大家好,我是何三,独立开发者
770M 参数打平 1.3B。
这个比例一摆出来,懂行的人应该已经坐直了。参数直接砍半,效果居然没掉——这不是量化压缩,也不是蒸馏,而是直接把 Transformer 的层给“循环利用”了。
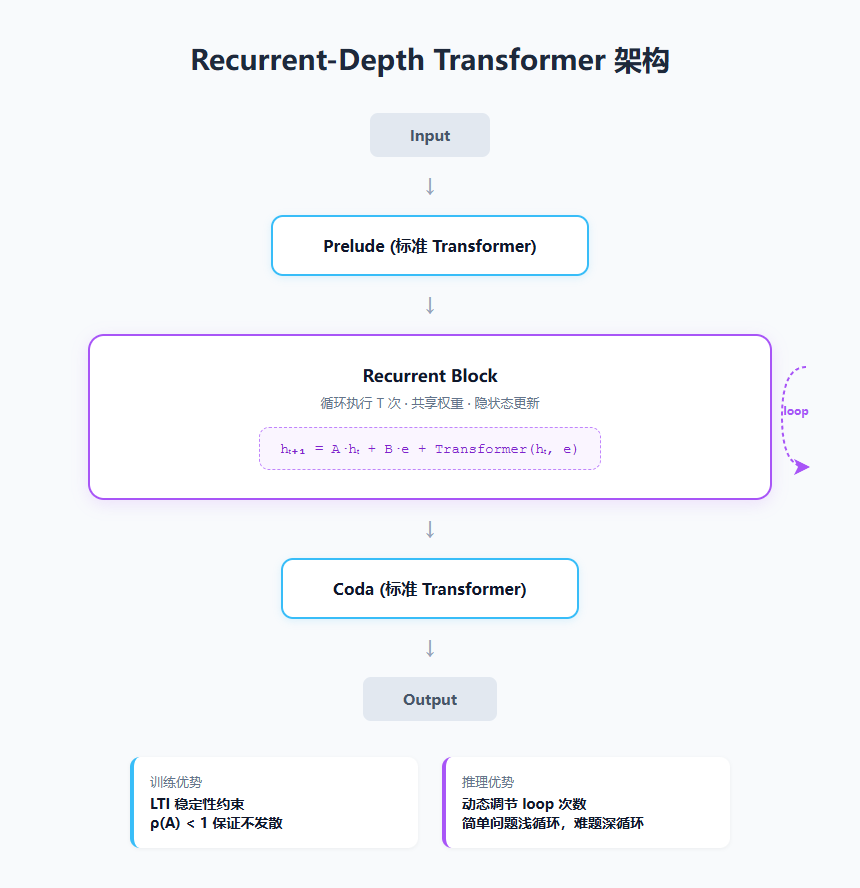
这个项目叫 OpenMythos,GitHub 上已经拿了 8.3k Star(近 1 万)。作者 Kye Gomez 干了一件挺疯的事:他试图用公开论文里的线索,把 Claude Mythos 的架构从第一性原理给重建出来。结果搞出了一个 Recurrent-Depth Transformer,简称 RDT。
说白了,传统的大模型就像盖楼,一层一层往上堆,堆得越高越聪明。RDT 的思路是:别盖那么多层了,就修个三五层的“核心楼”,然后让数据在里面多转几圈。
转一圈,等于浅层思考。转八圈,等于深度推理。
同一组权重,循环多次。参数不增加,深度随便调。
这有点像什么呢?我突然想起小时候玩的卡带游戏机。一个游戏卡带容量就那么大,但好游戏能让你在同样的地图里反复探索,每次都有新剧情。RDT 也是这个路数:模型体积不大,但同一块“地图”能让你跑很多遍,每遍都在做更复杂的推理。
不过说实话,循环网络这东西,历史上名声不太好。RNN 当年就是因为梯度爆炸和消失,被 Transformer 按在地上摩擦的。现在居然有人要把“循环”重新请回 Transformer 里?作者怎么保证它不炸的?
