大家好,我是何三,独立开发者
你有没有被 Headless Chrome 的内存占用搞崩溃过?
跑个爬虫脚本,开 100 个 tab,服务器直接 OOM。开 25 个 tab,内存飙升到 2GB。这玩意儿本质上是个完整的桌面浏览器,只是"假装"没有界面而已——图形渲染引擎、GPU 进程、音频系统,全在后台跑着,你一个像素都看不到,但钱一分没少花。
最近发现一个项目叫 Lightpanda,干的事情很激进:用 Zig 从零写了一个无头浏览器。不是 Chromium fork,不是 WebKit patch,是真正的从零开始。它一上来就砍掉了图形渲染引擎——反正无头模式也用不到。

结果呢?内存降到 Chrome 的 1/16,速度快了 9 倍。
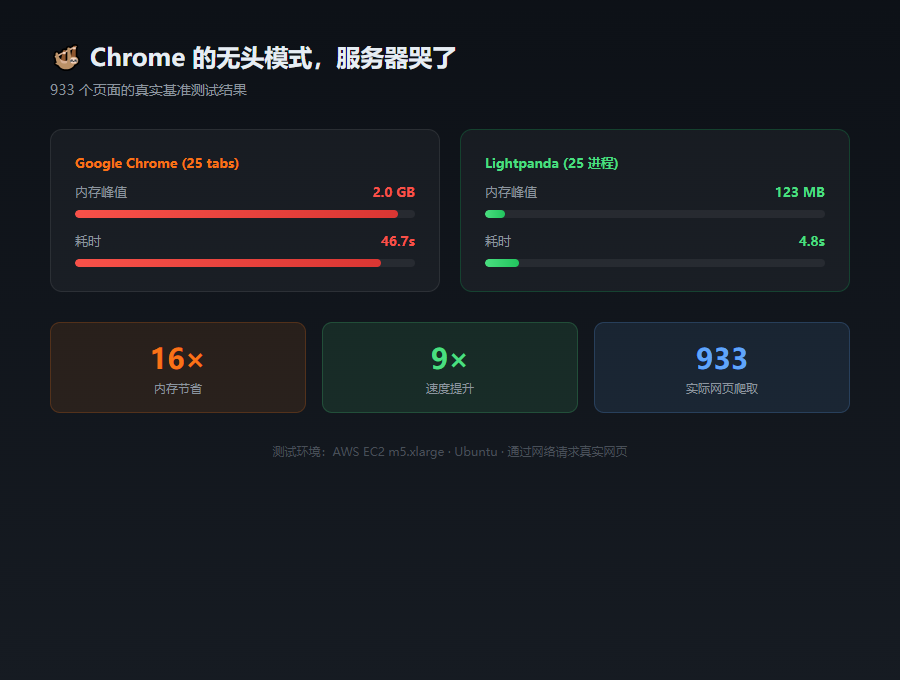
先看数据,别急着吹
数据不会骗人,但放数据的姿势会。Lightpanda 团队拿 933 个真实网页做了爬虫基准测试,在 AWS m5.xlarge 上跑的,不是什么 toy demo。

关键数据:
| 场景 | Lightpanda | Chrome |
|---|---|---|
| 单进程爬 933 页 | 27MB 内存,51s | 1.3GB 内存,82s |
| 25 进程并发 | 123MB,4.8s | 2.0GB,46s |
| 100 进程并发 | 410MB,5.2s | 4.2GB,69 分钟 |
Chrome 100 个 tab 跑了 1 小时 9 分钟,内存吃了 4.2GB。Lightpanda 100 个进程 5 秒就完了。
更离谱的是单次页面加载的基准测试——同一个电商页面加载 100 次,Chrome 平均 185ms 一次,Lightpanda 平均 16ms 一次。差了十倍不止。Chrome 的内存峰值 402MB,Lightpanda 只有 21MB。
这组数据的意思是:如果你之前需要一台 8GB 内存的云服务器跑爬虫,现在可能一台 1GB 的就够了。
为什么不用 Playwright/Puppeteer 就行了?
能用 Puppeteer 的开发者,可能 90% 不会关心底层跑的是什么浏览器。毕竟 puppeteer.launch() 一行代码就搞定了。
问题出在规模上。
当你需要同时处理几百上千个页面的时候,Chrome 的多进程架构就变成了灾难。每个 tab 都是一个独立进程,内存开销是乘法级的。你在云上跑 100 个 Chrome 实例,光内存费用就够买一台新电脑了。
Playwright 这类工具解决的是"怎么控制浏览器"的问题,但没解决"浏览器本身太重"的问题。Lightpanda 想解决的是后者。
架构上到底做了什么?

