大家好,我是何三,独立开发者
当 NVIDIA 开始写 Rust
先交代一下背景——这个叫 cuTile-rs 的项目,是 NVIDIA 实验室(NVlabs) 出的,用 Rust 写了一个能在 GPU 上跑内核程序的 DSL(领域特定语言)。
听起来像是个学术玩具?
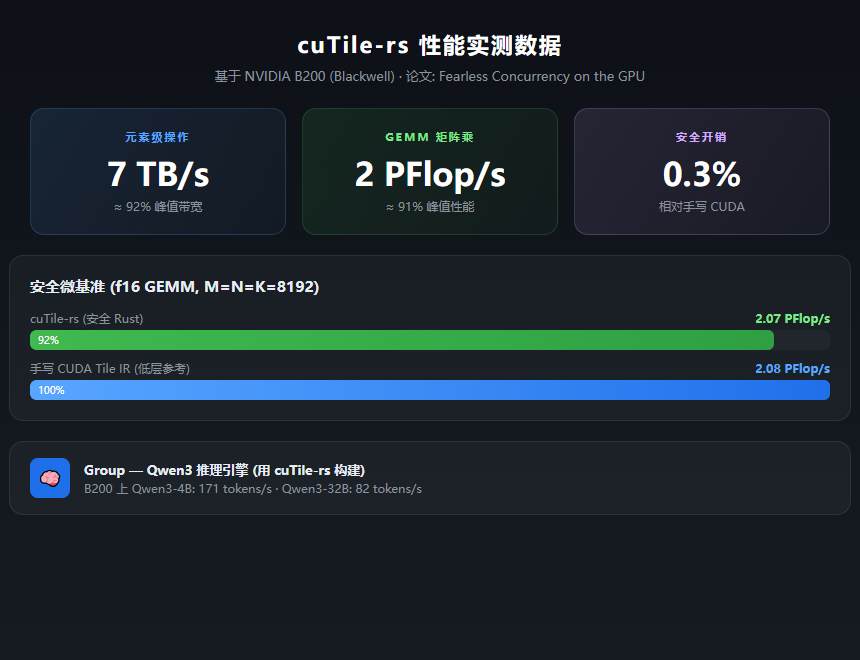
那你看看这组数据:在 NVIDIA B200 上,它跑到了 7 TB/s 的元素级操作,2 PFlop/s 的 GEMM,大概是峰值的 91%-92%。
等于说安全拉满了,性能没怎么掉。
近 500 Star(精确是 484 Star),刚上线三个月,论文已经挂 arxiv 了。NVIDIA 官方下场搞 Rust 写 CUDA,这事儿本身就很离谱。
所以到底解决了什么问题?
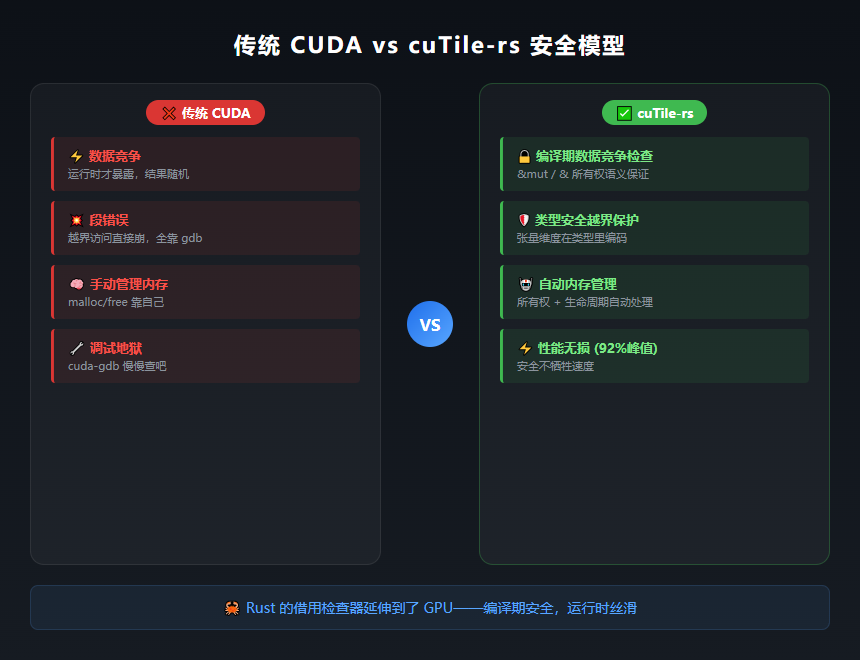
写过 CUDA 的都知道,GPU 编程最大的痛不是性能,是调试。
数组越界?段错误。数据竞争?跑出来的结果每次不一样。内存泄漏?你根本不知道 GPU 上哪个指针没释放。
这些东西在 CPU 上,Rust 的编译器早就帮你堵死了。但 GPU 不行——CUDA 本质上还是 C++ 那套手动管理的老路子。
cuTile-rs 干的事,说白了就一句话:把 Rust 的借用检查器搬到了 GPU 上。
你写内核函数的时候,输入张量是只读共享的,输出张量是独占可变的——这些都在编译期确定。跑之前就知道不会炸。
以前你写 CUDA,出错了只能一点点查,像大海捞针。现在 Rust 编译器在你编译的时候就告诉你"这里可能越界",像多了个保安盯着你写代码。
这东西,怎么说呢,就是……就是那种你第一次看到的时候会"啊?还能这样?"的感觉。
跑题一下——关于 NVIDIA 做 Rust 这件事
说到这儿我突然想起来,NVIDIA 其实在 Rust 生态里布局挺久了。
之前就有 cuda-oxide(一个实验性的 Rust-to-CUDA 编译器),还有 cuda-bindings(Rust 的 CUDA 绑定层)。这次 cuTile-rs 等于把之前那些东西整合升级了。
为什么 NVIDIA 要做这个?
