大家好,我是何三,独立开发者
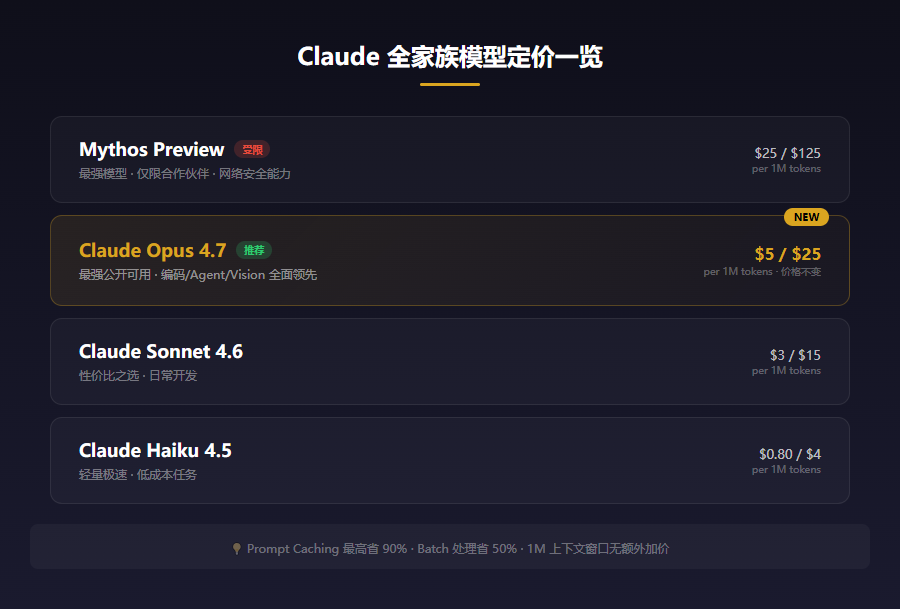
Anthropic 刚放了个大活——Claude Opus 4.7 正式发布。
编码能力暴涨 13%,生产环境 bug 修复能力翻了 3 倍,视觉精度从 54.5% 直接飙到 98.5%。最离谱的是价格一分没涨,还是 $5/$25 per 1M tokens。
六个月内第四个 Opus 版本了(4.1 → 4.5 → 4.6 → 4.7),Anthropic 这迭代速度,OpenAI 看了估计失眠。

这 13% 的编码提升意味着什么?
先说数据。
在 Anthropic 内部的 93-task 编码基准测试里,Opus 4.7 比上一代多解决了 13% 的任务。其中有 4 个任务,连 Sonnet 4.6 都搞不定,Opus 4.7 拿下了。
Rakuten-SWE-Bench 上更夸张——3 倍的生产环境任务解决率。啥概念?就是之前你丢给 Claude 一个线上 bug,它可能给你修一半然后摆烂。现在它能老老实实从定位到修复到自验证一口气干完。
Cursor 的 CEO Michael Truell 也说了,Opus 4.7 在 CursorBench 上直接从 58% 跳到 70%,是个"有意义的飞跃"。
还有个特别有意思的案例:Opus 4.7 自主从零构建了一个 Rust 文本转语音引擎——神经模型、SIMD 内核、浏览器 demo 全自己搞的,然后还把自己的输出喂给语音识别器验证结果对不对。
几个月的高级工程师工作量,它自己干完了。代码库还开源了。
(我看完这个案例沉默了三秒。不是因为震撼,是因为想到了自己的简历。)

视觉精度翻了 4 倍,这才叫"看见"
Opus 4.7 之前,Claude 的最大图像分辨率是 1,568px(约 1.15 兆像素)。现在直接拉到 2,576px(约 3.75 兆像素),三倍多的视觉容量。
视觉精度从 54.5% 干到 98.5%——这意味着什么?
