大家好,我是何三,独立开发者
今天发现一个叫perf-sentinel的项目,是个用 Rust 写的性能监控工具。看 README 说内存占用 <10MB,我第一反应是:吹牛吧?Datadog 那玩意儿动不动 150MB,这差 15 倍呢。
但仔细一看,人家是认真的。这玩意儿不光轻量,还带了个碳感知评分功能,能算你每个 API 端点产生多少碳排放。这年头连代码都要算碳足迹了(刚看到这功能时我愣了一下,心想这跟性能监控有啥关系)。
这玩意儿干啥的?
简单说,perf-sentinel 是个性能反模式检测工具。它能自动发现 N+1 查询、冗余 HTTP 调用、慢查询这些常见问题。但跟传统 APM 不一样的是,它不依赖特定语言或 ORM,而是直接在协议层分析。
举个例子:你有个微服务架构,订单服务调用户服务,用户服务又调库存服务。传统 APM 得在每个服务装 agent,perf-sentinel 直接分析 OpenTelemetry 的 trace 数据,不管你是 Java、Go 还是 Rust 写的。
这思路挺聪明(我边看边想,为啥以前没人这么干)。不用理解 JPA、EF Core 这些 ORM 的细节,就看 SQL 查询和 HTTP 调用,问题反而更明显。
上手试试
安装很简单,Rust 项目嘛:
cargo install perf-sentinel
或者直接下载二进制:
curl -LO https://github.com/robintra/perf-sentinel/releases/latest/download/perf-sentinel-linux-amd64
chmod +x perf-sentinel-linux-amd64
跑个 demo 看看:
perf-sentinel demo
这命令会生成一些模拟的 trace 数据,然后分析给你看。我跑了一下,输出是这样的:
Analyzing 5 traces...
Found 3 findings:
1. N+1 SQL (CRITICAL)
- Template: SELECT * FROM order_items WHERE order_id = ?
- Occurrences: 10
- Suggestion: Batch these 10 queries into one WHERE ... IN (?)
- I/O Intensity Score: 10.0 (critical)
- Estimated avoidable CO₂: 0.000021 g
2. Redundant HTTP (WARNING)