说实话,这块我也没完全搞懂……但大概率是因为 AI 框架越来越复杂,底层的安全要求越来越高。你想想,Qwen3 这种大模型跑在 GPU 上,如果底层内核有数据竞争,训练出来的模型参数都是错的——那谁受得了。
cuTile-rs 论文里提到的 Group(Qwen3 推理引擎,也是用 Rust + cuTile-rs 写的),在 B200 上跑出了 171 tokens/s 的速度。这说明它不是玩具,是真的能拿去干活的。
看看代码长啥样
直接上例子,感受一下:
use cutile::prelude::*;
#[cutile::module]
mod kernel {
use cutile::core::*;
#[cutile::entry()]
fn add<const B: i32>(
z: &mut Tensor<f32, { [B] }>,
x: &Tensor<f32, { [-1] }>,
y: &Tensor<f32, { [-1] }>,
) {
let tx = load_tile_like(x, z);
let ty = load_tile_like(y, z);
z.store(tx + ty);
}
}
fn main() -> Result<(), Error> {
let x = api::ones::<f32>(&[1024]);
let y = api::ones::<f32>(&[1024]);
let z = api::zeros::<f32>(&[1024]).partition([128]);
let (_z, _x, _y) = kernel::add(z, x, y).sync()?;
Ok(())
}
看到了吧,z 是 &mut(可变引用),x 和 y 是 &(不可变引用)——这就是 Rust 的所有权语义直接在 GPU 代码里用了。
那个 #[cutile::entry()] 宏会把 add 函数编译成一个 GPU 内核。运行时通过 JIT 编译成 CUDA 的 cubin,直接在 GPU 上跑。
partition([128]) 的意思是,把 1024 个元素的张量切成 8 个 tile(128 一组),每个 tile 由一个线程块处理。网格大小 (8, 1, 1) 自动从分区推断。
以前你得手动写 CUDA 的
<<<grid, block>>>那一大坨配置,现在你只需要说"我要怎么切数据",剩下的框架帮你搞定。
想跑起来的,一条命令就行:
cargo run -p cutile-examples --example saxpy
前提是你装了 CUDA 13.3 和 Rust 1.89+。NVIDIA 的卡需要 sm_80+(也就是 Ampere 架构及以上)。
cuTile-rs 不是一个人在战斗,它的生态里还有这些:
- cuTile Python — 给 Python 用户用的 tile 内核编程接口,适合不想写 Rust 但想用 tile 思路的人
- TileGym — NVIDIA 官方的 CUDA Tile 内核示例和调优模式集合,学习资料
- cuda-oxide — NVlabs 之前的实验性 Rust-to-CUDA 编译器,可以理解为 cuTile-rs 的前身
- Group — Hugging Face 做的 Qwen3 推理引擎,用 cuTile-rs 构建,证明了这东西能上生产
如果你对 Rust 和 GPU 的交集感兴趣,我此前还整理过《2026 年高性能计算工具清单》,关注后回复"工具"获取。
GitHub 地址在这里:https://github.com/NVlabs/cuTile-rs
总结一下
cuTile-rs 是那种"不起眼但后劲很大"的项目。目前星数不多(近 500),但 NVlabs 出品、论文已发、性能数据扎实,底子很硬。
装不装都行,看你自己。
但如果你正在做 GPU 编程,并且被 CUDA 的段错误折磨到崩溃——我建议你关注一下这个项目。也许半年后,它就是 Rust GPU 生态里绕不开的一环了。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

