大家好,我是何三,独立开发者
101 毫秒能干什么?眨个眼都不够。
但 forkd 能用 101ms 同时启动 100 个 KVM 隔离的微VM,每个子 VM 只占 0.12 MiB 的增量内存。
大白话来讲——你给它一个提前暖好的 Python 环境(比如已经 import 了 numpy、torch),它能在 0.1 秒内变出 100 个完全隔离的虚拟机,每个都有独立的内核、网络栈、文件系统,而且共享父 VM 的内存。
这个项目叫 forkd,Rust 写的,刚在 GitHub 上冒出来不到一个月,Star 已经快破 3k 了。
你问我凭什么?因为它把 Linux 的 fork()——对,就是那个进程创建的系统调用——搬到了虚拟机层。
这玩意儿解决什么问题?
做过 AI Agent 的应该都懂:你想让 LLM 写代码、跑脚本、执行工具调用,就得给每个任务开一个沙箱。用 Docker?启动一个容器 335 秒(跑 100 个)。用 gVisor?289 秒。Firecracker 冷启动?759 毫秒——那是只跑 1 个。
更离谱的是,每次新开一个沙箱,都得重新 import 一遍 numpy、torch、scikit-learn……这些东西动辄几百 MB,IO 都快被吃干净了。
我之前写过一篇 CubeSandbox 的文章,腾讯那个基于 RustVMM 的微VM方案,已经算快的了。但 forkd 的 benchmark 直接把 CubeSandbox 拉出来比了:

| 方案 | 100个沙箱耗时 | 每沙箱增量内存 |
|---|---|---|
| forkd | 101 ms | 0.12 MiB |
| CubeSandbox | 1.06 s | 5 MiB |
| Firecracker 冷启动 | 759 ms | 84 MiB |
| Docker (runc) | 335.3 s | 4 MiB |
| gVisor (runsc) | 288.6 s | — |
说实话,第一次看到这个数字我是怀疑的——100 个微VM 在 101ms 内?每个只多占 0.12 MiB?这也太离谱了。
但原理其实很优雅。
原理:像进程 fork() 一样 fork 虚拟机
你在 Linux 里学过 fork() 吧?父进程调一下 fork(),子进程就出来了,子进程共享父进程的地址空间,直到有一方要写数据——这时候内核触发 copy-on-write(写时复制),把那页内存拷贝一份。
forkd 干的事一模一样,只不过把"进程"换成了"微VM"。
工作流程大概是这样的:
- 父 VM 启动一次,把 Python、numpy 等所有依赖全部 import 好
- 暂停父 VM,把它的内存快照保存到磁盘
- 要创建子 VM 时,所有子进程
mmap这个快照文件,加上MAP_PRIVATE标志 - 内核自动管理写时复制——子 VM 读的时候共享父 VM 的内存,写的时候才自己拷贝
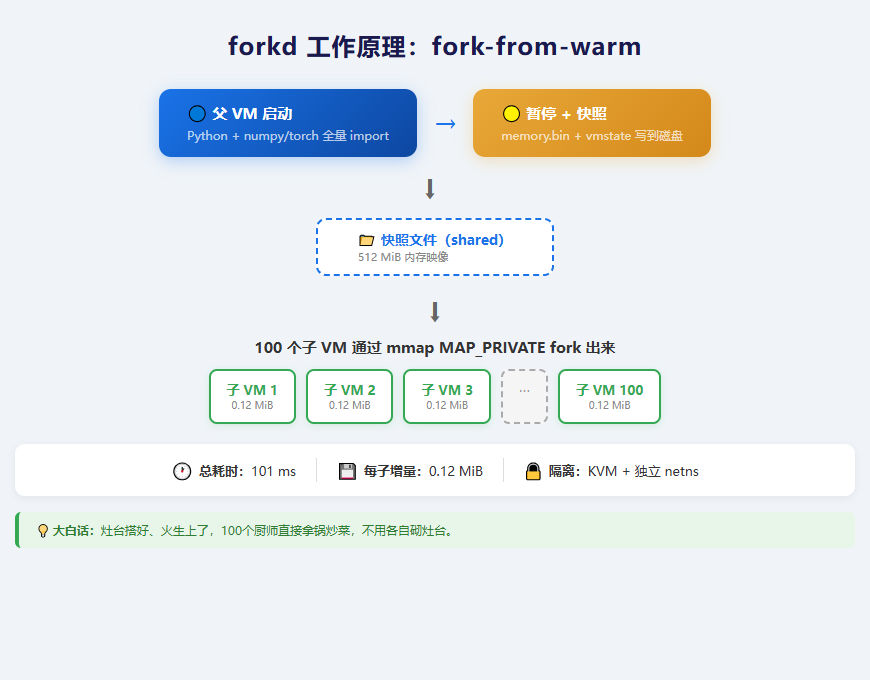
就这么简单。
说起来,看到这个设计我突然想到大学时学操作系统,老师讲 fork() 的时候说"这是 UNIX 最优雅的设计之一"。当时没太大感觉,觉得不就是复制进程吗?后来自己写了个 fork bomb 把服务器搞挂了一次才明白——一个系统调用能同时做到"创建"和"共享",本身就是天才设计。forkd 相当于把这个天才设计又升华了一层。
说实话,微VM 里 vCPU 状态管理和内存快照的序列化细节我也没完全搞懂,但核心思路我是看明白了——把 CoW 用到极致。
说白了,传统方案是每个沙箱从零开始冷启动一个操作系统——相当于每次做饭都要先砌个灶台。forkd 是灶台已经搭好了、火都生上了,你拿个锅过来直接用就行。
所以 forkd 跑 100 个隔离沙箱,启动耗时 = 父 VM 的一次冷启动 + 99 次近乎零成本的 fork。0.12 MiB 的增量内存就是那点写时复制产生的脏页。
而且它还支持 BRANCH——运行中的沙箱也能随时"分身"。Agent 正在跑一个 ReAct 循环,跑到一半你觉得需要探索多个分支,直接 BRANCH 一下,150ms 内就能 fork 出几个子 VM,每个继承之前的推理状态,然后各自走不同的方向。
这个功能,怎么说呢,就是……就是那种"知道它能做到,但真看到它跑起来还是会被吓到"的程度。
等等,这东西跟 CubeSandbox 什么关系?
