大家好,我是何三,独立开发者
30MB 内存跑一个浏览器,页面加载 51ms。
你没看错,这不是什么阉割版、也不是命令行单色模式——这是一个完整的无头浏览器,支持 V8 JavaScript 引擎,兼容 Puppeteer 和 Playwright,甚至内置反指纹检测。对比之下,Headless Chrome 光启动就得 2 秒,吃 200MB 内存跟喝水一样。
这就是 Obscura,一个用 Rust 写的开源无头浏览器。发布 13 天,狂揽近 6 千 Star。
为什么会有这个东西
说实话,做爬虫或者 AI Agent 的同学,应该都跟我一样被 Chrome Headless 折磨过。
装个 Chrome 几百兆,跑一个页面就吃掉 200 多 MB 内存。你要是并发开 10 个标签页,好家伙,2GB 没了。服务器上跑个爬虫,内存先被浏览器干了一半。
更离谱的是反爬。你想正经抓个数据,对面一看 navigator.webdriver 就知道你是自动化工具,一顿验证码伺候。得,还得再套一层 undetected-chromedriver。
Obscura 的作者的感受估计跟我差不多——只不过他选择自己写一个。
用 Rust 从头撸了一个无头浏览器。单二进制文件,70MB,没有任何依赖。装完就能跑。
它是怎么做到的
原理其实不复杂——但我得说实话,细节我也没全搞懂,Rust 编译 V8 那边太硬核了。
大概的逻辑是这样的:Obscura 用 Rust 封装了 V8 引擎(就是 Chrome 那个 JS 引擎),实现了 Chrome DevTools Protocol(CDP)的接口。CDP 是个啥?就是 Chrome 的"远程遥控协议",Puppeteer 和 Playwright 都是通过它来操控浏览器的。
所以 Obscura 做的事情就是:用 Rust 实现了一套 CDP 服务端,然后把 V8 嵌进去跑 JS。
你通过 Puppeteer 连上它,发一个 page.goto(),它就用 V8 渲染页面,然后通过 CDP 把结果返回给你。整个过程不需要 Chrome、不需要 Node.js、不需要任何外部依赖。
一个二进制 = 浏览器引擎 + JS 引擎 + CDP 服务 + 反爬模块。
说到这个我突然想到一个事儿——你们知道最早的 headless browser 是什么吗?是 PhantomJS,2011 年出的,后来被 Chrome Headless 干掉了。那哥们也是一个人写的,后来发现 Chrome 自己出了官方的,心态直接崩了,宣布归档。现在回头看,用 Rust 重写整个浏览器引擎这条路,当年根本没人敢想。
上手体验:真·一行命令
装 Obscura 就一句话:
curl -LO https://github.com/h4ckf0r0day/obscura/releases/latest/download/obscura-x86_64-linux.tar.gz
tar xzf obscura-x86_64-linux.tar.gz
解压完直接跑:
# 抓个页面标题
./obscura fetch https://news.ycombinator.com --eval "document.title"
输出:
Hacker News
这就完了。没有 Docker,没有 apt install,没有 npm install,没有环境变量配置。
想拿链接?
./obscura fetch https://news.ycombinator.com --dump links
也支持并发爬取:
./obscura scrape url1 url2 url3 --concurrency 25 --format json
25 个页面同时抓,每个页面 85ms 搞定。这速度——怎么说呢,就是那种你泡杯咖啡回来,数据已经全部写进 CSV 了。
用 Puppeteer 连
如果你习惯了 Puppeteer 的 API,完全不用改代码:
import puppeteer from 'puppeteer-core';
const browser = await puppeteer.connect({
