大家好,我是何三,独立开发者
你用 ChatGPT 上传过一堆文件,然后让它回答问题吧?
那种体验,用一次还行,用多了就会发现一个很烦的事:它每次都在"重新发现"你喂给它的知识。你上周问过的问题,这周再问,它又是一脸茫然地把那几篇文档翻一遍,拼凑出一个差不多的答案。
这不叫知识管理。这叫每次都重新开卷考试。
最近 Karpathy(前特斯拉 AI 总监、前 OpenAI 创始成员)在 GitHub 发了一篇 Gist,不到 10 天已经 5000+ Star、435 条评论。核心观点就一句话:
别搞 RAG 了,让 LLM 给你建一个持续增长的个人百科全书。
然后——真的有人把这个构想做成了完整的桌面应用。就是今天要推荐的 LLM Wiki。

近 1200 Star,10 天内发了 4 个版本(v0.1.0 到 v0.3.1),252 次 commit。开发效率说实话有点离谱。
RAG 的问题在哪?
先说 RAG,毕竟现在满大街都在搞。
RAG 的流程大致是:你上传一批文档 → 系统把文档切成碎片 → 向量化存进数据库 → 每次提问时检索相关碎片 → 拼给 LLM 生成答案。
这套流程能用,但它有个根本性的缺陷:知识不累积。
每次你问一个需要综合五篇文档的问题,LLM 都得从头把那五篇文档翻出来、拼在一起。上次分析过的矛盾?忘记了。上次建立的关联?没有了。上次总结的结论?重来一遍。
就像你每天早上醒来,失忆,然后把昨天看过的书重新翻一遍。效率感人。
