
前言
很多人在用selenium定位页面元素的时候会遇到定位不到的问题,明明元素就在那儿,用firebug也可以看到,就是定位不到,这种情况很有可能是frame在搞鬼。
进入到iframe
<html lang="en">
<head>
<title>FrameTest</title>
</head>
<body>
<iframe src="a.html" id="frame1" name="myframe"></iframe>
</body>
</html>
想要定位其中的iframe并切进去,可以通过如下代码:
from selenium import webdriver
driver = webdriver.Chrome()
driver.switch_to.frame(0) # 1.用frame的index来定位,第一个是0
driver.switch_to.frame("frame1") # 2.用id来定位
driver.switch_to.frame("myframe") # 3.用name来定位
driver.switch_to.frame(driver.find_element_by_tag_name("iframe")) # 4.用WebElement对象来定位
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("xxxxx")
driver.maximize_window()
sleep(3)
driver.switch_to.frame("loginIframe")
# 定位到 frame 页面。id=loginIframe
driver.find_element_by_id("username").clear()
driver.find_element_by_id("username").send_keys("123")
driver.find_element_by_id("password").send_keys("123456")
driver.find_element_by_id("btnLogin").click()
driver.quit()
退出iframe
driver.switch_to.default_content()
嵌套iframe
<html>
<iframe id="frame1">
<iframe id="frame2" / >
</iframe>
</html>
从主文档切到frame2,一层层切进去
driver.switch_to.frame("frame1")
driver.switch_to.frame("frame2")
从frame2再切回frame1,这里selenium给我们提供了一个方法能够从子frame切回到父frame,而不用我们切回主文档再切进来。
driver.switch_to.parent_frame() # 如果当前已是主文档,则无效果
有了parent_frame()这个相当于后退的方法,我们可以随意切换不同的frame,随意的跳来跳去了。
所以只要善用以下三个方法,遇到frame分分钟搞定:
driver.switch_to.parent_frame()
driver.switch_to.default_content()
实战
01.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>左侧</title>
<script type="text/javascript">
function dispalay_alert() {
alert('I am alert...')
}
</script>
</head>
<body>
<p>这是左侧frame上的文字</p>
<input type="button" onclick="dispalay_alert()" value="Display alert box">
</body>
</html>
02.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>右侧</title>
</head>
<body>
<p>这是右侧frame上的文字</p>
<input type="radio" id="python" name="book" checked>python selenium
<br />
<input type="radio" id="java" name="book">java selenium
</body>
</html>
03.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>中间</title>
</head>
<body>
<p>这是中间frame上的文字</p>
<input type="input" id="text" >文本框
</body>
</html>
04.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>综合</title>
<frameset cols="25%,50%,25%">
<frame id="leftframe" src="01.html" />
<frame id="middleframe" src="03.html" />
<frame id="rightframe" src="02.html" />
</frameset>
</head>
<body>
<p>这是中间frame上的文字</p>
