大家好,我是何三,独立开发者
写过 Playwright 脚本的都知道,它就是个定时炸弹
昨晚一个同事的自动化脚本又挂了,报了个 Element not found。打开一看,网站改了个按钮的 class 名。半天的活,白干。
浏览器自动化这玩意儿,写的时候爽,跑起来也行,但只要目标网站一改版,你的脚本就变成了薛定谔的代码——不跑一下你永远不知道它死没死。
Playwright、Puppeteer、Selenium,底层逻辑都一样:靠选择器定位元素。网站前端团队改个 div 结构,你的脚本当场去世。
但最近我发现了一个项目,思路完全不一样。
500 Star,HN 120+ 分,来自一个医疗创业公司
Libretto,GitHub 上近 500 Star,由 Saffron Health 团队开源。
他们干医疗数据集成的,天天要和各种医疗系统(EHR)打交道。这类系统网页都是老古董,结构乱七八糟,传统选择器方案根本扛不住。
所以他们搞了一个工具:给你一个活浏览器,让 AI 帮你"看"页面。
不是靠选择器去猜元素在哪,而是直接截图,让 AI 分析页面结构和网络请求,然后生成确定性脚本。
思路变了。从"猜测元素位置"变成"理解页面在干什么"。
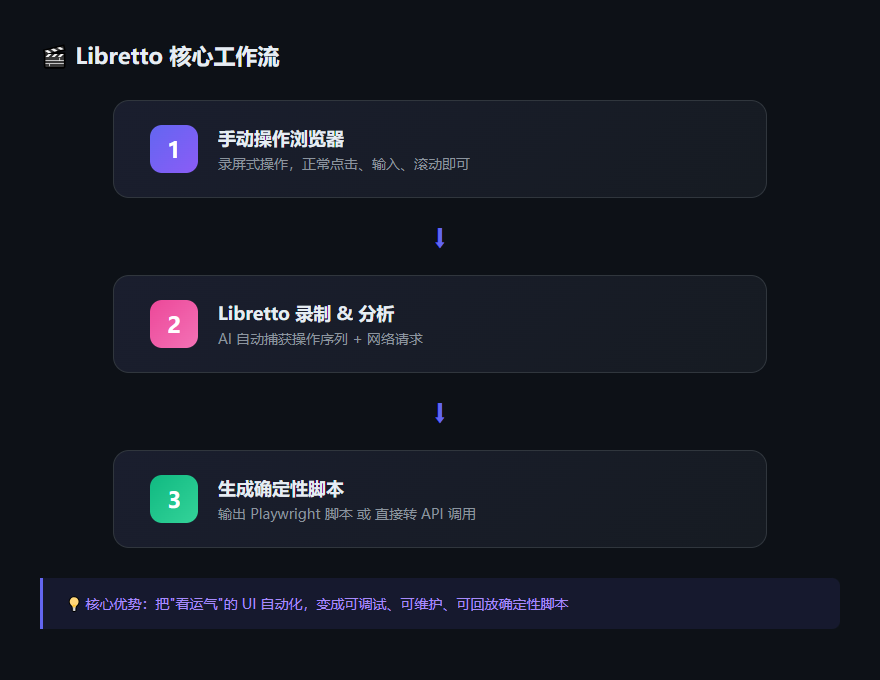
核心原理:AI 读图,而不是猜选择器
Libretto 的工作方式,说直白点就是:
1. 你手动操作一遍浏览器
打开目标网站,正常地点击、输入、滚动。Libretto 在后台录制你的所有操作和对应的网络请求。
2. AI 分析"你干了什么"
它不是简单地回放鼠标轨迹,而是结合截图、DOM 快照和网络请求,让 LLM 理解你操作的业务逻辑。比如"从第 3 个表格中提取患者 ID,然后点提交"。
3. 生成确定性脚本
输出的是 Playwright TypeScript 代码。而且是"理解语义"级别的代码,不是那种 click('#submit-btn-20384') 的脆弱写法。
更狠的是第四个能力:把浏览器脚本转成直接 API 调用。
它抓了你的网络请求之后,可以反过来推导出这个网站的后端 API 结构,然后生成一个直接调 API 的脚本。不打开浏览器,速度快一个数量级,稳定性也高得多。
(我第一次看到这个功能的时候愣了一下——这不就是抓包逆向吗?只不过让 AI 把脏活干了。)
上手体验
装起来很简单:
npm install libretto
npx libretto setup
setup 会自动下载 Chromium、检测你本地的 API Key(OpenAI / Anthropic / Gemini 都行),然后配置好。
准备工作结束。没报错。神奇。
然后用法就很自然了——你直接对着你的 AI 编程工具(比如 Claude Code、Cursor)说:
用 Libretto 去 LinkedIn 抓前 10 条帖子的内容、作者和评论数
它会弹出浏览器让你登录,然后自动开始探索和抓取。整个过程你只需要看着就行。
如果你想自己演示操作,也可以:
我来演示一下这个医疗系统的查询流程,你用 libretto 记下来,然后生成脚本