browserWSEndpoint: 'ws://127.0.0.1:9222/devtools/browser',
});
const page = await browser.newPage();
await page.goto('https://news.ycombinator.com');
// 剩下操作跟用 Chrome 一模一样
反爬有多猛
这是我最服的地方。Obscura 内置了一套反指纹检测系统:
navigator.webdriver=undefined(真正的 Chrome 长这样)Function.prototype.toString()返回[native code],不会被 detect- 每个 session 的 GPU、屏幕、Canvas、Audio 指纹都会随机化
- 内置 3,520 个追踪器域名拦截名单
说白了,你用 Obscura 去抓数据,对面网站怎么查都以为是个真人用 Chrome 在访问。
性能数据到底多炸裂
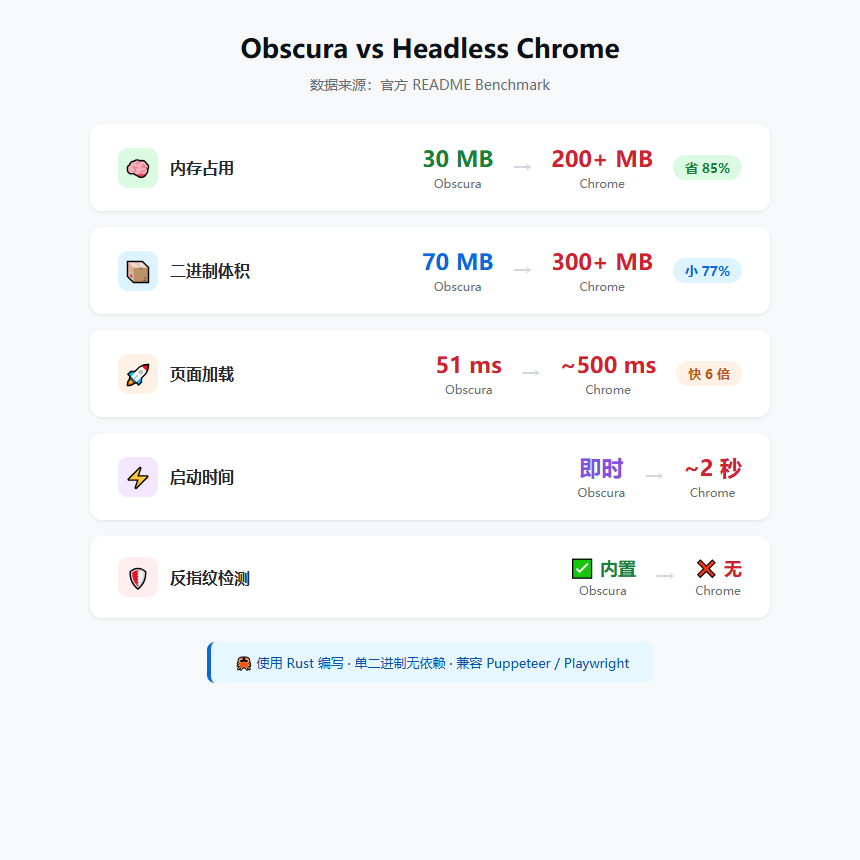
官方给了 Benchmark,我直接复述一遍:
| 场景 | Obscura | Headless Chrome |
|---|---|---|
| 静态 HTML 加载 | 51 ms | ~500 ms |
| JS + XHR + fetch | 84 ms | ~800 ms |
| 动态脚本渲染 | 78 ms | ~700 ms |
| 内存占用 | 30 MB | 200+ MB |
| 二进制大小 | 70 MB | 300+ MB |
| 启动时间 | 即时 | ~2 秒 |
快 6 倍、省 85% 内存、没有依赖。
— 等等我要再次强调一下这个"没有依赖"到底意味着什么。你想想,你在服务器上部署一个爬虫,要先装 Chrome,再装 ChromeDriver,再装 Selenium,再装 undetected-chromedriver……一套下来快 1GB 了。Obscura 一个二进制文件,70MB,搞定全部。这个压缩率——算了先不说这个,你先装上看效果。
同类工具
说到无头浏览器这股风潮,其实最近 Rust 生态里冒出来好几个类似的项目,各有各的思路:
- browserless(Node.js):封装了 Chrome 的无头服务,但底层还是 Chrome。
- Playwright(微软维护):功能最强,但依赖 Chromium,一套装下来 400MB+。
- Headless Chrome(谷歌官方):最正统,但最重,且反爬能力为 0。
Obscura 的差异化在于:它不是"套壳 Chrome",而是从底层用 Rust 重写了一个浏览器引擎。这就像——你本来租房子住(用 Chrome),现在自己盖了一栋(用 Rust 写浏览器),虽然面积小点,但物业费、装修、邻居(依赖)全都省了。
说点缺点
也不是什么都好。
Obscura 目前还在早期阶段,CDP 实现的接口有限。我试了几个高级功能,比如 Network 请求拦截、page.setRequestInterception,目前还不太稳定。
文档嘛……怎么说呢,写得跟谜语人似的。README 里 CLI 参数倒是写全了,但 API 的详细说明基本没有,全靠你自己试。
为什么这么设计?别问我,问作者去。
不过考虑到这个项目才发布 13 天,已经干了这么多事,我觉得给它一点成长时间也合理。
最终总结
Obscura 解决了一个极其具体的痛点:大规模自动化场景下,Chrome 太重了。
如果你的需求是:
- 写爬虫抓数据,反爬让你头疼
- 跑 AI Agent,需要浏览器环境但不想装 Chrome
- 做大规模网页截图/渲染,内存是瓶颈
- 想体验一下"用 Rust 从头写一个浏览器"是什么概念
那 Obscura 值得你花 5 分钟装上试试。
装不装都行,看你自己——但装了之后,你可能会跟我想的一样:原来浏览器可以这么轻。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

