大家好,我是何三,独立开发者
做爬虫或者自动化测试的朋友,应该都被反检测折磨过。
你辛辛苦苦写了一套 Playwright 脚本,结果目标网站直接给你弹一个 reCAPTCHA,点完红绿灯还得选斑马线、选自行车、选消防栓……选到怀疑人生。
你以为换个浏览器指纹就完事了?
错了。市面上大部分反检测方案,从根上就是错的。
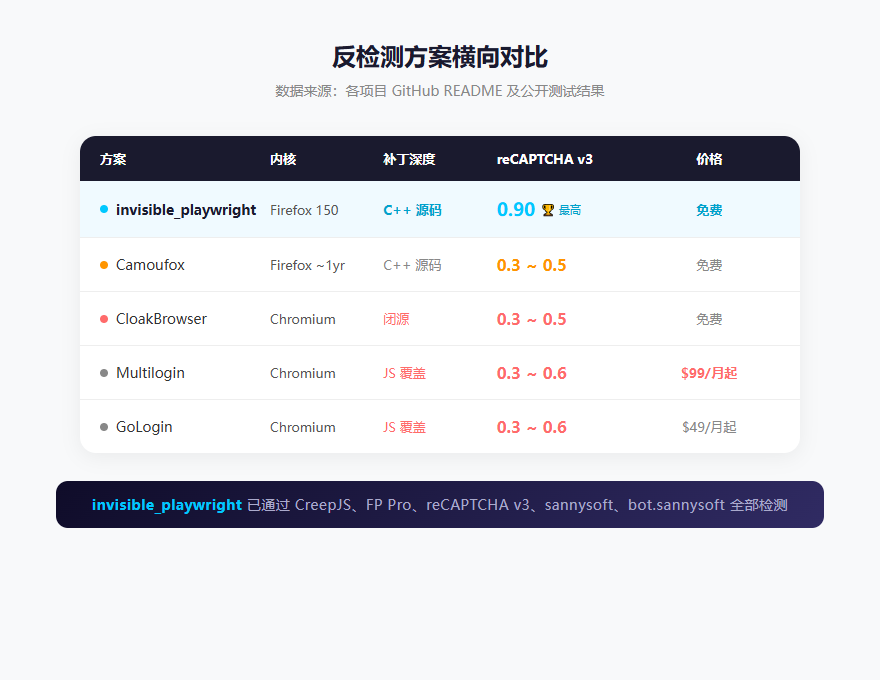
最近 GitHub 上有个项目火了——invisible_playwright,不到一个月拿了近 1500 Star。它的思路简单得离谱:不在 JS 层伪装,直接在 C++ 层改 Firefox 源码。
结果呢?reCAPTCHA v3 分数直接飙到 0.90。对比一下行业平均水平——同类产品一般在 0.3-0.6 之间。
0.9 什么概念?Google 把你当真实用户的概率是 90%。
0.3-0.6 什么概念?Google 会觉得"这货可能是机器人,扔个验证码给它"。
差距就在这里。
大多数反检测方案,都做错了
目前市面上所有的"反检测浏览器",不管是 Multilogin、GoLogin、AdsPower 还是其他什么,核心思路都差不多:
拿一个 Chromium 内核,在 JavaScript 层写一堆 Object.defineProperty 来覆盖 navigator、WebGLRenderingContext、Canvas 这些 API,然后告诉你"你的浏览器指纹变了"。
听着好像没问题对吧?
问题大了。
JS 层的补丁本身就是可以被检测的特征。 反检测工具(比如 CreepJS)有一整套探测器,专门检查函数原生的 .toString() 有没有被改过、属性描述符是不是可配置的、属性枚举顺序是不是正常的……
说白了,你在 JS 层面改的每一个值,都会留下新的指纹。
这就好比你想戴个面具伪装自己,结果面具本身长得太假,反而更引人注目。
另外还有一个更致命的问题——Chromium 本身已经不太行了。现在土拨鼠代理的机器人流量绝大部分都是 Chromium 系的,检测系统看到 Chromium 内核就已经在怀疑你了,权重天然就低。

invisible_playwright 是怎么做的?
