大家好,我是何三,独立开发者
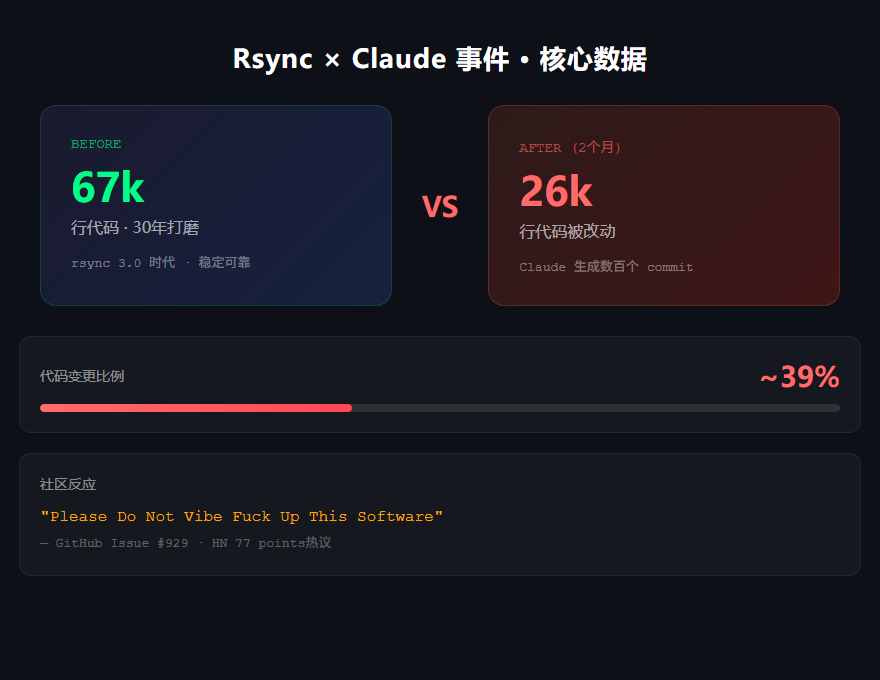
67k 行 C 代码,30 年打磨,2 个月被 Claude 改了 26k 行。
这不是什么 AI 创业公司的 PR 稿。这是上周真实发生在开源社区的事。rsync——那个你部署脚本里大概率躺着的文件同步工具——它的 3.4.3 版本被发现混入了数百个 Claude 生成的 commit。GitHub Issue #929 的标题直接开喷:"Please Do Not Vibe Fuck Up This Software"。
Hacker News 上 77 points,评论区直接炸了。
有人当场写了替代品 OpenRsync。有人翻出了 rsync 的 commit 历史,发现 2 个月内将近 40% 的代码被动过。有人冷静分析说"大部分只是测试用例",但更多人只问了一句:一个跑在无数生产环境里的 30 岁工具,凭什么让 AI 来动它的核心逻辑?
这事有意思的地方在于——它不是又一个"AI 取代程序员"的爽文。恰恰相反,这是一个30 岁的工具反过来教 AI 做人的故事。
rsync 到底是个什么玩意儿
简单说,rsync 就是文件同步界的瑞士军刀。
你要把文件从 A 拷贝到 B,本地也好,远程也好,几十 GB 也好,几百万个小文件也好,一条命令搞定。它最牛的地方是增量传输——只传变化的部分,不是每次全量拷贝。
打个比方:
你有一本 1000 页的书要抄给朋友。一般人做的事:把整本书重抄一遍寄过去。rsync 做的事:看看你朋友手上那本跟你这本差在哪几页,只把那几页寄过去。
这个算法叫 rsync 算法,1996 年由 Andrew Tridgell 和 Paul Mackerras 发明。30 年了,几乎没人能提出更好的替代方案。
它的参数也很经典:
# 本地增量同步
rsync -avh ./project/ /backup/project/
# 远程同步(走 SSH)
rsync -avz --progress ./data/ user@server:/data/
# 增量备份,保留硬链接
rsync -avh --delete --link-dest=../backup-yesterday ./source/ ./backup-today/
说实话,这玩意儿我用了十年,参数也就记熟了这四五条。但它就是稳。
然后就出事了
今年 5 月,有人发现 rsync 的 GitHub 仓库不太对劲。
commit 历史里突然冒出来大量署名 "Claude" 的提交。就是 Anthropic 那个 Claude。2 个月,26k 行代码变动——而 rsync 全部代码量不过 67k 行。
想想看,一个你用了十年的工具,它的核心维护者突然开始用 AI 批量改代码。而且改的不只是测试用例和文档——有些 commit 直接改了 C 语言里的行为逻辑。
有人翻出一个具体 commit:把某个"安全"的 C 操作换成了另一种写法,结果触发了内存损坏的 bug。
维护者可能觉得:这些都是小修小补,AI 生成的代码我再 review 一遍就行。
但问题是——C 语言的内存安全不是靠 review 能保证的。这东西,说不好听点,改一行可能炸一片。
HN 评论区有人说得特别狠:
"26k code changes in 2 months... rsync was 67k LOC."