而且 RAG 还有一个很实际的问题:需要搭向量数据库。Pinecone、Milvus、Chroma……不管选哪个,都是额外的成本和学习负担。Pinecone 一个 starter 计划 70 刀一个月,存你那几百篇 PDF 真的大可不必。对个人开发者来说,为了管自己的知识库还得搭一套基础设施(或者每个月给别人交保护费),这事儿本身就很魔幻。

LLM Wiki 的思路:编译一次,持续更新
Karpathy 提出的思路完全不同。
他把这个过程类比成写代码:
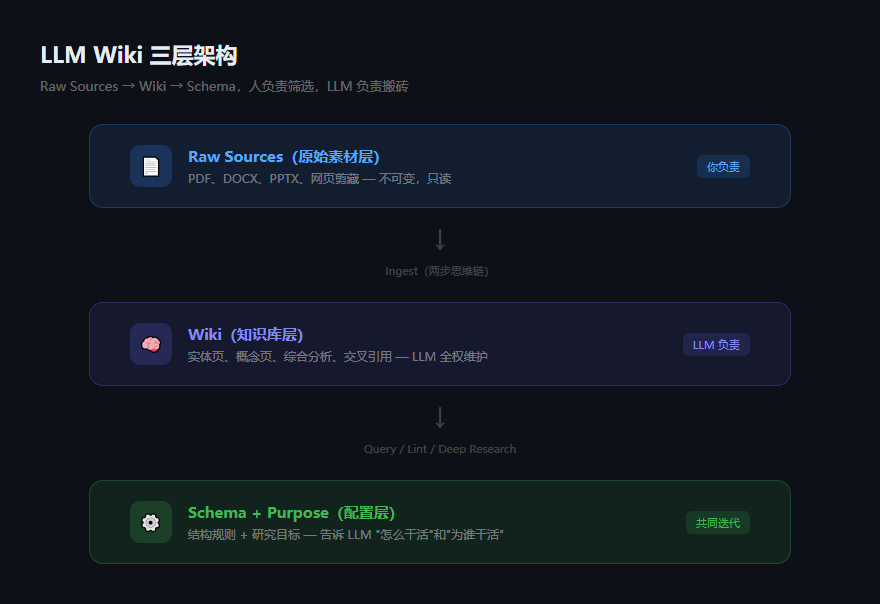
- Raw Sources(原始素材)= 你的源文件,不可修改,只读
- Wiki(知识库)= LLM 编译出来的"可执行程序",持续迭代
- Schema(规则配置)= 告诉 LLM 这套系统的"编译规范"
核心操作就三个:
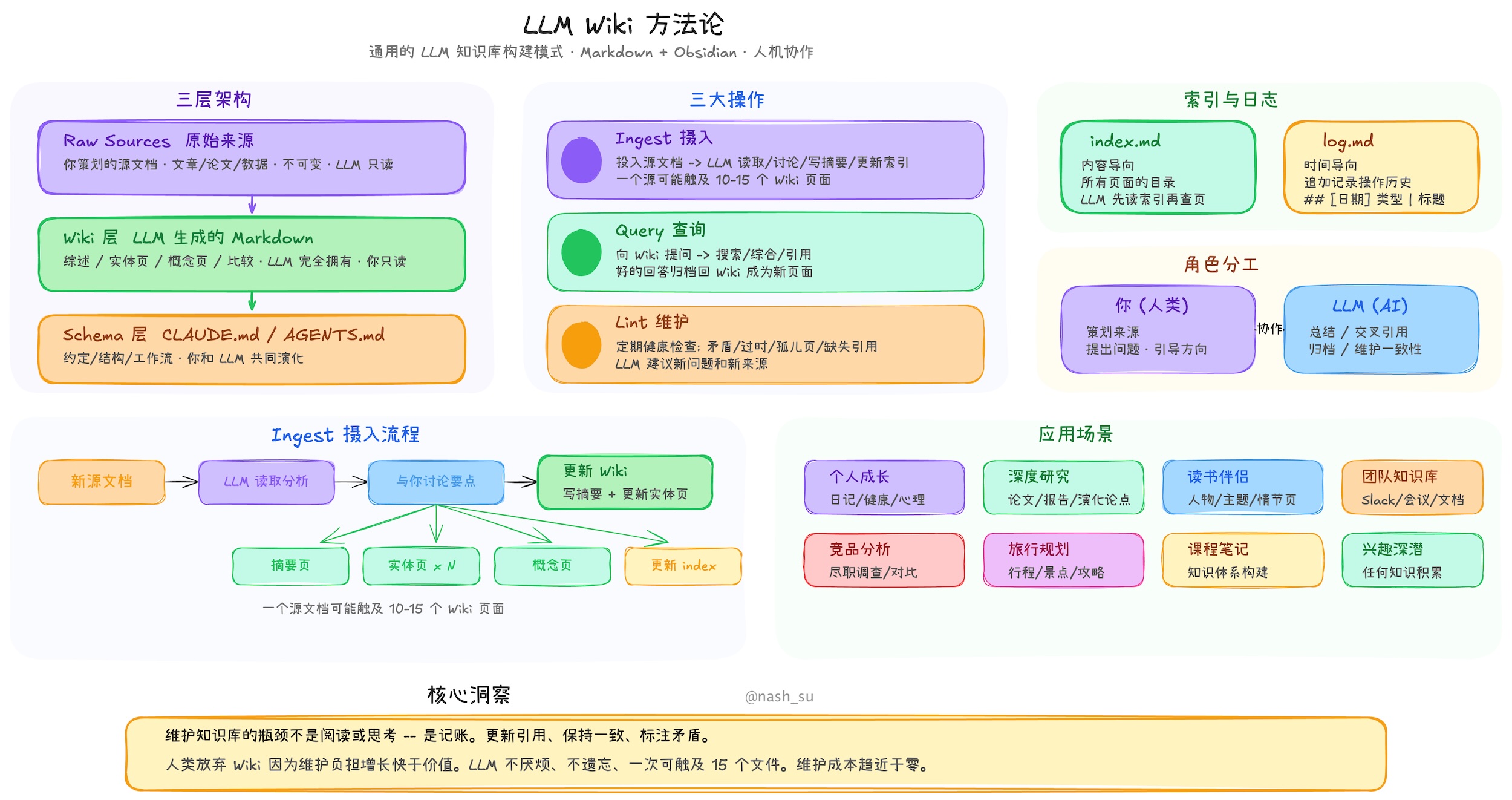
- Ingest:丢一篇新文档进去,LLM 读取 → 提取关键信息 → 更新已有的 Wiki 页面(实体页、概念页、综合页),发现矛盾就标记出来。一篇文档可能同时更新 10-15 个 Wiki 页面。
- Query:提问时,LLM 直接在 Wiki 里找相关页面——这些页面已经是"编译好"的知识了,不需要从原始文档重新推导。
- Lint:定期让 LLM 做个"健康检查"——有没有矛盾?有没有孤立页面?有没有该建但没建的交叉引用?
