大家好,我是何三,独立开发者
如果你跑过 LLM 推理,大概率被一个问题折磨过——长上下文的响应速度,慢到令人发指。
聊个天,前面说过的话模型得重新"读一遍";喂个文档进去,首 Token 生成时间(TTFT)直接飙到十几秒。
传统方案是怎么解决的?堆显存、堆 GPU、上昂贵的推理集群。
但有个开源项目不这么干。它叫 LMCache,思路很直接——把重复计算的中间结果存起来,下次直接用。
就这么一个简单的想法,效果却炸裂:
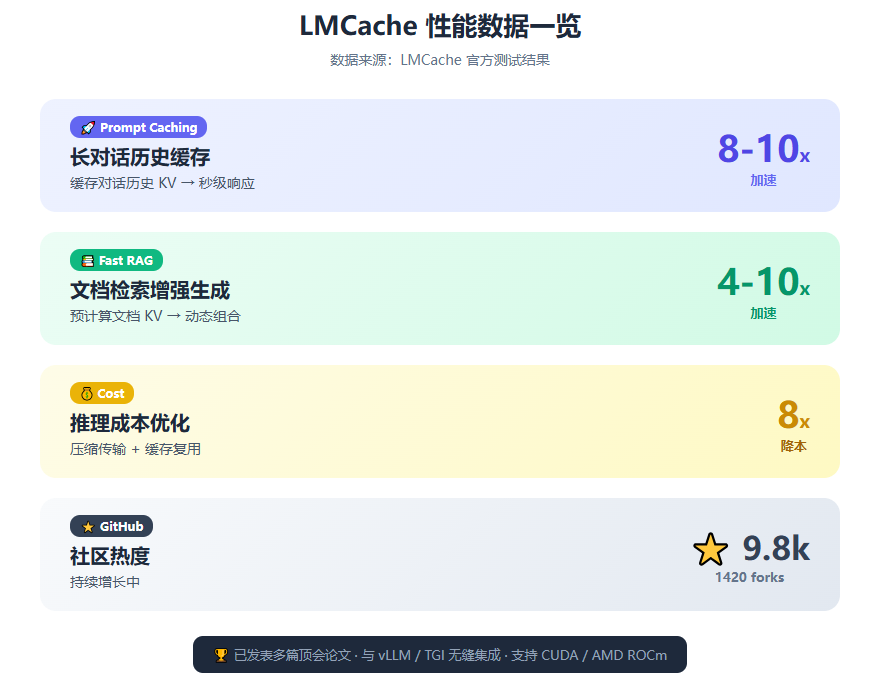
LLM 推理加速最高 8 倍,成本同步降低 8 倍。
快 8 倍的同时还省 8 倍的钱,说实话,这种数据我第一次看到的时候,第一反应是——是不是算错了?
LMCache,GitHub 上已经近 1 万 Star 了(精确数字是 9.8k),由芝加哥大学等机构的研究者发起,背后有 CacheGen、CacheBlend 等顶会论文支撑。
项目地址:https://github.com/LMCache/LMCache
KV Cache 到底是个啥
先说个背景知识,不然你没法理解 LMCache 为什么牛。
大模型生成回答的时候,每生成一个新 Token,都得回顾一下前面说过的话——也就是历史上下文。这个"历史上下文"在模型内部的表现形式,就是 KV Cache(键值缓存)。
相当于 ChatGPT 跟你聊天时,脑子里一直贴着一张小抄,上面记着刚才聊了啥。
问题出在哪呢?