好问题。
CubeSandbox 也是微VM 沙箱,也是 Rust 写的,也是走 KVM 隔离。两者的核心区别就一个:
-
CubeSandbox:池化预热。提前创建一批微VM 放在池子里,用的时候从池里取。快的场景确实快(单实例 <60ms),但池子的管理和预热成本在那儿。
-
forkd:fork-from-warm。不池化,而是用 CoW 快照的方式,一个父 VM 暖好了,所有子 VM "fork"出去,天然共享内存。
所以你看到 benchmark 里 forkd 在 N=100 时比 CubeSandbox 快 10 倍——差异主要来自:CubeSandbox 每个子 VM 仍然需要分配自己的 5 MiB 增量内存(虽然也不大),而 forkd 的 CoW 机制让增量小到离谱。
但 forkd 自己也承认,纯冷启动场景下 CubeSandbox 更快(<60ms 单实例)。两者各有适用场景。
上手体验
装起来其实挺简单的。Ubuntu 22.04+ 上几条命令就能跑起来:
# 下载二进制(不需要 Rust 工具链)
curl -sSL https://github.com/deeplethe/forkd/releases/download/v0.3.4/forkd-v0.3.4-x86_64-linux.tar.gz \
| sudo tar -xz -C /usr/local/bin/
# 一次性环境配置
sudo bash scripts/setup-host.sh
sudo bash scripts/netns-setup.sh 3
# 检查环境
forkd doctor
然后拉一个预热好的快照包,直接 fork:
# 14.5 MiB 的 Python 3.12 + LangGraph 快照
forkd pull deeplethe/langgraph-react
# 3 个子 VM,每个 ~10ms 启动
sudo -E forkd fork --tag langgraph -n 3 --per-child-netns
如果你想从 Docker 镜像自己构建,也行:
sudo -E forkd from-image python:3.12-slim \
--tag py-numpy \
--extra python3-numpy
sudo -E forkd fork --tag py-numpy -n 5 --per-child-netns
Python SDK 用起来跟 E2B 的 API 几乎一样,可以无痛迁移:
from forkd import Sandbox
with Sandbox() as sb:
print(sb.commands.run("uname -a").stdout)
print(sb.eval("numpy.zeros(5).tolist()")) # 复用预热好的 PID 1
说起来,微VM 沙箱这个赛道最近半年真是挤爆了:
- CubeSandbox:腾讯开源,RustVMM 微VM,池化方案
- BoxLite:跨平台(macOS via Hypervisor.framework),可嵌入、无守护进程
- E2B:基于 Firecracker 的云端沙箱(开源但 infra 层闭源)
- Modal:闭源,跟 forkd 最像(也是 snapshot fork),但托管在云端
如果你对这类沙箱技术感兴趣,我前面写的 CubeSandbox 那篇文章可以去翻翻——对比着看更有意思。
GitHub 地址
项目在这里:github.com/deeplethe/forkd
Apache 2.0 协议,目前是 Alpha 阶段,API 还在迭代。但核心功能已经能用了——Python SDK、TypeScript SDK、REST API、MCP Server 都齐了。
总结
从 335 秒到 0.1 秒,从上百 MiB 到 0.12 MiB。
forkd 没发明什么新技术,就是把操作系统里已经存在了 50 年的 fork() + CoW 组合拳,巧妙地套用到了虚拟机层。大道至简。
适合什么人用?AI Agent 开发者、Code Interpreter 场景、SWE-bench 式的并行评测、需要在隔离环境里跑 CI 的团队——只要你有"高频创建隔离沙箱"的需求,forkd 值得试试。
不过目前 Alpha 阶段,生产环境慎用。等它出 1.0 再说也不迟。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