大白话翻译就是:RAG 是每次临时拼答案,LLM Wiki 是先建一座图书馆,再去查。
这个区别乍一看好像差不多,但实际用起来差距很大。Karpathy 说的那句总结我觉得很到位:
"维护知识库最烦的不是阅读和思考,而是'记账'。更新交叉引用、保持摘要最新、标记矛盾……人类放弃知识库,就是因为维护成本增长得比价值快。LLM 不会烦、不会忘,一次能改 15 个文件。"
说白了,人负责"看什么",LLM 负责"怎么记"。这才是正儿八经的分工。
这个桌面应用做了什么?
好,Karpathy 的 Gist 只是一个构想描述,类似设计文档。而 nashsu/llm_wiki 把它做成了一款能直接用的桌面应用。
几个亮点:
两步思维链 Ingest。不是让 LLM 一边读一边写(容易漏),而是拆成两步:先分析(提取实体、概念、矛盾),再生成(写 Wiki 页面)。生成的质量明显好很多。而且加了 SHA256 增量缓存——源文件没改过就跳过,省 Token 省时间。
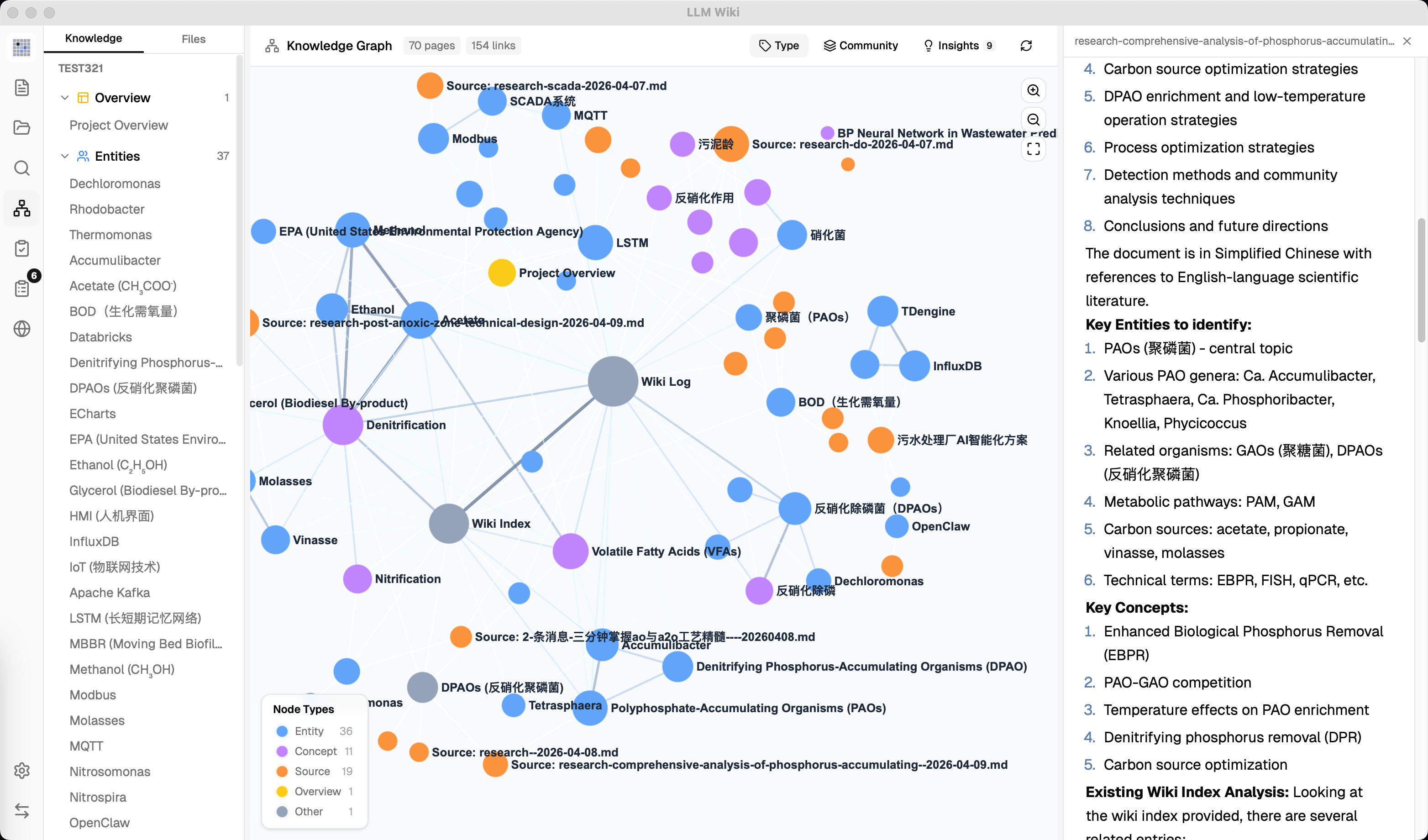
我自己试了一下,丢了一篇 20 页的 PDF 论文进去,大概等了 40 秒,自动生成了 6 个 Wiki 页面——一个摘要页、两个实体页、一个概念页、一个交叉引用页,还有一个被标记为"待确认"的 Review 项。再丢第二篇相关论文进去的时候,已经存在的实体页被自动更新了,新出现的概念又多生成了 3 个页面。这种感觉就是……它在帮你记笔记,而且不嫌烦。
四信号知识图谱。不只是 Wiki 里互相链接就算有关联了。它用了四个维度来计算相关性权重:直接链接(×3.0)、来源重叠(×4.0)、Adamic-Adar 共同邻居(×1.5)、类型亲和(×1.0)。然后基于这个图谱,用 Louvain 算法自动发现知识聚类——它能告诉你"你收集的这些资料里,哪几个主题天然形成了一个知识域"。
