大家好,我是何三,独立开发者
用 Claude Code 写代码的开发者,账单上的 Token 数字应该都不陌生——动不动就几万 Token 一个请求,月底账单看得心梗。
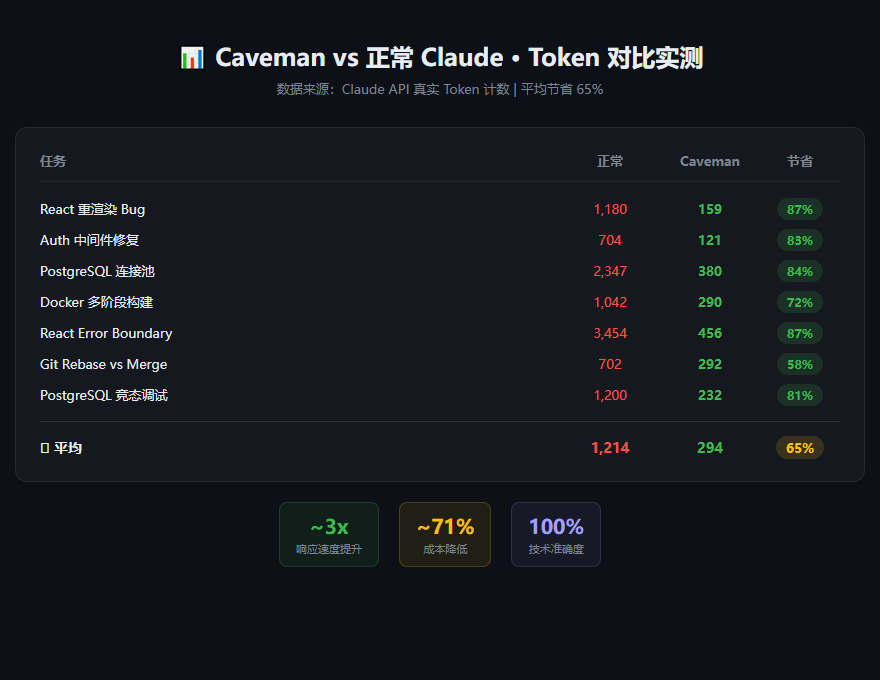
有个叫 Julius Brussee 的开发者发现了一个离谱的现象:如果你让 Claude 像原始人一样说话,不完整的句子、没有冠词、把废话全砍掉——Token 用量能直接砍掉 65% 到 87%,而且技术准确度完全不变。
他把这个发现做成了一个开源插件,叫 caveman。
一个星期不到,2 万多 Star。我现在用的就是 caveman 模式,说实话效果确实离谱。
这东西到底在干嘛
caveman 本质上是 Claude Code / Cursor / Codex 这些 AI 编程助手的一个 skill(技能插件)。安装之后,AI 的输出风格会变成"原始人说话":
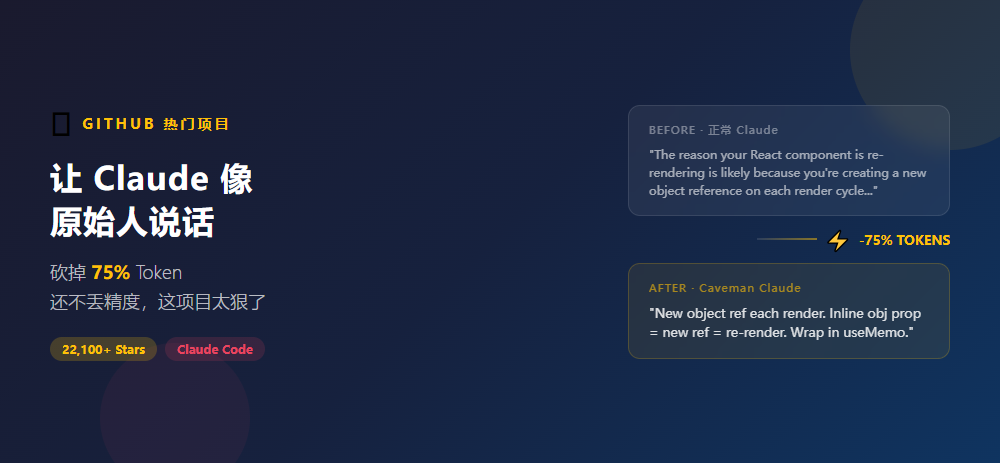
Normal Claude 69 个 Token:
"The reason your React component is re-rendering is likely because you're creating a new object reference on each render cycle. When you pass an inline object as a prop, React's shallow comparison sees it as a different object every time, which triggers a re-render. I'd recommend using useMemo to memoize the object."
Caveman Claude 19 个 Token:
"New object ref each render. Inline object prop = new ref = re-render. Wrap in useMemo."