答案藏在 LTI 稳定性约束里。名字很唬人,其实道理简单:让每次循环的“信号放大系数”严格小于 1。用大白话说,就是每次转圈的时候,系统会自己踩刹车,防止越转越疯。
代码里是通过对注入参数 A 做连续负对角矩阵约束实现的。保证谱半径 ρ(A) < 1,不管学习率怎么跳,它都不会发散。
原理大概是这样,细节可能有出入——有懂的大佬欢迎指正。
好,知道它稳了,那效果到底怎么样?
论文里的数据很直接:770M 参数的循环模型,下游任务质量打平了 1.3B 的固定深度 Transformer。参数差不多省了一半。而且推理的时候,你可以根据问题的难度动态调整循环次数。简单问题转两圈,难题转六十四圈。
这个压缩率——算了先不说这个,你先装上看效果。
装起来很容易:
pip install open-mythos
然后跑一段官方示例:
import torch
from open_mythos.main import OpenMythos, MythosConfig
cfg = MythosConfig(
vocab_size=1000,
dim=256,
n_heads=8,
max_seq_len=128,
max_loop_iters=4,
prelude_layers=1,
coda_layers=1,
n_experts=8,
n_shared_experts=1,
n_experts_per_tok=2,
expert_dim=64,
lora_rank=8,
attn_type="mla",
)
model = OpenMythos(cfg)
ids = torch.randint(0, cfg.vocab_size, (2, 16))
out = model.generate(ids, max_new_tokens=8, n_loops=8)
print(out.shape)
n_loops=8 就是循环 8 次。你要是嫌不够深,改个数字就行,模型权重完全不用动。
这项目还有个挺贴心的地方:它直接给了从 1B 到 1T 的预配置型号。想试哪个规模,一行代码调出来。
from open_mythos import mythos_7b, OpenMythos
cfg = mythos_7b()
model = OpenMythos(cfg)
不过要吐槽一句,文档写得跟谜语人似的。README 里堆了大量论文引用和公式,但真想跑训练,你还得自己扒 training/ 目录下的脚本。3B 模型的训练脚本倒是给了,支持单卡和多卡 DDP,数据集用的 FineWeb-Edu,Tokenizer 居然是 openai/gpt-oss-20b,这个混搭风格……挺有意思的。
对了,它注意力支持 MLA 和 GQA 两种模式,FFN 换成了稀疏 MoE,还有共享专家。这也是为什么它能撑到 1T 参数规模——虽然总参数量看着吓人,但每次只激活约 5%,实际计算量并不大。
我觉得最离谱的还是这个“过度思考”问题。
循环多了就一定更好吗?不是的。作者提到,转太多圈之后,模型反而会从“解出答案”滑向“陷入噪声”。于是他们推测 Mythos 里应该有类似 ACT(Adaptive Computation Time)的自适应停止机制。简单说就是:模型自己判断“我想明白了”,然后提前收工。
这让我想到,人好像也一样。想太多的时候,答案反而模糊了。
OpenMythos 当然只是个理论重建,作者也明确说了跟 Anthropic 没有半毛钱关系。但它背后的那套思路——用循环深度换推理能力,用稳定性约束换可训练性——确实给当前“无脑堆参数”的风气泼了盆冷水。
同一个层跑 64 次,真的不等于 64 个独立层吗?从数学上讲不完全等于,但从工程上讲,它用极小的内存 footprint,换来了可调节的推理深度。这对部署来说太香了。
如果你对这类底层架构有兴趣,我之前还写过另一篇关于高效 Transformer 变体的文章,关注后回复「架构」可以拿到整理清单。另外,Relaxed Recursive Transformers 这个项目也值得一看,它在循环层里加了 LoRA 微调,能让每一圈都略有不同,算是 OpenMythos 的一个互补方向。
这东西,怎么说呢,就是那种……初看觉得作者在瞎搞,细想发现有点东西的项目。到底能不能复现出 Claude Mythos 级别的效果?我不知道。但至少它提供了一条完全不同的路径:不堆楼,只转圈。
值得试试。
本文使用 MGO 编辑并发布
关注“何三笔记”,回复“mgo” 免费下载使用