Deep Research。当知识图谱发现"知识空缺"时(比如某个概念只有一两篇引用,明显不够),可以直接触发 Web 搜索(通过 Tavily API),搜到的结果自动回灌到 Wiki 里。这个功能有点像"知识库自己知道自己哪里不知道"。
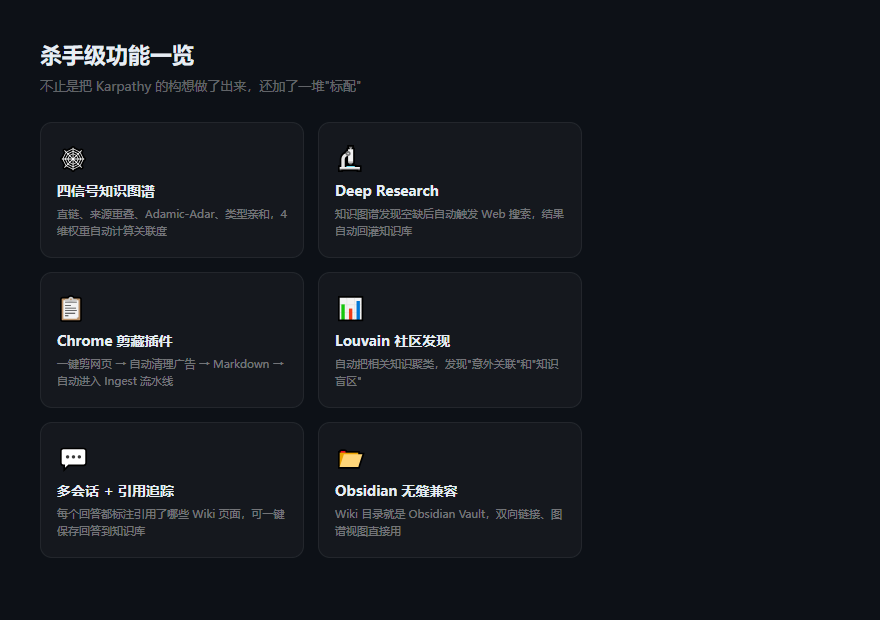
Chrome 剪藏插件。一键把网页抓下来 → Readability.js 清理广告 → 转 Markdown → 自动进入 Ingest 流水线。这个链路很顺,比我之前用的那些剪藏工具省心多了。
Obsidian 兼容。Wiki 目录直接就是一个 Obsidian Vault,双向链接 [[wikilink]] 语法、图谱视图,Obsidian 用户无缝接入。话说隔壁 Obsidian 现在也学坏了,同步服务一年 50 刀,用本地 Markdown 的方案反而更有吸引力了。
支持一大堆格式。PDF、DOCX、PPTX、XLSX,连图片视频都能预览。多格式支持这个事看起来不起眼,但实际用的时候,知识来源真的是五花八门。
技术栈方面:Tauri v2(Rust 后端)+ React 19 + TypeScript,前端用的 shadcn/ui。图表用的 sigma.js + graphology。向量搜索可选,用 LanceDB(Rust 原生,嵌入式),不需要额外搭服务。支持 OpenAI、Anthropic、Google、Ollama 和自定义端点。
怎么跑起来?
