
前言
前面介绍过了七种定位方式,今天来介绍最后一种,也是最强大,本人最常用的定位方式xpath
Xpath 即为 xml 路径语言,它是一种用来确定 xml 文档中某部分位置的语言。Xpath 基于 xml 的树状结构,提供在数据结构树中找寻节点的能力,html 也属于 xml
先来看一个简单的xpath定位
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
sleep(3)
driver.find_element_by_xpath('//*[@id="kw"]').send_keys('selenium')
# //表示当前页面,@id="kw" 表示id为kw了
sleep(2)
driver.find_element_by_xpath('//*[@id="su"]').click()
sleep(2)
driver.quit()
看起来是不是比较麻烦,为什么不通过id直接定位,因为在前端网页开发中,不是每个元素都有id属性的,或者id值是动态变化的。不能直接通过id定位,就要用到xpath定位了
被测网页HTML代码如下:

XPath绝对路径定位
查找第一个div标签下的“查询”按钮
driver.find_element_by_xpath('/html/body/div/inpu[@value="查询"]')
XPath相对路径定位
查找第一个div标签下的“查询”按钮
driver.find_element_by_xpath('//input[@value="查询"]')
//表示从匹配选择的当前节点开始选择文档中的节点,定位到value值为查询的input页面,使用@表明后面接的是属性
使用索引号定位元素
查找第一个div标签下的“查询”按钮
driver.find_element_by_xpath('//input[2]')
定位到第二个input标签,从1开始
使用页面元素的属性值定位元素
定位被测试网页中的第一张img元素
//img[@href='http://www.baidu.com']
//input[@type='button']
使用模糊属性值定位元素
页面上某些元素的属性值是动态生成的,也就是说每次访问的属性值都不一样,使用模糊属性值可以解决一部分此类问题,前提是属性中有一部分内容保持不变
查找属性alt的属性值以“div1”关键字开始的页面元素
//img[starts-with(@alt,'div1')]
查找alt属性的属性值包含“img”关键字的页面元素,只要包含即可,无须考虑位置
//img[contains(@alt,'img')]
实例:

上面页面中id值中后面的数字是动态变化的
fr = driver.find_element_by_xpath("//iframe[contains(@id,'x-URS-iframe')]")
driver.switch_to.frame(fr)
使用XPath轴(Axes)定位元素
先找到一个相对好定位的元素,让他作为轴,根据他和要定位的相对位置关系进行定位
| XPath轴关键字 | 轴的含义说明 | 定位表达式实例 | 表达式解释 |
|---|---|---|---|
| parent | 选择当前节点的上层父节点 | //img[@alt='div2-img2']/parent::div | 查找到属性alt的属性值为div2-img2的img元素并基于该img元素的位置找到他上一级的div元素 |
| child | 选择当前节点的下层所有子节点 | //div[@id='div1']/child::img | 查找到id属性值为div1的div元素,并基于该div元素的位置找到他下层节点中的img元素 |
| ancestor | 选择当前节点所有上层的节点 | //img[@alt='div2-img2']/ancestor::div | 查找到属性alt的属性值为div2-img2的img元素并基于该img元素的位置找到他上一级的div元素 |
| descendant | 选择当前节点所有下层的节点(子,孙等) | //div[@name='div2']descendant::img | 查找到属性name的属性值为div2的div元素并基于该元素的位置找到他下级所有节点中的img页面元素 |
| following | 选择在当前节点之后显示的所有节点 | //div[@id='div1']/following::img | 查找到id属性值为div1的div元素,并基于该div元素的位置找到他后面节点中的img元素 |
| following-sibling | 选择当前节点后续所有兄弟节点 | //a[@href='http://www.sogou.com']/following-sibling::input | 并基于链接的位置找到它后续兄弟节点中的input页面元素 |
| preceding | 选择当前节点前面的所有节点 | //img[@alt='div2-img2']/preceding::div | 查找到属性alt的属性值为div2-img2的图片元素img,并基于该图片元素的位置找到他前面节点中的div页面元素 |
| preceding-sibling | 选择当前节点前面的所有兄弟节点 | //input[@value='查询']/preceding-sibling::a[1] | 查找到value属性值为“查询”的输入框页面元素,并基于该输入框的位置找到它前面同级节点中的第一个链接元素 |
有时候我们会在轴后面加一个星号(),表示通配符,比如//input[@value='查询']/preceding-sibling::,它表示查找属性value的值为“查询”的输入框input元素前面所有的同级元素,但不包括input元素本身
使用页面元素的文本定位元素
通过text()函数可以定位到元素文本包含某些关键字的页面元素
(1) //a[text()='搜狗搜索']
(2) //a[.='搜狗搜索']
(3) //a[contain(.,"百度")]
(4) //a[contain(text(),"百度")]
(5) //a[contain(text(),"百度")]/preceding::div
(6) //a[contain(.,"百度")]/..