你操作完,它就生成脚本了。
日常用的 CLI 命令也就这几个:
npx libretto open <url> # 打开浏览器
npx libretto snapshot # 截图 + AI 分析
npx libretto exec "code" # 执行 Playwright 代码
npx libretto close # 关闭浏览器
够了,不需要更多。话说有些工具恨不得给每个参数都加个 flag,看着就头疼。
API 调用成本怎么控制?
说到这里,有一个绕不开的问题:Libretto 每次快照分析都要调 LLM API,跑个几十次下来,token 消耗也不少。如果你像我用 Claude Code + Libretto 搭配着干活,一天下来 API 费用很容易就上去了。
这里推荐 Unity2 这个 API 中转站,OpenAI、Claude、Gemini 都支持,价格比官方便宜不少,而且注册就送额度,拿来跑这类自动化脚本刚好。有需要的可以试试:https://unity2.ai/register?ref=aWrXutTo
当然,如果你本身有企业账号或者公司报销,当我没说 😂
谁需要这个?
写网页爬虫的、做 RPA 自动化的、维护第三方系统集成的——基本涵盖了所有"需要和别人的网站打交道"的开发者。
特别是那些目标网站经常改版、你的脚本三天两头挂的场景,Libretto 这种"AI 读图"的方式比纯选择器方案抗造得多。
当然,它也不是万能的。目前还处于早期阶段(v1.0 之前),API 可能有变动。而且依赖 LLM,每次快照分析都需要调 API,用多了也是一笔开销(不过比脚本挂了之后排坑的时间成本便宜多了)。
同类工具
如果你在搞浏览器自动化,这些项目也可以看看:
- Playwright(近 70k Star)——微软出品,目前最主流的浏览器自动化框架。Libretto 底层用的就是它。
- Browser-use(约 35k Star)——让 AI Agent 直接操控浏览器的框架,偏 AI Agent 方向,和 Libretto 的思路有交叉但定位不同。
- LaVague(约 8k Star)——另一个 Web Action Agent,同样是用 LLM + 浏览器自动化,不过更偏通用 AI Agent 场景。
如果你对这类"AI + 自动化"工具有兴趣,关注后回复「工具」,我之前整理过一期合集。
说到底
浏览器自动化的核心痛点从来没变过:目标网站会变,你的脚本跟不上。
Libretto 换了个思路——不再试图"精准定位"元素,而是让 AI "理解"页面在干什么。从脆弱的选择器匹配,变成了语义级的操作理解。
思路一换,天花板就完全不一样了。
不过说实话,这类"AI + 浏览器自动化"的工具最近冒出来不少。Libretto 目前最大的差异化在于录制回放 + API 逆向这个组合,确实解决了实际痛点。至于能不能成为这个品类的标准工具,还得看社区生态建设。早期项目嘛,先Star 防走失总没错。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