直接去 Releases 下载就行:
- macOS:
.dmg(Apple Silicon + Intel 都有) - Windows:
.msi - Linux:
.deb/.AppImage
不想用预编译的,从源码 build 也行(需要 Node.js 20+ 和 Rust 1.70+):
git clone https://github.com/nashsu/llm_wiki.git
cd llm_wiki
npm install
npm run tauri dev # 开发模式,Rust 编译比较慢,首次大概 3-5 分钟
npm run tauri build # 生产构建
启动之后的流程:
- 创建一个新项目(有研究、阅读、个人成长等模板可选)
- Settings 里配置你的 LLM 提供商(API Key + 模型名,支持 Ollama 本地模型)
- Sources 里导入文档
- 等着看 Activity Panel 里的进度条——LLM 自动开始生成 Wiki 页面
- 然后就可以在 Chat 里问问题了,在 Graph 里看知识图谱了
配置这块没什么坑,就是得有个能跑的 LLM。官方建议用 GPT-4o 或 Claude Sonnet 级别的模型,太弱的模型 Ingest 质量会差一些。省钱的话用 DeepSeek 也行,Karpathy 的 Gist 评论区有人在 DGX Spark 上跑,效果也可以。
值不值得试?
实话说,这个项目适合三类人:
-
学术研究者 / 深度阅读爱好者。读论文、读长文、做研究笔记,需要跨文档综合分析。这种场景下,传统笔记软件的"分类 + 标签"根本不够用,LLM Wiki 的交叉引用和知识图谱才有价值。
-
Obsidian 重度用户 + LLM 使用者。已经在用 Obsidian 管笔记,但手动维护双向链接和知识图谱太累了。LLM Wiki 让 Obsidian 变成了"只读界面",所有脏活累活交给 LLM。
-
对 RAG 方案不满的开发者。搭过向量数据库,发现"每次从零检索"的体验确实不行,想要"知识持续累积"的效果。
如果你只是偶尔问 ChatGPT 几个问题,那这个工具对你来说太重了。但如果你有"长期积累某个领域知识"的需求,LLM Wiki 的范式确实值得认真看看。
同类工具推荐
如果你对"LLM + 个人知识管理"这个方向感兴趣,还有几个项目值得了解:
- Karpathy 的原始 Gist(5000+ Star):本文介绍的 LLM Wiki 就是基于这篇文档的构想实现的。Gist 评论区 435 条讨论质量极高,很多人分享了各自的实现方案和踩坑经验。
- SwarmVault:另一个 LLM Wiki 模式的实现,走 CLI 路线,已出 Obsidian 插件。适合更喜欢命令行工作流的用户。
- OmegaWiki:北大团队做的全生命周期研究平台,把 LLM Wiki 概念接入完整的研究管线——从论文摄入到实验设计到论文写作。
如果你对 AI 工具有兴趣,我此前还整理过 AI 编程工具和效率工具的合集,关注后回复「工具」获取。
行了,先把这些论文丢进去让它跑着。能不能坚持用下去,过两周再说。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

