大家好,我是何三,独立开发者
之前写 RAG 应用的时候,我真的很崩溃。
装个 PostgreSQL 存用户数据,装个 Milvus 做向量检索,再装个 Neo4j 搞知识图谱,最后还得写一堆胶水代码把这些东西串起来。三个数据库,三套 API,三个部署流程,加一个中间层。
一个 AI 应用还没写,光搭基础设施就花了一周。
直到我翻到了这个项目——HelixDB。近 5000 Star(确切是 4.8k+),YC 孵化,Rust 写的,一个数据库同时干了图、向量、KV、文档四件事。
而且,它居然还自带了 MCP 协议支持。
什么意思?你的 AI Agent 可以直接连上它,不需要写任何适配层。
一个数据库,而不是四个
先说我看到这个项目的第一反应。
没懂作者为什么这么设计。图数据库就好好存图,向量数据库就好好做搜索,硬塞到一块儿,不会是缝合怪吧?
看完文档后,我收回这句话。
HelixDB 的核心数据模型是图 + 向量。每个节点可以有属性(像文档),可以连关系(像图),属性上可以建向量索引(像向量库),还能做 BM25 全文检索。
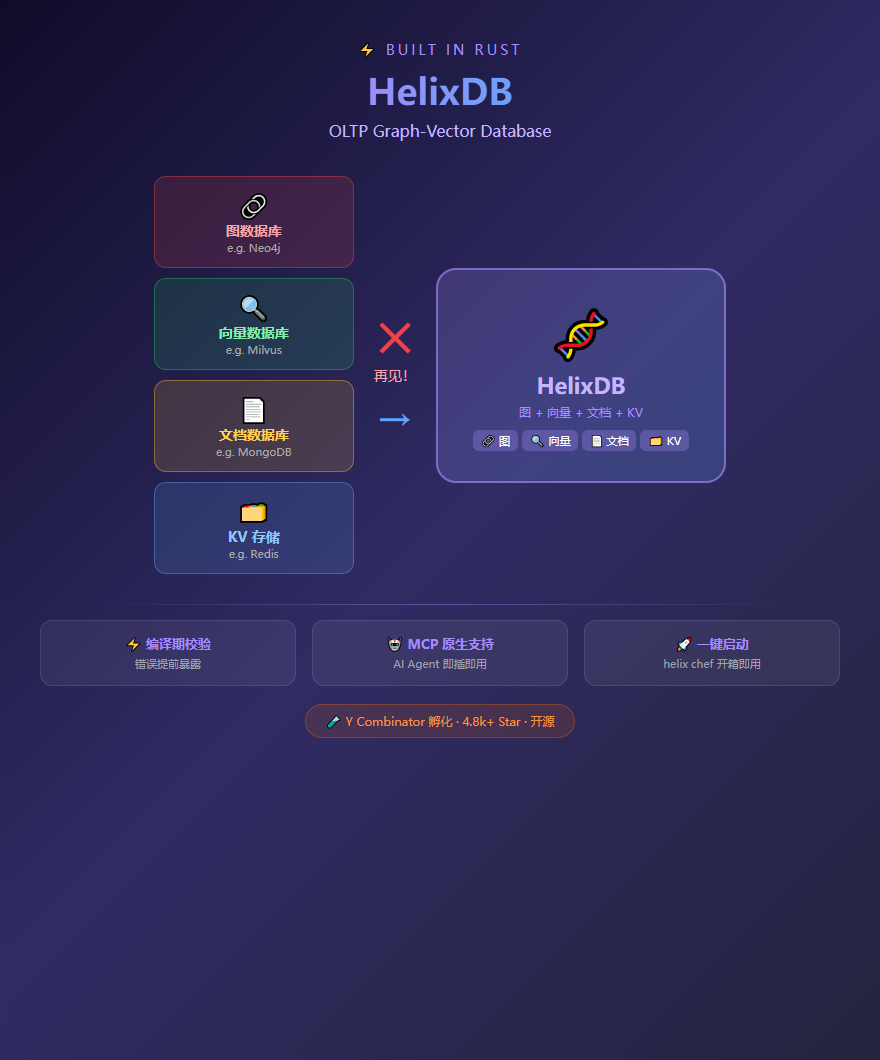
说白了——它用一张底层存储,把四种数据库的事情全干了。你不需要在不同数据库之间倒数据,不需要写 ETL 管道,不需要维护多个集群。
这个思路,怎么说呢……就是那种你一直想要但没人做出来的东西。
装一个顶四个?上手试试
安装体验让我有点意外。
一条命令:
curl -sSL "https://install.helix-db.com" | bash
装完之后,更骚的操作来了——helix chef。
这是个一键引导器。你告诉它你想做什么,它帮你初始化项目、启动本地实例、灌示例数据,甚至——如果检测到你有 Claude Code 或 Codex——它会自动帮你把整个应用搭起来。
我试了一下,输入"建一个知识图谱,存 GitHub 仓库和贡献者的关系,支持语义搜索"。
几分钟后,它生成了一整个能跑的项目。
说真的,用 Rust 写出这玩意儿,真的服。
helix chef
# 然后回答一个自然语言描述
# 它帮你搞定一切
手动启动也不复杂:
mkdir my-helix-app && cd my-helix-app
helix init
helix start dev
默认运行在 localhost:6969。端口都选得这么骚。
用 Rust 写查询?这波操作我没想到
HelixDB 的查询是用 Rust 或 TypeScript 的 DSL 写的。
等等——用宿主语言写数据库查询?