每次对话越长,这张小抄就越大。128K 上下文的小抄,光存储就要占好几个 GB 的显存。而且不同会话之间,这张小抄没法复用,每个新请求都得重新算一遍。
说白了就是——同一段话,模型看一次算一次,看十次算十次,CPU 都冒烟了它还在算。
LMCache 的思路特别朴素:你把算过的 KV Cache 存到一个"共享缓存层"里,下次再有人问同样的问题,直接从缓存里拿就行,不用重新算。
这就好比你去图书馆借书,以前每次借都要从头翻索引查位置。现在有人把索引抄好贴门口了,你进门直接拿——时间省了,人也轻松了。

LMCache 到底做了什么
说起来简单,实现起来可不容易。
LMCache 做的事情可以拆成三层:
第一层:缓存管理。 把 GPU 显存里算好的 KV Cache 存到 CPU 内存甚至 SSD 上。显存不够用了?自动把不常用的缓存"挪"到内存里,腾出显存给新请求。
第二层:压缩传输。 KV Cache 这玩意儿体积特别大,纯传的话网络带宽扛不住。LMCache 用了他们论文里提出的压缩算法,在几乎不掉精度的情况下把数据体积压到原来的几分之一。
第三层:跨实例共享。 这是最骚的——你跑多个 vLLM 实例,它们之间可以共享 KV Cache。第一个实例算过的内容,第二个实例不用重算,直接拿来用。
原理大概是这样,具体实现细节可能有出入——有懂的大佬欢迎指正。我也只是看了论文和源码大概理解了一层皮毛。
两种杀手级场景
LMCache 官网展示了两个典型的应用场景,每个都挺震撼的。
1. Prompt Caching(提示词缓存)
AI 聊天机器人和文档处理工具,用户的历史对话往往很长。每次新请求都要重新处理整个对话历史。
LMCache 的做法是:把长对话历史的 KV Cache 存起来,下次直接复用。
官方数据显示:响应速度提升 8-10 倍。
2. Fast RAG(快速检索增强生成)
RAG 是现在企业级 AI 应用的主流方案。传统做法是每次查询都要把所有相关文档片段重新编码一遍。
LMCache 把这些文档片段的 KV Cache 预计算好存起来,查询时动态组合。
结果显示:速度提升 4-10 倍。
上手体验:真的只需要两行命令
我一开始以为这种级别的优化,配置起来肯定很复杂。
结果看了一眼他们的 Demo,有点意外。
# 拉取镜像
docker pull apostacyh/vllm:lmcache-0.1.0
# 启动 vLLM + LMCache
docker run --runtime nvidia --gpus '"device=0"' \
-v /root/.cache/huggingface:/root/.cache/huggingface \
-p 8000:8000 \
apostacyh/vllm:lmcache-0.1.0 \
--model mistralai/Mistral-7B-Instruct-v0.2 \
--lmcache-config-file /lmcache/LMCache/examples/example-local.yaml
就这?是的,就这。
拉个镜像,跑个容器,LMCache 就已经集成到 vLLM 里了。后面随便用 OpenAI 兼容的客户端请求就行。
还有一个更骚的玩法——跨实例 KV 缓存共享。
在你的服务器上跑两个 vLLM 实例,分别监听 8000 和 8001 端口,同时连接同一个 LMCache 后端。第一个实例处理过长上下文的请求后,第二个实例再处理类似请求时,延迟直接断崖式下降。
为什么这么设计?别问我,问作者去。 我觉得这么做最实际的价值是——你做推理负载均衡的时候,不用再费心把相同上下文的请求路由到同一台机器上了。
在 LLM 推理加速这个方向上,还有一些值得关注的项目:
- vLLM:LMCache 的最佳搭档,本身就是目前最流行的 LLM 推理引擎之一,PagedAttention 解决了显存碎片化的问题
- LLM-Kit / Ollama:本地跑模型的方案,如果结合 LMCache 的长上下文缓存能力,体验会好很多
如果你对这类基础设施层优化的项目感兴趣,我此前还整理过《2026 年 GitHub 高性能神器排行榜》,关注后回复「工具」获取。
最后说两句
说实话,我写这篇文章的时候,LMCache 的 Star 数还在涨。从最初的几千到现在的近 1 万,增长势头非常猛。
这东西解决的是一个真实到不能再真实的痛点——LLM 太贵、太慢。不是所有人都有财力堆 A100 集群的,但一个好的缓存层设计,能让普通硬件跑出接近集群的效果。
如果你的业务依赖长上下文 LLM 推理——比如文档问答、代码分析、客服对话——LMCache 值得你花一个下午的时间跑一遍 Demo。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

