

Karpathy 发话了:别搞 RAG。这个近 1200 Star 的桌面应用太离谱了
大家好,我是何三,独立开发者 你用 ChatGPT 上传过一堆文件,然后让它回答问题吧? 那种体验,用一次还行,用多了就会发现一个很烦的事:它每次都在"重新发现"你喂给它的知识。你上周问过的问题,这周...
大家好,我是何三,独立开发者 你用 ChatGPT 上传过一堆文件,然后让它回答问题吧? 那种体验,用一次还行,用多了就会...

14年磨一剑,近3.7万Star!这个Rust浏览器引擎终于能当库用了
大家好,我是何三,独立开发者 昨天刷 HN 的时候看到一个帖子,413 赞,137 条评论,标题只有一行字: "Servo is now available on crates.io" 搁以前我可能就...
大家好,我是何三,独立开发者 昨天刷 HN 的时候看到一个帖子,413 赞,137 条评论,标题只有一行字: "Servo...

近 4 万 Star!免费用 Claude/ChatGPT 订阅驱动,这个 Rust 写的 AI Agent 太狠了
大家好,我是何三,独立开发者 你花几十块甚至几百块买的 Claude Pro、ChatGPT Plus 订阅,居然可以拿来白嫖一个开源 AI Agent——不用额外掏一分钱 API 费用。 这个项目叫...
大家好,我是何三,独立开发者 你花几十块甚至几百块买的 Claude Pro、ChatGPT Plus 订阅,居然可以拿来...

近2万Star!写完PRD就睡觉,AI自动写代码到天亮,程序员的饭碗要被砸了?
大家好,我是何三,独立开发者 近 2 万 Star 的一个项目,GitHub 上最近炸了。叫 Ralph,一个让你写完需求文档就去睡觉、AI 自己写到天亮的东西。 你可能会说,这不就是 Cursor ...
大家好,我是何三,独立开发者 近 2 万 Star 的一个项目,GitHub 上最近炸了。叫 Ralph,一个让你写完需求...
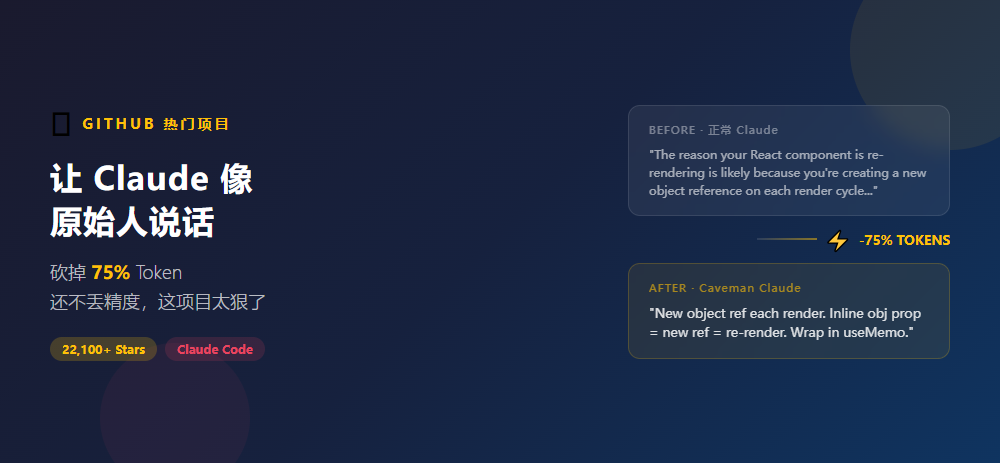
2万+ Star!让 Claude 像原始人说话,砍掉 75% Token 还不丢精度,这项目太狠了
大家好,我是何三,独立开发者 用 Claude Code 写代码的开发者,账单上的 Token 数字应该都不陌生——动不动就几万 Token 一个请求,月底账单看得心梗。 有个叫 Julius Bru...
大家好,我是何三,独立开发者 用 Claude Code 写代码的开发者,账单上的 Token 数字应该都不陌生——动不动...

近 2.5 万 Star!比 MinIO 快 2.3 倍,这个 Rust 写的对象存储让云成本砍半
大家好,我是何三,独立开发者 比 MinIO 快 2.3 倍。 就这一句话,我觉得就够让你点进来了。 云存储这东西,说重要吧,天天用。说烦人吧,也是真的烦。特别是小文件读写,4KB 这种尺寸,MinI...
大家好,我是何三,独立开发者 比 MinIO 快 2.3 倍。 就这一句话,我觉得就够让你点进来了。 云存储这东西,说重要...