Lightpanda 的核心思路可以概括成一句话:只保留无头浏览器真正需要的部分。
一个完整的浏览器引擎大概包含这些东西:
- HTTP 网络栈(加载网页)
- HTML/CSS 解析器(解析结构)
- DOM 树(文档对象模型)
- JavaScript 引擎(执行 JS)
- CSS 样式计算(算出每个元素的样式)
- Layout 布局(算出元素位置和大小)
- 渲染/绘图(把像素画到屏幕上)
- GPU 进程、合成器、动画系统……
无头模式下,最后三项(CSS 布局之后的全部)完全是浪费。Lightpanda 直接砍掉了渲染管线,只保留:
- Libcurl 做网络请求
- html5ever(Servo 项目出品)解析 HTML
- V8 执行 JavaScript
- 自研的 DOM 树实现
技术栈选了 Zig。这个选择挺有意思——Zig 是个系统级语言,手动内存管理,没有隐藏的内存分配,没有 GC 暂停。对于浏览器这种对内存敏感的场景,Zig 比 C++ 更容易控制,比 Rust 学习曲线更低。代价是生态还比较年轻。
兼容 CDP,接入零成本
这是 Lightpanda 最聪明的设计决策之一:完全兼容 Chrome DevTools Protocol(CDP)。
也就是说,你现有的 Puppeteer 脚本、Playwright 脚本,基本不用改代码,只要把连接地址指向 Lightpanda 的 CDP 服务器就行了。
import puppeteer from 'puppeteer-core';
// 唯一的区别:指向 Lightpanda 的 CDP 服务器
const browser = await puppeteer.connect({
browserWSEndpoint: "ws://127.0.0.1:9222",
});
// 后面的代码完全一样
const page = await browser.newPage();
await page.goto('https://example.com', {waitUntil: "networkidle0"});
const links = await page.evaluate(() => {
return Array.from(document.querySelectorAll('a')).map(a => a.href);
});
console.log(links);
启动 Lightpanda 也简单:
# 直接命令行抓取一个页面,输出 HTML 或 Markdown
./lightpanda fetch --dump html https://example.com
./lightpanda fetch --dump markdown https://example.com
# 或者启动 CDP 服务器
./lightpanda serve --host 127.0.0.1 --port 9222
还支持 Docker:
docker run -d --name lightpanda -p 127.0.0.1:9222:9222 lightpanda/browser:nightly
迁移成本几乎为零。 这是它相比其他轻量方案最大的卖点。
原生 MCP 支持,AI Agent 时代的第一选择?
Lightpanda 还原生支持了 MCP(Model Context Protocol),这意味着 AI Agent 可以直接通过 MCP 协议控制浏览器,不需要中间层。
配置也很简单:
{
"mcpServers": {
"lightpanda": {
"command": "/path/to/lightpanda",
"args": ["mcp"]
}
}
}
这个功能在当下 AI Agent 爆发的背景下特别有价值。越来越多的 AI Agent 需要浏览网页、填写表单、提取数据——如果底层浏览器轻了十倍,Agent 的部署成本就降了一个数量级。
想想看,一个 AI Agent 同时控制 50 个浏览器实例去采集信息,用 Chrome 可能需要 50GB 内存,用 Lightpanda 只需要 1-2GB。这个差距在规模化的时候是生死级别的。
但是,别急着上生产
得说几个现实的问题。
第一个:还是 Beta。 项目 README 自己都说了——"You may still encounter errors or crashes." 它的 Web API 覆盖还不完整,CORS 都还没实现。一些复杂的 SPA 网站可能跑不了。
第二个:不支持 CSS 布局和渲染。 如果你需要截图、做视觉回归测试、检查元素位置,Lightpanda 做不到。它只能操作 DOM 和执行 JS,看不到"页面长什么样"。
第三个:Zig 生态的问题。 构建需要 Zig 0.15.2、V8、Rust 工具链,编译一次不是特别轻松。虽然提供了预编译二进制和 Docker 镜像,但自己改代码编译的门槛还是有的。
第四个:社区还很小。 目前 GitHub 的 star 数不算多,遇到 bug 主要是自己提 issue 等回复。不像 Puppeteer/Playwright 那样有庞大的社区支持。
所以我的建议是:爬虫场景、数据采集、AI Agent 可以先试起来,但如果是关键业务,再等等。不过项目的方向是对的——无头浏览器确实不需要那么重。
几个适合尝试的场景
- 大规模网页采集:需要并发处理大量页面,内存是主要瓶颈
- AI Agent 浏览器控制:通过 MCP 或 CDP 让 LLM 操控浏览器
- SEO 监控和站点健康检查:定期爬取检查页面可访问性
- 自动化测试中的 API 层测试:不需要视觉验证的场景
- Markdown 生成:直接
lightpanda fetch --dump markdown把网页转 Markdown
总结
Lightpanda 做了一件正确但很难的事——从头造一个浏览器。这在 2025 年听起来有点疯狂,毕竟浏览器引擎已经被 Chrome 和 Firefox 垄断了多少年。
但它的切入点很精准:无头场景不需要渲染,那为什么还要背着渲染引擎的包袱?用 Zig 从零开始,内存可控,性能可预期,还兼容 CDP 协议,迁移成本极低。
16 倍内存节省、9 倍速度提升,这些数字足够让做爬虫和 AI Agent 的开发者认真考虑一下了。
项目地址:https://github.com/lightpanda-io/browser
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