pytho定位语句
driver.find_element_by_xpath("//a[text()='搜狗搜索']")
driver.find_element_by_xpath('//a[contain(text(),"百度")]/preceding::div')
表达式1和表达式2等价,都是查找文本内容为“搜狗搜索”的链接页面元素,使用的是精准定位,不能多也不能少
表达式3和表达式4等价,都是查找文本内容里包含“百度”关键字的链接页面,使用的是模糊匹配
表达式5和表达式6等价,都是查找文本内容里包含“百度”关键字的链接页面元素a的上层父元素div,表达式6最后使用了两个点,它表示选取当前节点的父节点,等价于preceding::div
xpath定位实例
实例一
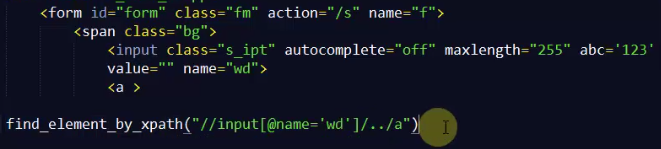
先定位到name='wd'的标签上,..返回父级标签,也就是span标签,在找到span标签的a标签
实例二
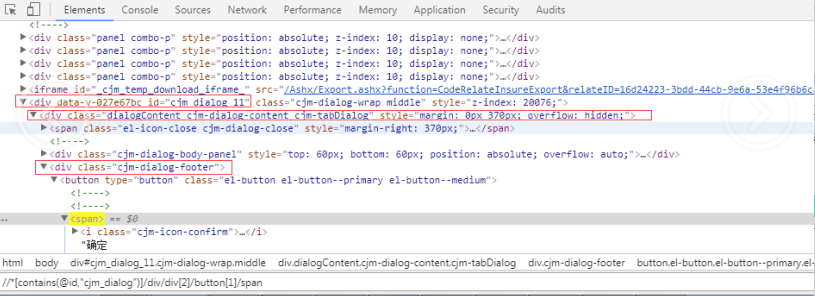
//*[contains(@id,"cjm_dialog")]/div/div[2]/button[1]/span
实例三
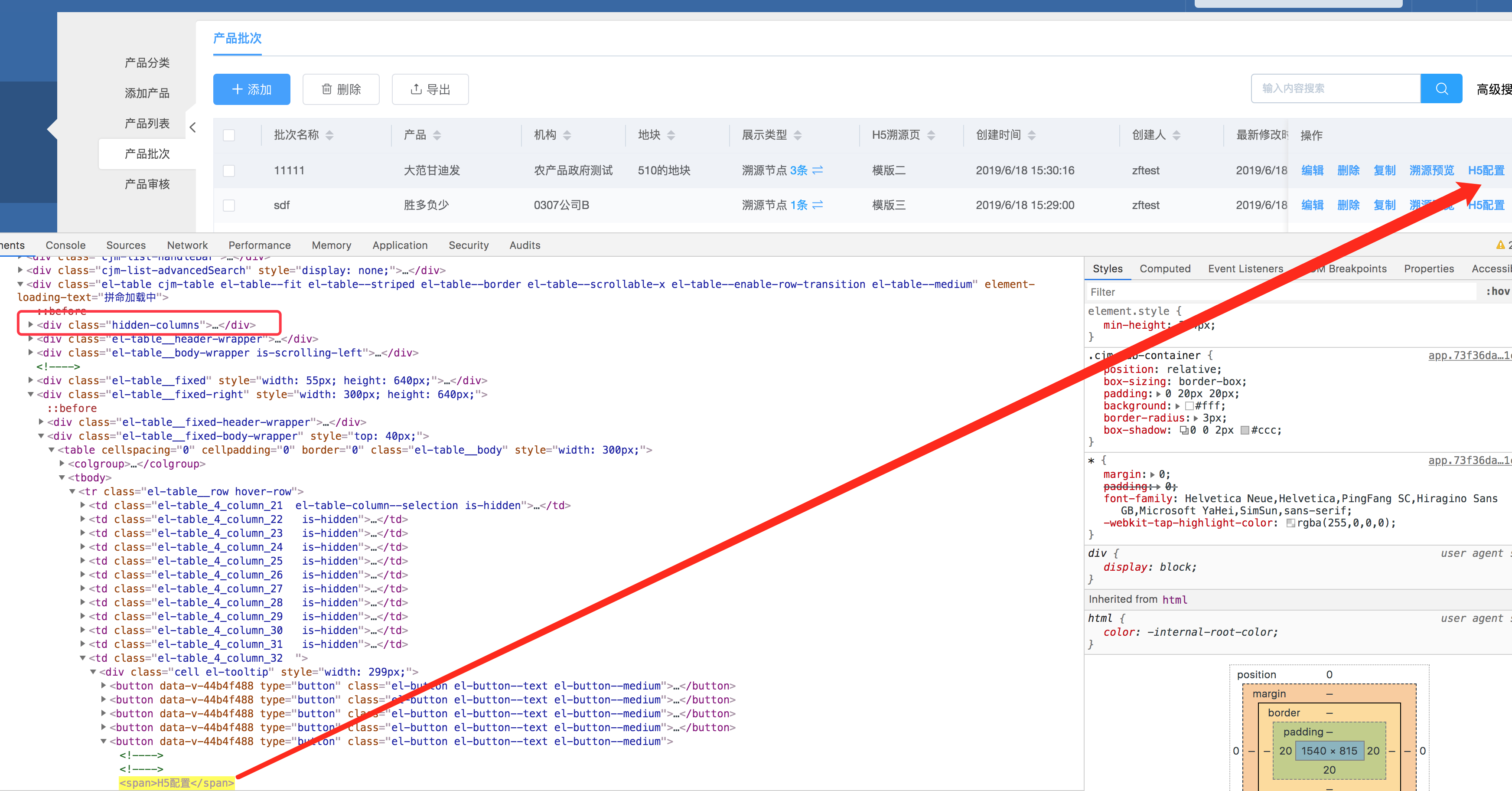
//div[@class="hidden-columns"]/following-sibling::div[4]/div/table/tbody/tr[1]/td[12]/div/button[5]/span
实例四
