——能发现记忆冲突。比如你之前说"张三负责 auth 迁移",后来又说"李四负责 auth 迁移",它会标红告诉你有矛盾。(目前还是实验性的,没完全接入知识图谱,作者在修)
同类工具推荐
如果你对 AI 记忆这个方向感兴趣,我还推荐看看这几个:
- Mem0:最成熟的 AI 记忆方案之一,有 SaaS 也有自部署,功能更全但收费。适合对隐私不那么敏感、想要开箱即用的团队
- Rekal:HN 上近期热帖,把 LLM 长期记忆塞进一个 SQLite 文件里,极简方案。和 MemPalace 的"记一切"理念相反,走的是精炼路线
- Lodestar:MemPalace HN 讨论帖里提到的竞品思路——不存原始对话,只存"决策层"。把每轮对话结束时 AI 认为重要的东西,精炼成 markdown 提交到代码仓库。
git clone就带走了全部上下文
这几条路各有取舍:MemPalace 走"全量存储+结构化检索",Rekal 走"单文件极简",Lodestar 走"精炼+代码仓库绑定"。
适合自己的才是最好的。
值不值得装?
核心功能——本地存储、语义搜索、免费——是实打实的。96.6% 的 benchmark 有独立复现,$0 成本不是噱头,Claude Code 集成确实好用。
AAAK 压缩语言目前确实拉胯,但作者说得很清楚,96.6% 是 raw 模式的分数,AAAK 是实验功能。存储默认就是原始文本,不丢信息。
如果你是重度 AI 编程用户(每天 2 小时以上的 Claude/Cursor/ChatGPT 对话),这东西值得装。免费的,又不用上传数据,试一下的成本几乎为零。
偶尔用用 AI 的,感知可能不明显。得先积累足够多的对话,记忆宫殿才有东西可搜。
行了不说了,搬砖去了。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