- Template: GET /api/users/{id}/profile
- Occurrences: 3
- Suggestion: Cache or batch these calls
- I/O Intensity Score: 3.0 (moderate)
3. Slow SQL (INFO)
- Template: SELECT * FROM products WHERE category = ? ORDER BY price DESC LIMIT 100
- Duration: 650ms (threshold: 500ms)
- Suggestion: Add index on (category, price)
看到没?不光告诉你问题在哪,还估算碳排放。虽然这碳估算就是个参考(README 里明确说了,不准用于合规报告),但能让你意识到:性能问题不光影响用户体验,还费电。
碳感知评分是咋算的?
这部分有点意思(我花了点时间看源码,但没全看懂,反正原理大概是这样):
perf-sentinel 用了 Green Software Foundation 的 SCI v1.0 标准(ISO/IEC 21031:2024)。简单说,它把 I/O 操作(SQL 查询、HTTP 调用)映射到能量消耗,再根据你服务器所在地的电网碳强度,算出碳排放。
内置了 30 多个云区域的碳强度数据,比如: - eu-west-3(巴黎):42 gCO₂/kWh - us-east-1(弗吉尼亚):379 gCO₂/kWh - ap-southeast-1(新加坡):408 gCO₂/kWh
差别还挺大。如果你服务跑在新加坡,同样的代码产生的碳是在巴黎的 10 倍(这数字让我愣了一下,原来选址这么重要)。
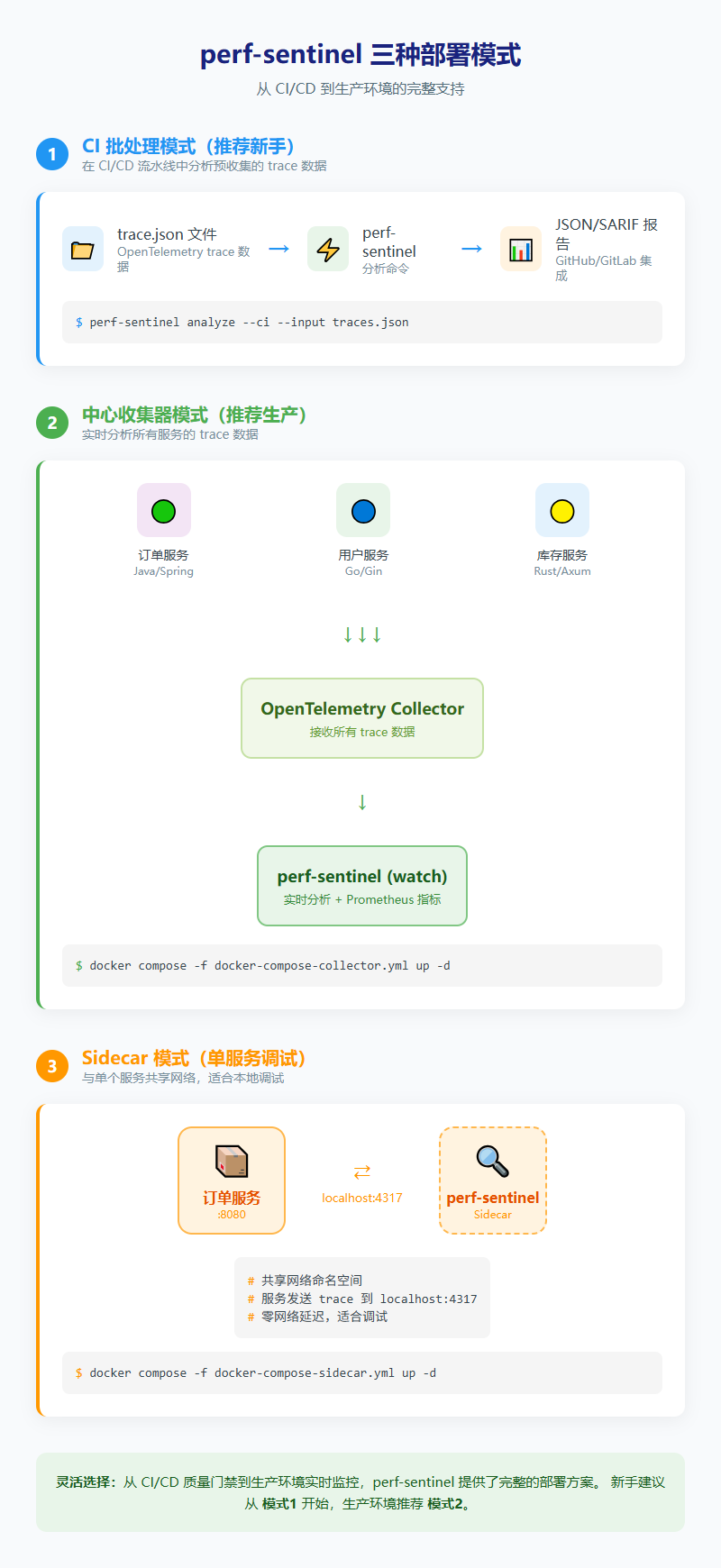
三种部署模式
这工具支持三种用法,挺灵活的:
1. CI 批处理模式(推荐新手)
perf-sentinel analyze --ci --input traces.json
在 CI/CD 流水线里跑,发现性能问题就失败。可以设置质量门禁,比如"不允许有 N+1 查询"。
2. 中心收集器模式(生产环境) 用 Docker Compose 起个 OpenTelemetry Collector,所有服务把 trace 发过去,perf-sentinel 实时分析。
3. Sidecar 模式(单服务调试) 跟单个服务跑在一起,共享网络,适合本地调试。
