大家好,我是何三,独立开发者
用 AI 写代码这事儿,有一个特烦的体验:每次开新会话,AI 都像个刚出厂的机器人。
你上周刚搭好的 JWT 认证架构,本周问它限流怎么加——它完全不知道你在说什么。你得把目录结构、中间件路径、选型理由全部重新交代一遍。
烦不烦?说实话,烦透了。
我也试过 CLAUDE.md、.cursorrules 这些内置方案。200 行的容量上限,没多久就满了。手动维护?更扯,我是来偷懒的,不是来当文档管理员的。
然后我发现了 agentmemory。
一个 npm 命令装完,所有 AI 编码助手——Claude Code、Cursor、Codex CLI、Gemini CLI、Windsurf——全部共享同一个记忆体。不用外部数据库,纯本地运行,每秒检索只要 14 毫秒。
说白了,它就是给你的 AI 编程助手装了个海马体。
反差数据:先看三组硬指标
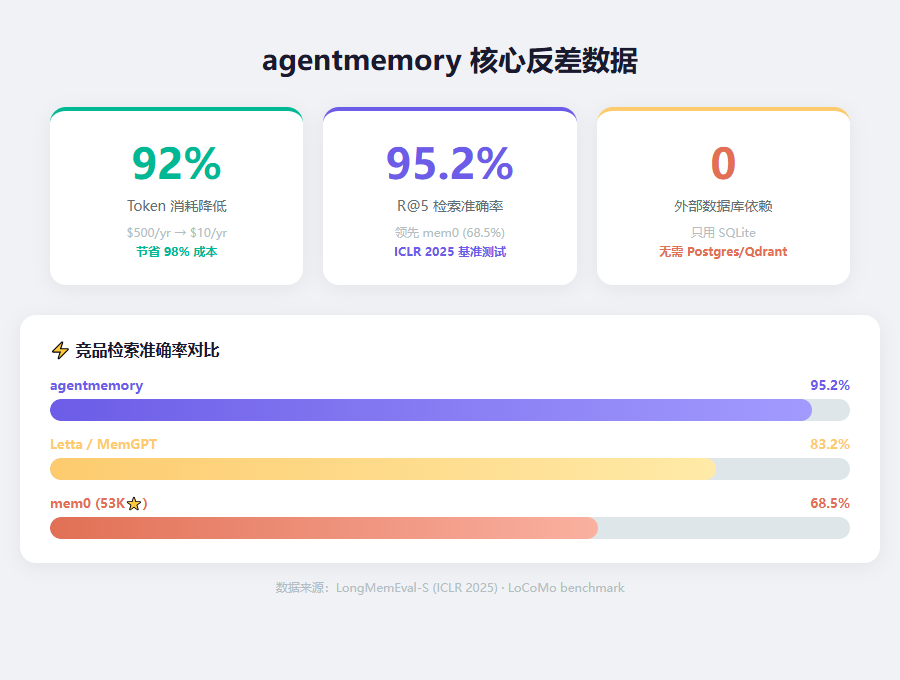
先甩三组数字,再讲原理。
第一,Token 消耗降低 92%。
传统做法是把全部上下文塞进窗口,一年跑下来 1950 万 Token——贵到离谱,而且窗口根本塞不下。如果用 LLM 做摘要,一年也要 650K Token,折合 $500。
agentmemory 怎么搞的?它把记忆压缩成向量 + BM25 混合索引,每次只取最相关的上下文。一年才 170K Token,成本 $10。
如果你用本地嵌入模型 all-MiniLM-L6-v2——这个钱也不用花,$0。
第二,检索准确率 95.2%。
这个数据来自 ICLR 2025 的 LongMemEval-S 基准测试,500 道题。同样是混排搜索,BM25 只有 86.2% 的 R@5,agentmemory 做到了 95.2%。
对比一下那些 5 万星的热门竞品:mem0 在 LoCoMo 上只有 68.5%,Letta/MemGPT 是 83.2%。
第三,零外部数据库依赖。
做一个检索系统,通常要搭 Postgres、再配个 Qdrant 或者 pgvector。agentmemory 什么都不需要——一个 SQLite 文件搞定全部存储。装完就能用,不需要 DBA,不需要 Docker Compose。
它是怎么做到的?用最土的话解释
这东西的底层引擎叫 iii,用 Rust 写的。
它做了四件事:
第一,自动捕获。 装了 12 个钩子,你的 AI 助手每次操作——写代码、查文件、跑命令——全部自动录下来。零手动操作,不需要你主动说"记一下这个"。
第二,压缩索引。 录下来的东西不会躺在硬盘上长灰。它用 BM25(关键词)+ 向量(语义)+ 知识图谱(关系)三种方式同时索引,然后用 RRF 融合算法打分,找到最相关的内容。
第三,生命周期管理。 这玩意儿有四层记忆分级。新鲜的、重要的内容保留;旧数据自动衰减、遗忘。不会像 CLAUDE.md 那样 200 行就爆炸。
第四,跨 Agent 共享。 一个记忆服务器,16 种 AI 编程工具全部能访问。你用 Claude Code 写的代码结构,切换到 Cursor 时它也知道。
说到 Rust 我就想起一件事。之前有个开源作者跟我说,Rust 的编译器比他的前女友还难哄,但凡你少写一个分号,它就给你甩脸色。但性能是真的香,agentmemory 每个查询 14ms,跟这种底层选型有很大关系。跑题了,回来。
原理大概是这样,细节可能有出入——有懂的大佬欢迎指正。