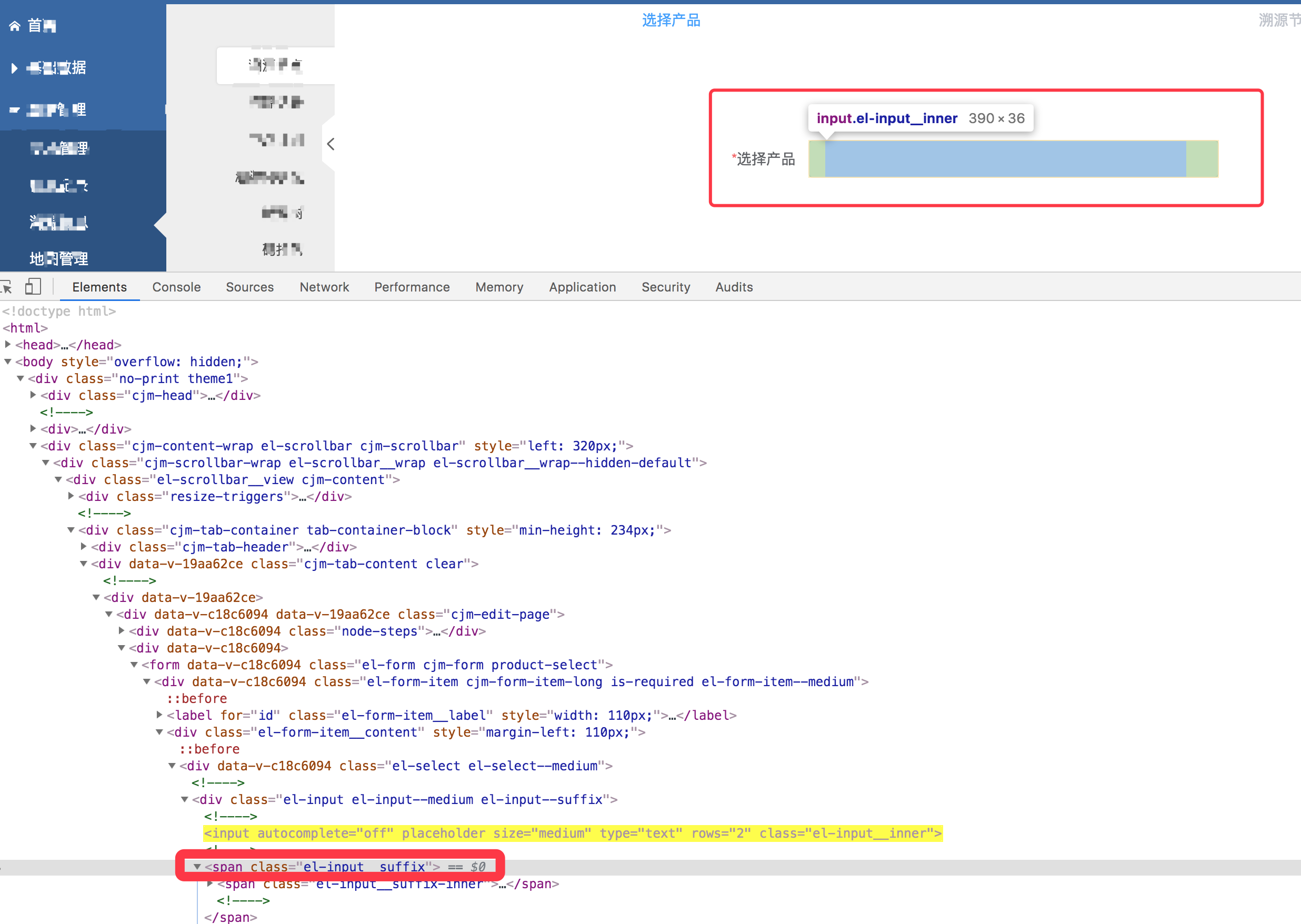
//span[@class='el-input__suffix']/preceding-sibling::input[1]
实例五
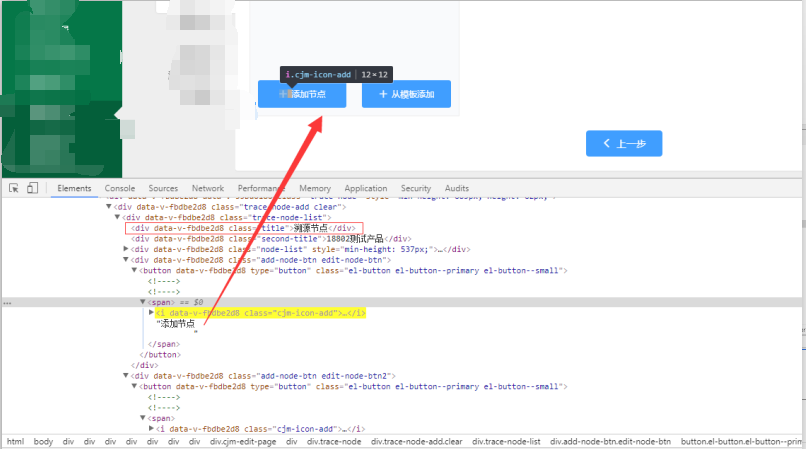
//div[text()="溯源节点"]/../div/button/span/i
实例六
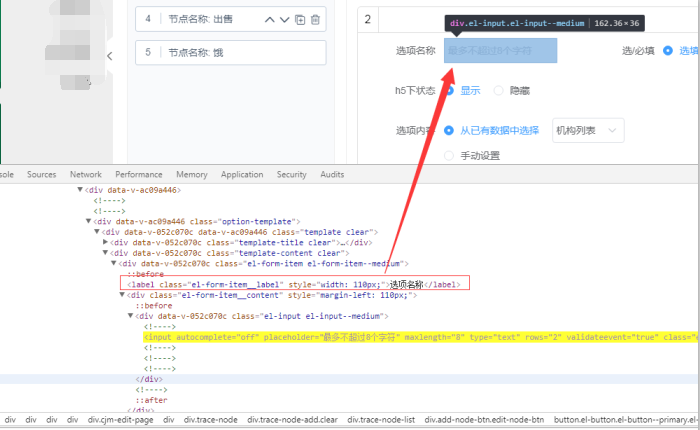
//label[text()="选项名称"]/following::div/div/input
实例七
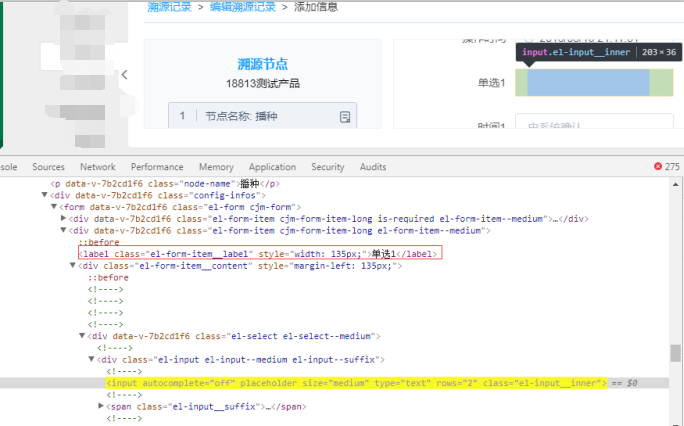
//label[contains(text(),"单选1")]/following-sibling::div/div/div/input
实例八
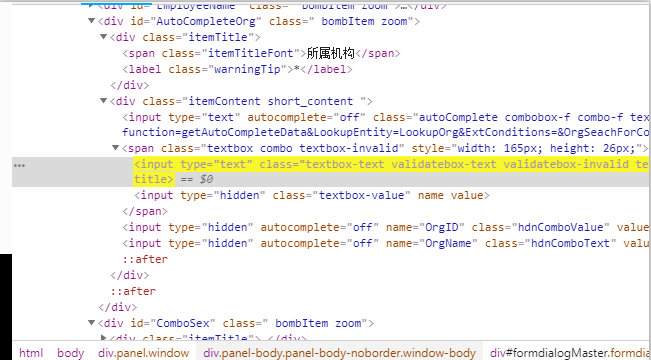
//span[text()="所属机构"]/../following-sibling::div/span/input
python爬虫之selenium--获取HTML源码断言和URL地址
python爬虫之selenium--设置浏览器的位置和高度宽度
python爬虫之selenium--页面元素是否可见和可操作
python爬虫之selenium--高亮显示正在操作的元素
转自:https://www.cnblogs.com/zouzou-busy/p/11062307.html
专业python开发,在线接单,QQ(微信):466867714