这个项目选择了一条完全不同的路:用 Firefox。
不是普通 Firefox,而是在 C++ 源代码层面打过补丁的 Firefox。项目作者维护了另一个仓库叫 invisible_firefox,里面就是魔改后的 Firefox 源码。
所有伪造的指纹信息,走的都是 Gecko 引擎的正常路径返回的。没有 JS shim,没有 Object.defineProperty,没有注入脚本。
从页面的视角来看,这个浏览器就是在"说实话"。
我举个例子你就明白了。普通反检测浏览器的工作方式是:
页面问:你的显卡是什么? 浏览器(JS层拦截):等等,让我改一下答案。嗯,告诉他 RTX 4090。 页面:你这个回答的路径不对啊,你在说谎!
invisible_playwright 的工作方式是:
页面问:你的显卡是什么? 浏览器(C++底层直接返回):RTX 4090。 页面:好嘞,没问题。
区别在哪?前者是"撒谎",后者是"真的变成了那个样子"。
——说实话,这块的原理我也只能说个大概,因为我没本事去改 Firefox 的 C++ 源码。有懂的大佬欢迎指正。
上手体验:真就改两行代码
这个项目最骚的地方在于——它和 Playwright 的 API 完全兼容。
如果你已经在用 Playwright,迁移只需要改两行:
- from playwright.sync_api import sync_playwright
- with sync_playwright() as p:
- browser = p.firefox.launch()
+ from invisible_playwright import InvisiblePlaywright
+ with InvisiblePlaywright() as browser:
然后就完了。
browser 对象就是标准的 Playwright Browser 对象,所有方法照用不误。page.goto()、page.click()、page.screenshot(),跟以前一模一样。
安装也简单:
pip install git+https://github.com/feder-cr/invisible_playwright.git
python -m invisible_playwright fetch
第一次运行会下载一个大概 100MB 的魔改 Firefox 二进制包,之后就能直接用了。
每次启动,它会从真实 Firefox 遥测数据中采样,自动生成一套独特的浏览器指纹——包括 GPU、音频、字体、屏幕分辨率、硬件并发数等 400 多个字段。
而且鼠标轨迹也是贝塞尔曲线的,不是那种机械的"从 A 直接瞬移到 B"。
from invisible_playwright import InvisiblePlaywright
with InvisiblePlaywright(proxy={"server": "socks5://...", "username": "u", "password": "p"}) as browser:
page = browser.new_page()
page.goto("https://creepjs-api.web.app")
page.click("#submit") # 鼠标沿着贝塞尔曲线滑过去
想要复现同一个指纹?加个 seed 参数就行:
with InvisiblePlaywright(seed=42) as browser:
# 每次运行指纹都一样
说到反检测,不得不提几个同行:
Camoufox——同样是基于 Firefox 魔改的开源方案,也走 C++ 源码路线。但它用的是大概一年前的 Firefox 基线,而 invisible_playwright 用的是最新的 Firefox 150。而且 Camoufox 的 reCAPTCHA 分数大概在 0.3-0.5,差距还是挺明显的。
arkenfox/user.js——Firefox 隐私安全配置的权威指南,通过 user.js 改配置来加固浏览器。但它只能在配置层面做文章,碰到需要改 C++ 源码的地方就没办法了。
至于商业方案,Multilogin 起价 $99/月,还是 JS 层覆盖,reCAPTCHA 分数也就 0.3-0.6。说实话,看到这个对比我有点心疼那些花钱买服务的人。
如果你对浏览器自动化感兴趣,我此前还整理过一些相关的内容——不过今天这篇应该够你消化了。
总结
invisible_playwright 这个项目最值钱的地方,不是它通过了多少检测,而是它选了一条完全不同的技术路线。当所有人都在 Chromium + JS shim 的赛道上卷生卷死的时候,作者直接跑到 Firefox C++ 源码层面重新做了。
这种"你们在错误的路上越走越远,我换个赛道重新开始"的思路,本身就是一种享受。
项目地址:https://github.com/feder-cr/invisible_playwright
装不装都行,看你自己。但如果你正在被反检测困扰——试试又不花钱。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