总之这就是一个你感知不到它在运行,但每次都会觉得"AI 怎么变聪明了"的东西。
上手试试?三分钟搞定
这是最离谱的地方:装它只需要一个命令。
npx @agentmemory/agentmemory
跑完之后,它在后台开了一个记忆服务器,端口 3111。
然后你再开一个终端,运行演示:
npx @agentmemory/agentmemory demo
这个 demo 会灌入三个真实的开发会话——JWT 认证搭建、N+1 查询优化、接口限流——然后让你试语义搜索。你搜"数据库性能优化",它能返回 N+1 查询优化的那一次修改。
注意,普通关键字搜索做不到这个。
你还可以访问 http://localhost:3113,实时看到记忆图谱在生成。节点、连接、时间线,全部可视。
想跟 Claude Code 打通?一行命令:
agentmemory connect claude-code
或者直接装全局版:
npm install -g @agentmemory/agentmemory
agentmemory
然后它就常驻后台了。以后每次打开 Claude Code、Cursor、Codex CLI……它什么都记得。
跟同类一比,差距更明显
| 维度 | agentmemory | mem0 (53K⭐) | Letta/MemGPT (22K⭐) | CLAUDE.md |
|---|---|---|---|---|
| 检索准确率 R@5 | 95.2% | 68.5% | 83.2% | 纯 grep |
| 自动捕获 | ✅ 12个钩子,0手动 | ❌ 要手动 add() | ❌ Agent自编辑 | ❌ 手动写 |
| 外部依赖 | ❌ 无 | ✅ Qdrant/pgvector | ✅ Postgres+向量库 | ❌ 无 |
| 跨Agent | ✅ 16种工具 | ❌ API无协调 | ❌ 仅限Letta内 | ❌ 各管各 |
| 年费 | $10(或$0) | 看集成方式 | 看部署方式 | 免费但废手 |
| 实时看板 | ✅ 本地3113端口 | ❌ 云端控制台 | ❌ 云端控制台 | ❌ 无 |
说白了,agentmemory 走的是反常识路线——别人都在堆外部数据库、堆云端架构,它一个 SQLite 文件全搞定,性能反而更好。
一个小建议
如果你已经是 AI 编程的重度用户,这东西应该会成为你的日常标配。
我不是说它完美——有些钩子的文档写得跟谜语人似的,比如 Claude Code 的 hook 路径依赖问题,你升级版本后可能还得重新跑一次 agentmemory connect claude-code --with-hooks。但这些问题社区里都有 Issue 跟踪,作者更新也勤快(v0.9.22 刚修了 22 个问题),总体瑕不掩瑜。
作者的话说得好:Session 1 你配好了 JWT 认证,Session 2 你再问限流——AI 已经知道你用 jose 中间件、路径在 src/middleware/auth.ts、选 jose 而不是 jsonwebtoken 是因为 Edge 兼容性。不用重复解释,不用复制粘贴,AI 就是知道。
这种感觉,真的有点爽。
项目地址:https://github.com/rohitg00/agentmemory
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