之前 Claude 看屏幕截图,就像近视 300 度不戴眼镜。现在它戴上了。
坐标映射终于 1:1 了,不用再搞什么缩放比例的换算。文档里的小字、PPT 里的表格、架构图里的细线,现在都能正常识别。
这对 Computer Use(让 AI 操作电脑)场景的影响是根本性的。XBOW 的 CEO 说"我们最大的 Opus 痛点直接消失了"。
话说国内搞 RPA 的公司是不是该紧张一下了。
API 有几个大坑,迁移注意
Opus 4.7 不是无缝升级,API 层面有几个 breaking changes,不注意的话你的调用直接 400 报错:
1. Extended Thinking 被干掉了
以前你能手动设置 budget_tokens,现在不行了。只支持 adaptive thinking(自适应思考)。想开的话:thinking: {"type": "adaptive"}。
2. Temperature / top_p / top_k 全废了
设了非默认值直接报错。Anthropic 的意思是:别调参了,用 prompt 控制。
(说实话这个改动有点激进。习惯了调 temperature 的开发者估计要骂街。)
3. 新 tokenizer,token 用量可能多 35%
同样的文本输入,token 数会从 1.0x 到 1.35x 不等。效果更好,但成本可能上浮。如果你的 max_tokens 设得比较死,记得留余量。
4. 新增 xhigh 努力等级
介于 high 和 max 之间。Anthropic 建议编码和 Agent 场景从 xhigh 开始。
还有个新功能叫 Task Budgets(公测中),可以给整个 Agent 循环设一个大概的 token 预算。模型能看到倒计时,自己会优化分配。不过这个不是硬限制,只是建议性的。
Claude Code 的 /ultrareview 值得一试
如果你用 Claude Code,Opus 4.7 已经是默认模型了。
Anthropic 新加了个 /ultrareview 命令,专门做深度 code review。它会通读所有变更,标记出细心审查者才能发现的 bug 和设计问题。
Pro 和 Max 用户免费送三次试用。
CodeRabbit 的 VP 说 Opus 4.7 的 recall 提升了 10% 以上,"能发现最难检测的 bug"。这玩意用好了,code review 的效率确实能上一个台阶。
还有 Auto Mode 扩展到了 Max 用户——Claude 可以自己做决策,不用你一步步确认。适合跑那些长时间无人值守的任务。
Mythos:那个你用不了的怪物
这次发布有个有趣的背景。
Opus 4.7 虽然很强,但 Anthropic 坦言它不如 Mythos Preview。Mythos 是他们最强的模型,但因为有网络安全方面的风险(能找到和利用软件漏洞,水平堪比资深安全研究员),目前只开放给 Apple、Google、Microsoft 等平台合作伙伴。
Opus 4.7 其实是 Mythos 安全护栏的"试验田"。Anthropic 在 Opus 4.7 上部署了实时网络安全审查——检测到高风险网络请求会自动拒绝。
安全研究人员如果需要使用,可以申请他们的 Cyber Verification Program。
所以目前的情况是:最强的模型你用不了,你能用的最强模型加了安全锁。这格局,有点意思。
怎么用上 Opus 4.7?
官方渠道就不多说了,API、Bedrock、Vertex AI、Foundry 都支持。
但如果你是个人开发者,想低成本体验 Opus 4.7(包括其他顶级模型),可以看看中转方案。
我用的是 Unity2 这个 API 中转平台,GPT-4o、Claude Opus 4.7、Gemini 这些主流模型都有,价格比官方直接订阅友好得多。关键是国内网络直连,不用折腾代理。
👉 注册地址:https://unity2.ai/register?ref=aWrXutTo
注册后有免费额度可以试,上手零成本。API 格式完全兼容 OpenAI 的,改个 base_url 就行。如果你本来就在用各种 AI 模型写代码,中转平台确实省心不少。
写在最后
Opus 4.7 不是什么颠覆性的更新,但它是 Anthropic 六个月来最扎实的迭代。编码、视觉、指令遵循、长程 Agent 能力,每一项都有实质进步。
价格没变,上下文窗口还是 1M tokens,这些都没缩水。
对开发者来说,最大的变化是 API 层面的 breaking changes 和新 tokenizer。迁移前务必测试一下你的 prompt 和 token 用量。
关注"何三笔记",回复「Claude」获取 Claude 全系列模型使用指南与对比分析
⚡ 快速上手清单
| 项目 | 说明 |
|---|---|
| API 模型名 | claude-opus-4-7 |
| 价格 | $5 / $25 per 1M tokens(与 4.6 一致) |
| 上下文窗口 | 1M tokens |
| 最大输出 | 128K tokens |
| 推荐努力等级 | coding/agent 用 xhigh 或 high |
| Thinking 模式 | adaptive only |
| 国内访问 | 推荐中转:Unity2 |
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