我第一次看到这个设计的时候,说实话,有点懵。
后来理解了它的逻辑:查询在编译期被校验,错误提前暴露,而不是等到运行时才报错。而且 Rust 的宏系统让查询 DSL 用起来极其自然。
use helix_db::Client;
use helix_db::dsl::prelude::*;
#[register]
pub fn add_user(name: String) {
write_batch()
.var_as("user", g().add_n("User", vec![("name", name)])
.value_map(None::<Vec<String>>))
.returning(["user"])
}
#[register]
pub fn get_user(name: String) {
read_batch()
.var_as("user", g().n_with_label("User")
.where_(Predicate::eq("name", name))
.value_map(None::<Vec<String>>))
.returning(["user"])
}
#[tokio::main]
async fn main() {
let client = Client::new(None).unwrap();
let new_user = client
.query::<sonic_rs::Value>()
.dynamic(add_user("John Doe".to_string()))
.send()
.await
.unwrap();
println!("new user: {:#}", sonic_rs::to_string_pretty(&new_user).unwrap());
}
这是 Rust SDK 的写法,增删改查都写在 #[register] 函数里。HelixDB 内部有一个叫 HelixQL 的中间语言,而 SDK 只是把 DSL 编译成这个中间语言再发给服务端。
翻译一下:写代码的时候 IDE 就能提示你写错了,不用等跑起来才报 500。
如果不用 Rust,TypeScript 也支持:
import { g, readBatch, writeBatch, Predicate, PropertyInput } from "@helix-db/helix-db";
function addUser(name: string) {
return writeBatch()
.varAs("user", g().addN("User", { name: PropertyInput.value(name) })
.project(["name"]))
.returning(["user"]);
}
这套 DSL……怎么说呢,刚开始会觉得有点奇怪,习惯了之后发现比写 SQL 还顺手。因为它是类型安全的。
跟 Neo4j 打了一架,还赢了
HelixDB 的团队在博客里发了 benchmark 数据——跟 Neo4j 和 PostgreSQL(用表 join 模拟图关系)做了对比。
结果?在真实的图数据集上,HelixDB 的查询性能全面领先。
当然,benchmark 这东西,看看就好,实际性能取决于你的数据模型。但至少说明它不是来凑数的。
它的向量搜索用的是 HNSW 算法,这是目前最主流的近似最近邻搜索算法——跟 Milvus、Qdrant 这些专用向量库用的是同一套东西。所以向量搜索能力不是"能用"的水平,而是生产级。
MCP 协议:给 AI 智能体准备的礼物
这个才是让我真的觉得"卧槽"的功能。
HelixDB 内置了 MCP(Model Context Protocol) 支持。MCP 是 Anthropic 推的一个标准协议,让 AI Agent 能直接连接外部工具和数据源。
大多数数据库要支持 MCP,得自己写一个中间适配层。而 HelixDB 直接原生支持——你的 AI Agent 可以通过 MCP 直接查询 HelixDB 里的知识图谱,不需要任何胶水代码。
说白了,如果你的 AI 应用需要长期记忆、企业知识库、上下文管理,HelixDB 是市面上少有的开箱即用方案。
同类工具怎么看
这个赛道上,最接近的竞品可能是 Neo4j + 向量插件,或者 SurrealDB(也是一体化数据库)。
Neo4j 做了很多年,生态成熟,但向量搜索是后来加的插件,性能一般,而且——贵。企业版一年几万刀。
SurrealDB 也支持多模型,但用了一种叫 SurrealQL 的自研查询语言,学习成本比 HelixDB 的 Rust/TS DSL 高不少。
HelixDB 的优势很明显: - Rust 写,性能好 - 编译期校验 - MCP 原生支持 - YC 背景,社区活跃
但劣势也有——项目还比较新,生态不如 Neo4j 成熟,中文资料基本没有。
如果只是做个小项目自己玩,用 HelixDB 很爽。如果是大厂核心系统,可能还得观望一下。
觉得这工具有意思?我上周还写过《自建 AI 工作台的 N 种姿势》,关注后回复「ai」就能看到。
GitHub 地址:https://github.com/HelixDB/helix-db
总结
一个数据库顶四个,Rust 写的性能不掉链子,MCP 协议让 AI Agent 开箱即用。
HelixDB 不是那种"能跑就行"的项目,它在设计上的很多选择——编译期查询校验、宿主语言 DSL、MCP 原生支持——都让我觉得,这团队的思路确实不一样。
原理大概就是这样,细节可能有出入——有懂的大佬欢迎指正。
装不装都行,看你自己。但建议你先 star 一下,万一哪天用上了呢。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