<input type="button" id="text" >文本框
</body>
</html>
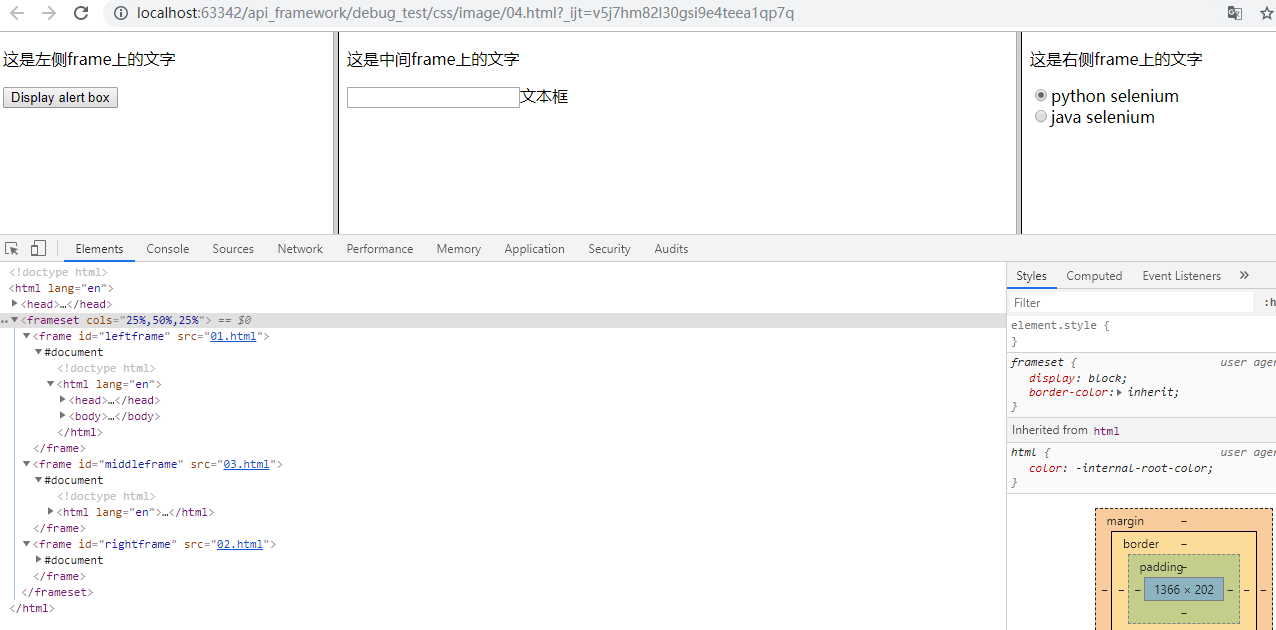
把所有文件放在一个目录下,打开04.html,页面如下
代码如下
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
import time
class Test_frame():
def test_handle_frame(self):
url = r'F:\api_framework\debug_test\css\image\04.html'
self.driver = webdriver.Chrome()
self.driver.get(url)
'''
使用索引方式进入frame页面,索引号从0开始
如果想进入中间的frame,则索引为1
'''
self.driver.switch_to.frame(0)
'''
找到左侧frame中的p标签
'''
leftFrame = self.driver.find_element_by_xpath('//p')
self.driver.find_element_by_tag_name('input').click()
try:
'''
等待alert弹框
'''
alertWindow = WebDriverWait(self.driver, 10, 0.2).until(EC.alert_is_present())
time.sleep(2)
print(alertWindow.text) # 获取弹出框内的内容
alertWindow.accept() # 对弹出框点击确定
except Exception as e:
print(e)
'''
使用driver.switchTo.default_content方法,从左侧中回到frameset页面
如果不执行,则无法进入到其他frame中
'''
self.driver.switch_to_default_content()
'''
通过标签名找到页面中所有frame元素,然后通过索引进入frame
'''
self.driver.switch_to.frame(self.driver.find_elements_by_tag_name('frame')[1])
'''
断言
'''
assert '这是中间frame上的文字' in self.driver.page_source
self.driver.find_element_by_tag_name('input').send_keys('我在中间')
self.driver.switch_to_default_content()
'''
通过id进入右边的iframe
'''
self.driver.switch_to.frame(self.driver.find_element_by_id('rightframe'))
assert '这是右侧frame上的文字' in self.driver.page_source
self.driver.find_element_by_id('java').click()
self.driver.switch_to_default_content()
test1 = Test_frame()
test1.test_handle_frame()
通过循环frame操作frame
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
import time
class Test_frame():
def test_handle_frame(self):
url = r'F:\api_framework\debug_test\css\image\04.html'
self.driver = webdriver.Chrome()
self.driver.get(url)
'''
找到页面上所有的frame对象,并存到列表中
'''
frameList = self.driver.find_elements_by_tag_name('frame')
'''
通过循环遍历列表中的所有frame页面,
'''
for frame in frameList:
self.driver.switch_to.frame(frame)
if "中间" in self.driver.page_source:
p = self.driver.find_elements_by_xpath('p')
print('找到你了。。。')
break
else:
self.driver.switch_to_default_content()
test1 = Test_frame()
test1.test_handle_frame()
在一个frame下无论以此进入多少层内嵌的frame或iframe,调用一次self.driver.switch_to.default_content()函数都会直接从所有的frame中切换出来回到默认页面
python爬虫之selenium--获取HTML源码断言和URL地址
python爬虫之selenium--设置浏览器的位置和高度宽度
python爬虫之selenium--页面元素是否可见和可操作
python爬虫之selenium--高亮显示正在操作的元素
转自:https://www.cnblogs.com/zouzou-busy/p/11070577.html
专业python开发,在线接单,QQ(微信):466867714