我试了第一种,配置个 .perf-sentinel.toml:
[thresholds]
n_plus_one_sql_critical_max = 0 # 不允许 N+1 查询
io_waste_ratio_max = 0.30 # 最多 30% 的 I/O 是浪费的
[green]
enabled = true
default_region = "eu-west-3"
跑完会输出 JSON 报告,还能转成 SARIF 格式给 GitHub/GitLab 的代码扫描用。
跟商业 APM 对比
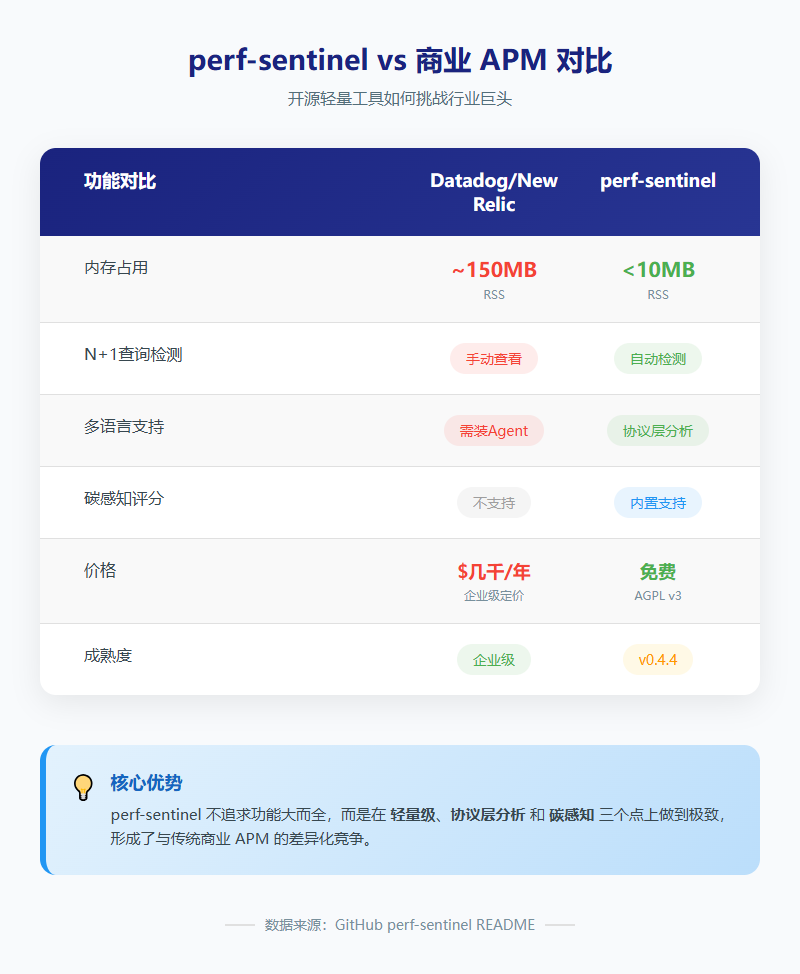
| 功能 | Datadog/New Relic | perf-sentinel | 我的评价 |
|---|---|---|---|
| N+1 检测 | 手动看 trace | 自动检测 | ✅ 赢 |
| 多语言支持 | 要装 agent | 协议层分析 | ✅ 赢 |
| 内存占用 | ~150MB | <10MB | ✅ 大赢 |
| 碳感知评分 | 没有 | 内置 | ✅ 创新点 |
| 价格 | 每年几千刀 | 免费 | ✅ 不用说了 |
| 成熟度 | 企业级 | 新项目 | ❌ 还需时间 |
perf-sentinel 现在还是 v0.4.4,刚发布不久。功能上肯定没 Datadog 全,但核心的检测能力已经有了。关键是,它解决了商业 APM 最痛的两个点:太重和太贵。
延伸阅读
最近 Rust 在系统工具领域爆发,除了 perf-sentinel,还有:
- smolvm - 子秒级冷启动的微服务虚拟机,比传统容器轻很多
- zed-editor - Rust 写的协作编辑器,启动 <50ms
这些项目都展示了 Rust 在性能敏感场景的优势。如果你也想学 Rust,关注后回复「rust」获取我整理的 Rust 学习路线图。
最后说两句
perf-sentinel 这项目让我看到了开源工具的另一种可能:不追求功能大而全,而是在特定点上做到极致。<10MB 内存、协议层分析、碳感知评分,这三个点组合起来,形成了足够的差异化。
当然,新项目总有风险(我刚装的时候还遇到个编译错误,后来发现是 Rust 版本问题)。但如果你现在被商业 APM 的价格和资源消耗困扰,值得试试这个。
至少,下次 DevOps 问你"为啥服务器负载这么高",你可以说:"我在优化碳足迹呢"(虽然他们可能听不懂)。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