同一个答案,Token 少了 72%,信息量一模一样。
说白了,就是把 Claude 输出里的"废话"全部砍掉——冠词(the/a/an)、寒暄(Sure! I'd be happy to help)、铺垫(The reason is likely because)、废话转折词(just/really/basically),全部剔除,只留下技术骨架。
四个强度,还有文言文模式
这项目让我觉得很懂程序员的地方在于,它不是一个"原始人模式"走天下,而是给了四个挡位:
| 等级 | 效果 |
|---|---|
| Lite 🪶 | 去掉填充词,保留正常语法。像精简版的技术文档 |
| Full 🪨 | 默认档。砍冠词、用碎片句、原始人完全体 |
| Ultra 🔥 | 极限压缩。电报式,缩写一切 |
| 文言文 📜 | 用古汉语回复,人类发明的最省 Token 的文字 |
文言文模式这个点我真的吹爆。你想想,文言文本来就是极致压缩的信息载体——"物出新參照,致重繪。useMemo Wrap之。" 12 个字把 React 重渲染的根因和解决方案全交代了。
而且有意思的是,2026 年 3 月有篇论文叫《Brevity Constraints Reverse Performance Hierarchies in Language Models》,发现限制大模型使用简短回复,反而让准确率提升了 26 个百分点。也就是说啰嗦不一定等于好,少说点废话,模型反而更靠谱。
这让我想起之前看过的一个观点:人类专家写的技术文档和菜鸟写的技术文档,最大区别不是信息量,而是菜鸟会写一大堆"我们不难发现""综上所述"的废话来凑字数。Claude 之前也有这个毛病,caveman 就是给它做了个"废话切割手术"。
上手体验
安装非常简单,一行命令的事儿。
Claude Code 用户:
claude plugin marketplace add JuliusBrussee/caveman && claude plugin install caveman@caveman
Cursor / Windsurf / Cline / Copilot 用户:
npx skills add JuliusBrussee/caveman -a cursor
Gemini CLI 用户:
gemini extensions install https://github.com/JuliusBrussee/caveman
装完就能用了。在 Claude Code 里直接输入 /caveman 激活,或者干脆说"talk like caveman"也行。
想关掉就说"stop caveman"或"normal mode",随时切换。
三个附带的 skill 也挺实用:
- caveman-commit:生成精简的 commit message,不超过 50 字,聚焦"为什么改"而不是"改了什么"
- caveman-review:一行式 PR review,比如
L42: 🔴 bug: user null. Add guard.,不废话 - caveman-compress:把 CLAUDE.md 等记忆文件压缩成 caveman 语言,连输入 Token 都省——平均压缩 46%
这个 caveman-compress 有点东西。你知道 CLAUDE.md 每次会话都要加载一次吗?如果你的项目上下文文件很长,每次会话都在浪费输入 Token。caveman-compress 把它压缩成 caveman 风格,Claude 每次启动读的就少了,但又不会丢信息。原始文件会备份成 .original.md,你照常编辑就行。
不完美的点也得说说
公平起见,这东西也有局限:
-
只影响输出 Token,不影响思考 Token。Claude 的"深度思考"(thinking/reasoning)部分是完全不动的。caveman 不会让模型变笨,但也别指望它帮你省掉那些推理费用。
-
不是所有任务都省得多。基准测试里,"callback 重构为 async/await"只省了 22%,"微服务 vs 单体架构讨论"只省了 30%。对于本身就是密集信息型的任务,压缩空间天然就小。
-
文言文模式偶尔会有理解障碍。怎么说呢,就是当你问一个特别抽象的架构问题,Claude 用古汉语回答的时候,你得……仔细品一下。不是每次都能一眼看懂。
-
克隆体多。目前 Fork 数已经超过 1k 了,GitHub 上搜 caveman 可能会找到一堆改过一两个字的山寨版,认准 JuliusBrussee 的原版就行。
原理大概就是这样,细节可能有出入——有懂的大佬欢迎指正。
值得装吗
我的结论是:强烈推荐。
尤其是如果你是 Claude Code 重度用户,每个月 Token 账单看了心痛的,装一个零成本、一行命令的事儿。哪怕不为了省钱,单是"不用看 AI 说废话"这一点,体验提升就很明显。
而且——这一点我觉得很多人会忽略——caveman 模式下 Claude 的回复速度明显快了。Token 少了 75%,生成速度自然就上去了。这个体感差异是实实在在的。
GitHub 地址我放这里了,顺手 Star 一个吧:
JuliusBrussee/caveman — 🪨 why use many token when few do trick
【同类工具推荐】
如果你是 Claude Code 生态的用户,我之前还推荐过一个叫 RTK 的项目,近 2.5 万 Star,专干一件事:在命令输出到达 LLM 之前,先帮你「减肥」。30 分钟的 Claude Code 会话,Token 消耗从 11.8 万砍到 2.4 万,省了 80%。
如果你对 AI 编程工具这一块有持续关注的需求,关注"何三笔记"后续分享多类似工具。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