26k / 67k = 约 39%。两个月,你告诉我一个 30 年的项目,将近一半代码被 AI 动过,你敢在生产环境升级吗?
我不敢。
跑题一下——说到 C 语言的内存安全
我突然想起一件事。
前阵子有个朋友跟我争论,说 Rust 是不是 C 的终极替代品。我说不一定,C 在系统工具层的地位短期内很难被取代——你看看 OpenSSL、rsync、git,哪个不是 C 写的?
但 Rust 确实在蚕食这个领域。Linux 内核开始接受 Rust 代码,Windows 内核也在搞 Rust 集成。
然后 rsync 这事让我想到一个问题:如果 rsync 是用 Rust 写的,Claude 改出来的代码会不会安全一些?
很难说。LLM 生成的 Rust 代码安全性未必比 C 高多少——unsafe block 一旦写错,该崩还是崩。但至少 borrow checker 能挡掉大部分内存问题。
——行了,跑偏了,回到正题。
社区炸了,但炸得有道理吗
GitHub Issue #929,标题直译过来是:"求你别用 vibe coding 把这软件搞砸了"。
这个 issue 的发言方式确实有点冲。HN 上有人评论说 "incredible obnoxious",也有人觉得"话糙理不糙"。
我看完所有评论,发现大家的担忧其实集中在三点:
1. 速度问题:2 个月 26k 行,即使人工 review 也跟不上这个节奏。review 速度跟代码生成速度完全不是同一个量级。
2. 信任问题:rsync 是跑在生产环境里的基础设施。它处理的是你最重要的数据。你把代码交给 AI 去改,用户凭什么信任新版本?
3. 动机问题:也是最让我困惑的一点——rsync 本身没什么大毛病啊。它不愁用户,不愁收入(也没收入),没有功能竞争压力。那为什么要在上面搞这种高风险实验?
HN 上有个评论说得特别到位:
"You wrote the perfect tool, you won. It makes no sense to gamble with that."
你写了一个完美的工具,你已经赢了。为什么要赌?
原理大概是这样,细节可能有出入——有懂的大佬欢迎指正。
延伸阅读
rsync 不是第一个被 AI 乱改的开源项目,也不会是最后一个。
同期还出现了一个叫 OpenRsync 的项目(现在 macOS 已经默认用它替代了旧版 rsync)。有人开玩笑说,rsync 3.4.3 的 AI 风波直接催生了一个竞争对手。
如果你对这类"古老工具 vs 现代 AI"的冲突感兴趣,我之前还写过一篇《为什么说 C 语言是 LLM 推理的隐藏王者?》,讲的是另一个角度——C 语言在 AI 时代的不可替代性。关注后回复「工具」就能看到。
另外,rsync 的 GitHub 仓库在这里:
GitHub:https://github.com/RsyncProject/rsync
它的 Issue #929 直接引发了这场风波,现在去看还能围观到当时的讨论现场。
一些个人的想法
写到最后,其实我想说的是——
我并不反对用 AI 辅助开发。我自己也用 AI 写代码,debug,写测试用例,写文档。但这东西有个度。
30 年的工具,它的稳定不是靠功能丰富,而是靠不动。
有些代码,动一行可能没什么。动一千行,可能也没什么——直到有一天,你的备份脚本突然把数据删了,或者同步到一半进程崩溃了,你才发现,原来那行代码是有理由那么写的。
别问我为什么知道。
问那个用 Claude 改 rsync 的维护者去吧。
本文使用 MGO 编辑并发布
关注“何三笔记”,回复“mgo” 免费下载使用