$29/月 → 0元!录屏神器 Screen Studio 终于有了开源平替,近 3 万 Star
大家好,我是何三,独立开发者 Screen Studio 卖 $29/月,GitHub 上有个叫 OpenScreen 的项目拿了 28.4k Star(约 2.8 万),干的是同样的事——录屏 + ...
大家好,我是何三,独立开发者 Screen Studio 卖 $29/月,GitHub 上有个叫 OpenScreen 的...
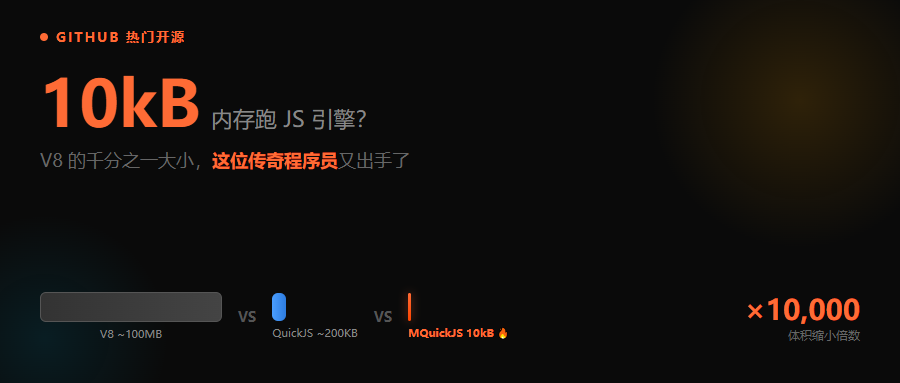
10kB 内存跑 JS 引擎?V8 的千分之一大小,这位传奇程序员又出手了
大家好,我是何三,独立开发者 mquickjsassets/mquickjs_cover.png 曾在 Hacker News 首页被一个项目刷屏了——1500+ upvote,569 条评论,讨论热...
大家好,我是何三,独立开发者 mquickjsassets/mquickjs_cover.png 曾在 Hacker Ne...

近 2.5 万 Star!Claude Code 每月省下 80% Token,这个 Rust 工具太狠了
大家好,我是何三,独立开发者 你的 Claude Code 账单,可能有一半在烧冤枉钱 用 Claude Code 写了一天代码,回头一看 Token 消耗——11.8 万。其中 8 万多是 git ...
大家好,我是何三,独立开发者 你的 Claude Code 账单,可能有一半在烧冤枉钱 用 Claude Code 写了一...

手动改 5 份 JSON → 右键切换,这 11MB 的工具凭什么 4 万+ Star?
coverassets/cc_switch_cover.png 大家好,我是何三,独立开发者 说句大实话——2025 年这波 AI 编程工具的爆发,所有人都爽到了,但也都被折腾到了。 Claude C...
coverassets/cc_switch_cover.png 大家好,我是何三,独立开发者 说句大实话——2025 年这...

手表上跑大模型?Google 这个 3000+ Star 的框架太离谱了,首 token 不到 1 秒
大家好,我是何三,独立开发者 litertlmassets/litertlm_cover.png 你有没有想过,一个手表上能跑大模型? 不是那种"阉割版"的文本分类器,而是正儿八经的语言模型,能聊天、...
大家好,我是何三,独立开发者 litertlmassets/litertlm_cover.png 你有没有想过,一个手表上...

近 10 万 Star!一行命令把 PDF、Word、Excel 全转成 Markdown,AI 吃文档终于不翻车了
大家好,我是何三,独立开发者 做过 RAG 的人都知道这个痛 如果你搭过 RAG(检索增强生成)系统,一定踩过同一个坑——把 PDF 丢给 AI,然后看着它一本正经地胡说八道。 这不是 AI 的问题,...
大家好,我是何三,独立开发者 做过 RAG 的人都知道这个痛 如果你搭过 RAG(检索增强生成)系统,一定踩过同一个坑——...

24.4K Star!这份Claude Code保姆级教程,90%的人装完就吃灰
大家好,我是何三,独立开发者 Claude Code装了,然后呢? 说个扎心的事实。Claude Code发布到现在,不少开发者装完之后的状态就是——打几个claude命令,聊几句,然后...不知道还...
大家好,我是何三,独立开发者 Claude Code装了,然后呢? 说个扎心的事实。Claude Code发布到现在,不少...

19k Star!这个开源零信任平台,凭什么让开发者抛弃 Tailscale?
大家好,我是何三,独立开发者 19k Star,又一个 WireGuard 零信任项目火了!Pangolin 凭什么让开发者抛弃 Tailscale? pangolin_coverassets/pan...
大家好,我是何三,独立开发者 19k Star,又一个 WireGuard 零信任项目火了!Pangolin 凭什么让开发...

37.8k Stars的AI渗透测试神器,一条命令自动化挖洞,安全圈炸了
大家好,我是何三,独立开发者 shannon_coverassets/shannon_cover.png 你有没有过这种体验:CI/CD流水线跑得飞快,代码天天在上线,但渗透测试?一年一次,等报告等到...
大家好,我是何三,独立开发者 shannon_coverassets/shannon_cover.png 你有没有过这种体...

