大家好,我是何三,独立开发者。
昨天 Hacker News 上蹦出来一个项目,把我整不会了。
一个叫 Kage(日文"影"的意思)的 Go 项目,发布不到 24 小时,GitHub 就冲到了超 1000 星(精确是 1263 星),HN 上 609 points,冲上首页,评论区 119 条讨论炸开了锅。
做的事听起来有点反常识——把任意网站打包成一个 13MB 的离线二进制文件,而且把所有 JavaScript 都删干净了。
什么意思呢。
你平时用浏览器"另存为"保存一个网页,半年后打开,大概率是一张白纸。要么 JS 加载失败,要么某个 CDN 挂了,要么那个追踪脚本的域名早就没人续费了。你存的不是网页,你存的是个"半成品"——它得联网、得跑 JS、得依赖一堆外部资源才能活。
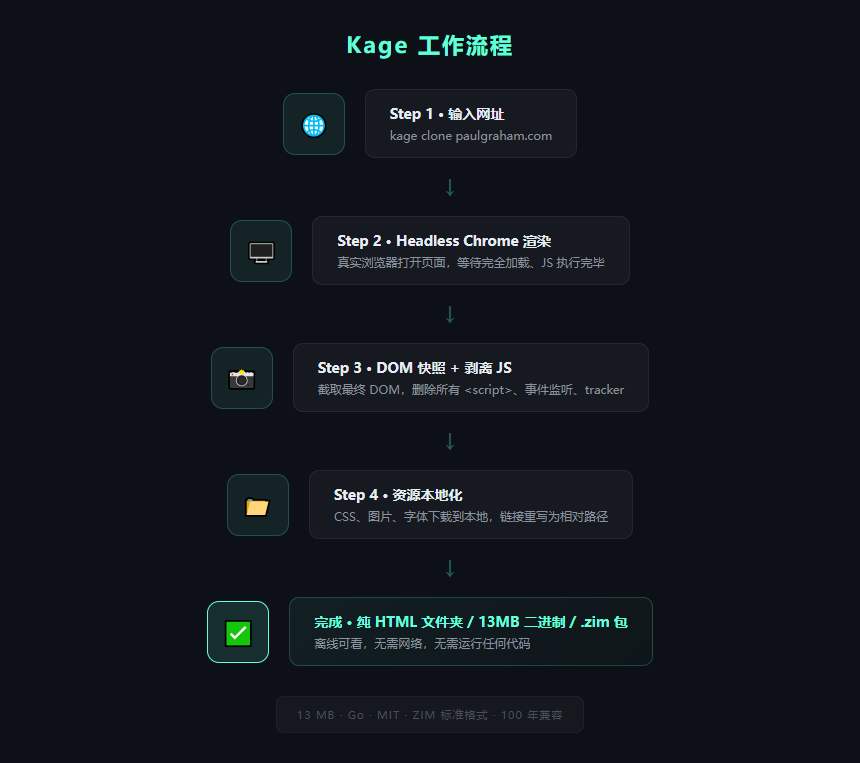
Kage 的思路是:我替你打开 Chrome,等页面彻底渲染完,把 DOM 拍个快照,然后把所有的 JS 脚本、事件监听、tracker 全部撕掉,CSS、图片、字体全部下载到本地改写路径。最后落到你硬盘上的,是一堆纯 HTML 文件。
打开就能看,不需要网络,不需要跑任何代码。
说白了,它给你的不是网页的"尸体",是网页的"影子"——一模一样,但没有重量。
跑题一下,这让我想起以前玩模拟器 ROM 的时候,总有人争论"原盘镜像保留"vs"精简版"。Kage 就是后者——把运行环境砍了,内容完美保留。不过说真的,有些网站没了 JS 就彻底废了,比如 Twitter 或者 Notion。Kage 最适合的是 内容型网站:博客、文档站、wiki、电子书——JS 只是装饰,内容才是本体。
怎么玩?三行命令搞定:
# 1. 把网站"影"下来
kage clone paulgraham.com
# 2. 在本地预览
kage serve ~/data/kage/paulgraham.com
# 打开 http://127.0.0.1:8800
# 3. 打成单个离线包
kage pack paulgraham.com # -> paulgraham.com.zim
看完第三步你可能想问:zim 是什么鬼?
ZIM 是一个开放的离线内容格式,维基百科官方离线版用的就是它。Kiwix 这个项目就是靠 ZIM 格式,让整个 Stack Overflow、整个 Project Gutenberg、甚至整个 Wikipedia 都能塞进一个文件离线看。Kage 打的 ZIM 包,你可以用 Kage 打开,也可以用 Kiwix 打开,甚至扔到手机上用 Kiwix App 看。
也就是说,你今天打的包,100 年后的任何 ZIM 阅读器都能打开。
这还没完。
kage pack 还能打出更离谱的东西——一个 自包含的可执行文件:
kage pack paulgraham.com --format binary -o paulgraham
./paulgraham # 启动本地服务器,浏览器打开就能看
这个二进制只有 13MB 左右(加上网站内容会大一点),发给谁谁就能用。不需要装 Kage、不需要装 ZIM 阅读器、什么都不需要。
你要是想更极致一点,还能打个 双击即用的桌面 App,没有终端窗口那种:
kage pack paulgraham.com --app # macOS 上生成 .app 包
open paulgraham.app # 双击,网站直接以原生窗口打开
为什么这个项目能冲上 HN 首页?说实话,每个开发者都遇到过这种事——想保存一个网页做笔记、想离线看文档、想把公司内部 wiki 打包带走,结果发现"另存为"根本就是个摆设。
不过说实话,这种工具其实不新。以前有 wget --mirror,有 httrack,有各种离线浏览工具。但它们的问题都一样:存下来的页面经常跑不起来,因为资源路径乱了、因为 JS 依赖没抓到、因为渲染结果和在线版不一样。
Kage 的不同在于它用 真正的 Headless Chrome 去渲染,等页面完全跑完再快照式地保存。你看到什么,它就存什么。不是存源码,是存结果。
# 还有一些实用的 flag
kage clone paulgraham.com --max-pages 50 --max-depth 2 # 只抓前 50 页
kage clone go.dev --scope-prefix /doc # 只抓某个目录
kage clone example.com --subdomains --scroll # 包括子域名、自动滚动触发懒加载
kage clone paulgraham.com --refresh # 增量更新,不重复抓已有的
为什么这么设计?别问我,问作者去。反正我今天用起来是真香。
同类工具? SingleFile 浏览器扩展也能保存完整页面,但只能一页一页存,不能爬整个站。wget -mpk 是老牌选手,遇到 SPA、懒加载就抓瞎。Kage 用 Headless Chrome 打底,刚好补了这块短板。
如果你对这类"离线内容存档"感兴趣,我之前还写过一篇《我用 Kiwix 把整个维基百科搬到了飞机上》,关注后回复「离线」可以看看。
项目地址: https://github.com/tamnd/kage
MIT 协议,随便折腾。Go 语言写的,编译出来就一个二进制,装起来也省心。
说实话,我还没拿 Kage 去打过那种重度 JS 的 SPA 应用——比如 Figma 或者 Notion——不知道效果如何。原理上可能不太行,毕竟剥离 JS 后交互逻辑就没了。但如果你试了,欢迎告诉我结果。这玩意儿,怎么说呢,就是……就是那种你存网页的时候一直想要的工具,只是之前没人把它做到这个程度。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

