大家好,我是何三,独立开发者
近 7 千 Star,9 天。DeepSeek 刚放了个大招——推理速度翻 2-3 倍,模型精度一点没掉。不是魔法,是正经开源。
如果你用过 ChatGPT、Claude 或者任何大模型,你一定经历过那种感觉:问了一个问题,AI 开始"思考",光标一闪一闪,你盯着屏幕等了两三秒它才憋出第一个字。
这几秒的延迟在开发者眼里尤其扎心——我写代码的时候,每一秒的等待都在打断心流。
之前大家的思路都是"换更大的 GPU"、"上更强的推理引擎"、"搞量化压缩"。但 DeepSeek 这波操作直接换了个赛道:不让大模型"完整思考"。
什么叫"不完整思考"?
你想想人类是怎么对话的。
我问你"今天天气怎么样",你不会先把整句话在心里默念一遍再开口。你听到问题之后,脑子里形成个大概思路,嘴就开始动了,同时大脑还在继续处理。
投机解码(Speculative Decoding)干的就这个事。
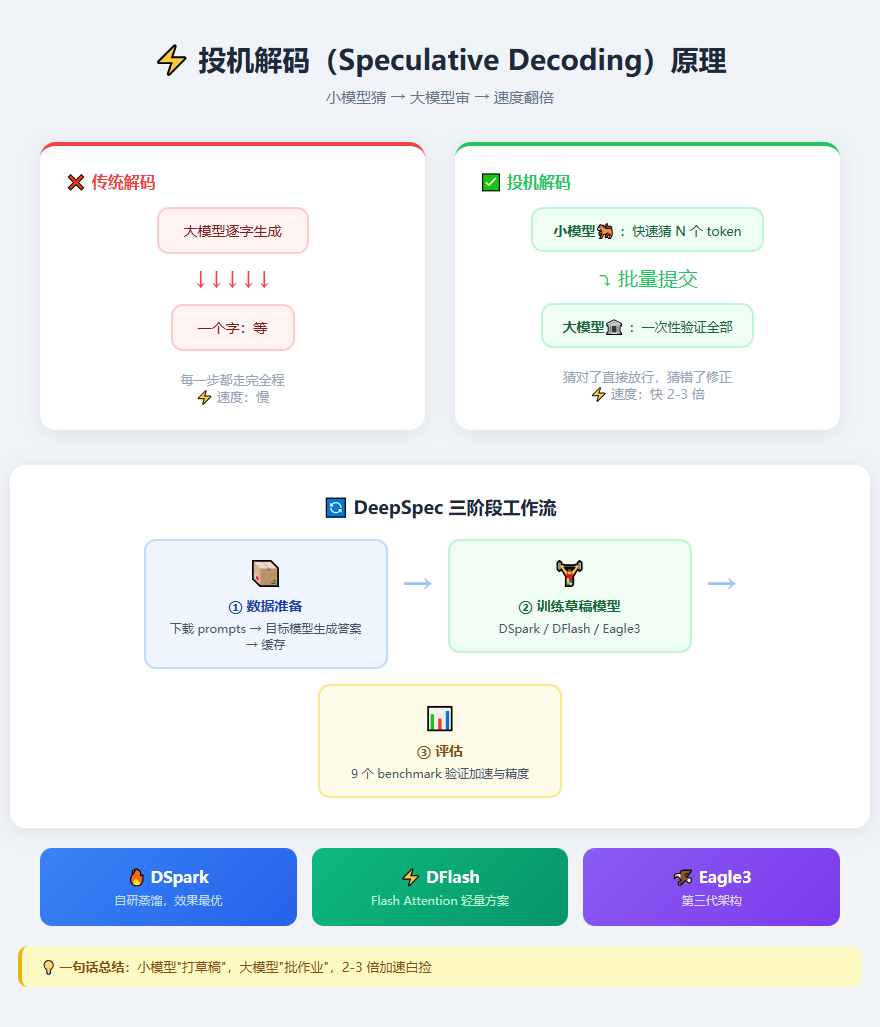
原理说人话就是:搞一个小模型当"马前卒",让它先快速猜一段可能的回答。大模型在后面"把关审核",觉得小模型猜对了就放行,猜错了再亲自改。
就这么一个简单的"猜 - 审"机制,直接把推理速度拉高了 2-3 倍。
说起来,这玩意儿让我想起了以前打《星际争霸》的时候——高手从来不等探路的小狗跑完全图再行动,而是先派几只小狗出去探路,主力部队同步跟上。猜对了直接推进,猜错了损失几只小狗也不亏。
说白了:不是让大模型变快,而是不什么事都让大模型亲自干。
DeepSpec 到底给了什么?
DeepSeek 开源的 DeepSpec,不是一个模型,而是一整套投机解码的训练 + 评估框架。
它包含三种算法:
- DSpark:DeepSeek 自研的蒸馏式草稿模型,效果最好
- DFlash:基于 flash 注意力机制的轻量方案
- Eagle3:基于 Eagle 架构的第三代方案
三种算法全部开源,配置文件、训练脚本、评估脚本一条龙。你只需要准备一个目标模型(比如 Qwen3、Gemma 等),就能训练自己的草稿模型来做推理加速。
实测数据挺离谱的——在 GSM8K 数学推理、HumanEval 代码生成、MT-Bench 对话等 9 个 benchmark 上,加速了 2-3 倍的同时,精度损失几乎为零。
这什么意思?你部署的同一个模型,用户感知到的响应速度快了将近三倍,但回答质量一点没缩水。
上手跑一圈
想体验的话,几行命令的事。
# 装依赖
python -m pip install -r requirements.txt
# 训练草稿模型
bash scripts/train/train.sh
# 评估效果
bash scripts/eval/eval.sh
默认配置是对 Qwen3-4B 模型做加速训练,8 张 GPU 单机就能跑。如果你只有 4 张卡,调一下 CUDA_VISIBLE_DEVICES 就行。
更省事的是,DeepSeek 已经把训练好的草稿模型 checkpoints 放到了 Hugging Face 上,可以直接下载推理:
- deepseek-ai/dspark_qwen3_4b_block7
- deepseek-ai/dflash_qwen3_4b_block7
- deepseek-ai/eagle3_qwen3_4b_ttt7
注意:数据准备阶段需要大约 38TB 的磁盘空间来缓存目标模型的输出——说实话,这块我也没完全搞懂为什么这么大。有懂的大佬欢迎指正,或者直接跳过这步用官方放出来的 checkpoint 也行。
投机解码这个赛道最近热闹得很:
- SpecForge(Apache-2.0):DeepSpec 的底层框架之一,SGLang 社区出品,也是投机解码的全栈方案
- vLLM:更偏推理引擎端,也支持 speculative decoding,但训练部分支持不如 DeepSpec 完整
如果你对这类"让AI跑得更快"的工具有兴趣,我此前还整理过《2026 年 GitHub 高性能神器排行榜》,关注后回复「工具」获取。
GitHub 仓库地址: https://github.com/deepseek-ai/DeepSpec
快 7k Star 了还在涨。有兴趣的同学可以关注一下,尤其是自部署大模型做 ToC 产品的团队——推理延迟每降一点,用户转化率就能提一大截。
我的评价:这个项目,怎么说呢,就是……就是那种,你一看就觉得"DeepSeek 这帮人是真的在搞事情"的级别。从模型到框架再到推理加速,一条龙全部开源。别的厂商还在靠卖 API 赚钱,DeepSeek 直接把底裤都扒了送你——这境界,服。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

