大家好,我是何三,独立开发者

你有没有想过,一个手表上能跑大模型?
不是那种"阉割版"的文本分类器,而是正儿八经的语言模型,能聊天、能看图、还能调用工具。
Google 最近开源了一个叫 LiteRT-LM 的项目,3000+ Star,GitHub 上 Google AI Edge 团队的作品。
说白了,这玩意儿干了一件很多人觉得离谱的事:把大模型塞进了手表、浏览器和树莓派里,而且已经在 Chrome、Chromebook Plus 和 Pixel Watch 上正式跑起来了。
不是 Demo,是生产环境。
为什么这件事很重要
跑大模型,大家的第一反应是:搞台 A100,或者至少租张 4090。
但现实是,大量场景根本不需要那么重的算力。你想在手机上离线翻译、在手表上识别语音指令、在嵌入式设备上做文本分类——这些场景要的不是参数量,而是能在本地跑得动。
市面上做端侧推理的方案不少:llama.cpp、MLC-LLM、ONNX Runtime……但 Google 这回下场的方式有点不一样。
LiteRT-LM 直接从底层 C++ 写起,专门针对移动端和嵌入式设备的 GPU/NPU 做了深度优化。 不是把桌面端的方案"裁剪"一下就扔过来,而是为端侧量身打造的。

简单翻译一下就是:别人是在 PC 上改改就往手机上搬,Google 是从芯片层面开始为手机设计。
这差别有多大呢?打个比方——就好比别人是拿大卡车改装成送快递的小车,Google 是直接造了一台快递车。
核心能力拆解
看了一圈这个项目,我觉得有几个点特别值得关注:
1. 一个框架覆盖所有端
Android、iOS、Web、桌面端(Linux/Windows/macOS)、甚至树莓派和 IoT 设备。你写一次代码,模型就能在所有平台上跑。这对做跨平台应用的开发者来说简直是福音。
2. NPU 真的在用力
不是那种"声明支持 NPU"然后实测没加速的方案。LiteRT-LM 在 v0.7.0 就加入了 NPU 加速支持,专门针对移动端芯片做了调优。这意味着在你的手机上跑模型,能真正利用上硬件的 AI 加速能力,而不是纯靠 CPU 硬扛。
3. 多模态和 Function Calling 都有
不只是文本输入,还支持视觉和音频输入。更关键的是支持 Function Calling——也就是说,你完全可以在端侧搭建一个 Agent 工作流。在本地跑 Agent,这个思路本身就很有意思。
4. Gemma 4 已经支持
Google 最新的 Gemma 4 模型,LiteRT-LM 已经第一时间跟进适配了。包括 Llama、Phi-4、Qwen 这些主流开源模型也都在支持列表里。
动手试试
想快速体验一下,其实特别简单。
先装一下 Python 的包管理工具 uv(如果你还没装的话):
# 安装 uv(macOS/Linux)
curl -LsSf https://astral.sh/uv/install.sh | sh
# Windows 用 PowerShell
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
然后一行命令安装 CLI:
uv tool install litert-lm
跑起来也只需要一条命令:
litert-lm run \
--from-huggingface-repo=google/gemma-3n-E2B-it-litert-lm \
gemma-3n-E2B-it-int4 \
--prompt="What is the capital of France?"
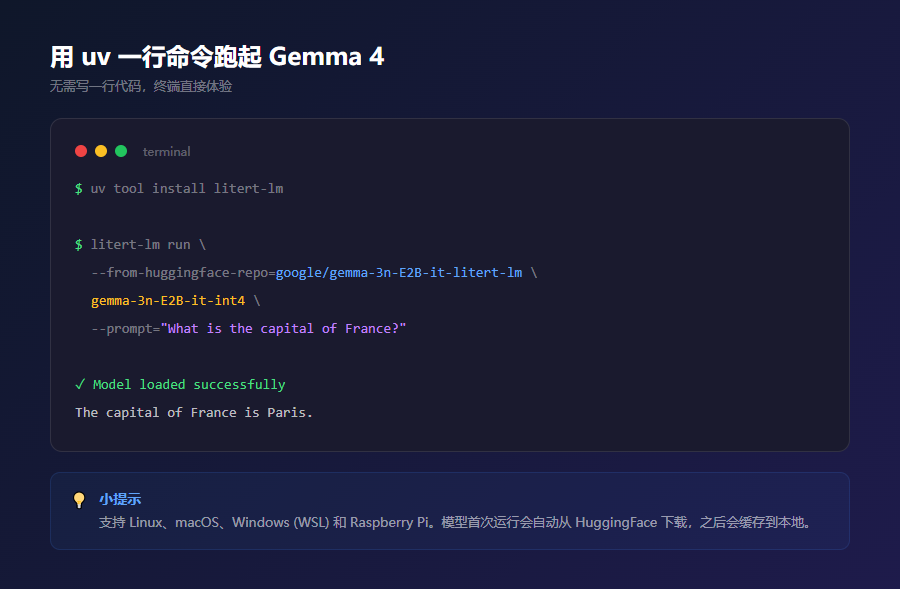
第一次运行会自动从 HuggingFace 下载模型文件,之后就会走本地缓存。支持 Linux、macOS、Windows(WSL)和 Raspberry Pi。
如果是做 Android 开发的,Kotlin API 已经 Stable 了,可以直接集成到项目里:
// Kotlin 集成示例
val session = LlmInferenceSession.create(model)
val response = session.generate("你好,介绍一下你自己")
Python 和 C++ 的 API 也都是 Stable 状态,Swift 还在开发中。
和同类工具比,差在哪
说实话,端侧推理这个赛道已经挺拥挤了。我列几个常见的对比:
| 方案 | 特点 | 适合场景 |
|---|---|---|
| LiteRT-LM | Google 出品,NPU 深度优化,跨平台最全 | 移动端 App、IoT 设备 |
| llama.cpp | 社区最火,纯 CPU 也能跑,生态最好 | 桌面端、服务器 |
| MLC-LLM | TVM 编译优化,JavaScript/WebAssembly | Web 端部署 |
| ONNX Runtime | 微软出品,工业标准 | 企业级应用 |
LiteRT-LM 的独特优势是 Google 自家产品的生产验证。Chrome 浏览器里已经在用它跑 AI 功能了,Pixel Watch 上也有,这不是一个实验室项目。
但话说回来,它的社区活跃度和 llama.cpp 比差距还比较大。目前 135 个 Open Issues,文档也没有 llama.cpp 那么丰富。如果你只是想在电脑上跑跑模型玩玩,llama.cpp 依然是更省心的选择。
LiteRT-LM 更适合那些真的需要把模型塞进手机、手表或者嵌入式设备的开发者。
还有什么值得关注的
如果你对端侧 AI 感兴趣,我之前还写过几篇相关的:
- 用 Rust 写的命令行浏览器自动化工具 Shimmy,4.8MB 就能操控浏览器,比 Playwright 轻太多了
- Ollama 的进阶玩法,在本地跑大模型的一站式方案
这些工具搭配 LiteRT-LM 使用,基本能覆盖从本地推理到端侧部署的完整链路。
总结
LiteRT-LM 的核心价值就一句话:Google 把自家的端侧 AI 能力开源了。
不是什么前沿研究项目,是在 Chrome 和 Pixel Watch 上已经跑起来的生产级框架。如果你在做移动端或者 IoT 相关的开发,需要把大模型集成到设备里,这可能是目前最"官方"的选择。
项目地址:https://github.com/google-ai-edge/LiteRT-LM
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

