大家好,我是何三,独立开发者
Karpathy 的 /raw 文件夹问题
Andrej Karpathy 有个习惯——遇到有意思的论文、推文、截图、笔记,随手丢进一个叫 /raw 的文件夹。时间一长,文件堆积如山,想找某个概念和哪篇论文有关联?纯靠记忆,基本不现实。
这个场景其实每个开发者都遇到过:电脑里收藏了几百篇技术文章、几十个代码仓库的笔记、一堆随手保存的截图。要用的时候,翻都翻不到。
最近 GitHub 上有个叫 graphify 的项目试图解决这个问题。它是一个 Claude Code 的 Skill 插件,输入一行 /graphify,就能把任意文件夹——代码、文档、PDF、图片——全部转成一张可查询的知识图谱。
最吸引人的数字:在 Karpathy 的仓库 + 5篇论文 + 4张图片(共52个文件)的测试中,查询时 Token 消耗降低了 71.5倍。

graphify 到底做了什么
简单说,它干了一件事:把非结构化的文件堆,变成结构化的知识图谱,然后让你可以像查数据库一样去查它。
具体来看,扔进去一个文件夹,它会吐出这些东西:
graphify-out/
├── graph.html # 交互式图谱,可点击节点、搜索、按社区筛选
├── obsidian/ # 可直接用 Obsidian 打开的笔记库
├── wiki/ # 类 Wikipedia 风格的文章(--wiki 模式)
├── GRAPH_REPORT.md # 核心报告:关键节点、意外关联、推荐问题
├── graph.json # 持久化图谱,几周后再查不用重新跑
└── cache/ # SHA256 缓存,只处理变更过的文件
这里最实用的是 GRAPH_REPORT.md。它不是简单罗列文件内容,而是告诉你:
- God Nodes(核心节点):哪些概念是连接数最高的?所有东西都通过它串联
- Surprising Connections(意外关联):跨文件发现的关系,你大概率没想到
- Suggested Questions(推荐问题):这个图谱能回答哪些你没想到该问的问题
比如在 Karpathy 的仓库测试中,它发现 from_pretrained() 在 nanoGPT 和 minGPT 之间居然有调用关系——一个 INFERRED(推理)出来的关联,代码里并没有直接写出来。
核心原理:不是简单索引,是真的"理解"
graphify 的处理流水线分五个阶段:
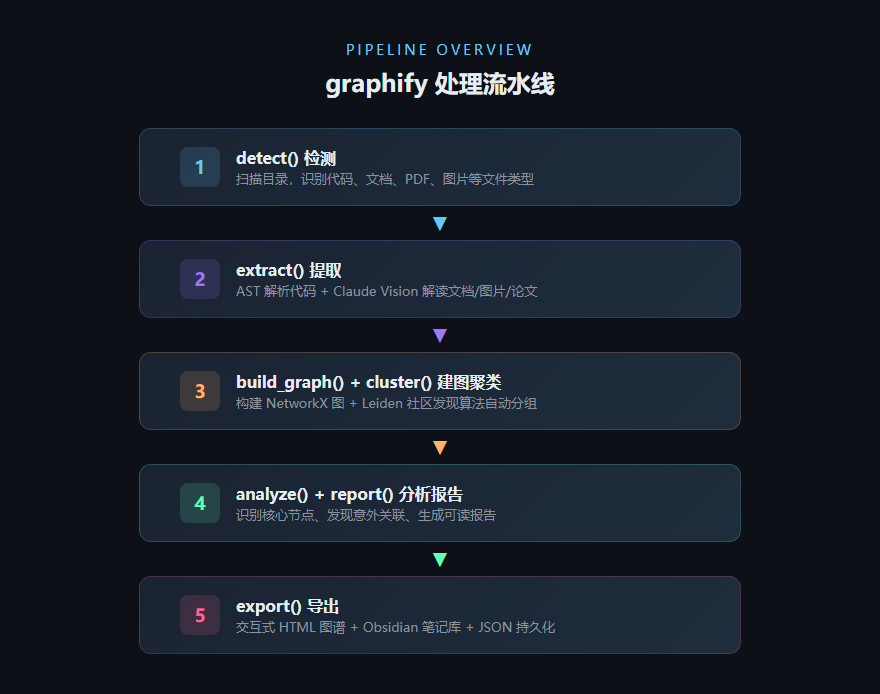
第一阶段:检测,扫描目录,按扩展名把文件分成代码、文档、PDF、图片四大类。
第二阶段:提取,这一步是整个项目最关键的地方。对不同类型文件用不同策略:
- 代码文件:用 tree-sitter 做 AST 解析,提取函数调用、import 关系、类继承等结构化信息,再做一次 call-graph 第二遍扫描得到 INFERRED(推理)关系
- 文档/Markdown:交给 Claude 提取概念和概念之间的关系
- PDF 论文:先挖引用网络,再用 Claude 提取核心概念
- 图片:用 Claude Vision 去"看"——截图识别UI模式,图表提取趋势,手写白板识别想法和箭头,甚至其他语言的图片也能处理
所以它是多模态的,不是只能处理文本。
第三阶段:建图 + 聚类,用 NetworkX 构建图结构,然后用 Leiden 算法做社区发现。社区发现就是把图谱中联系紧密的节点自动分成不同的"圈子",每个圈子代表一个主题领域。
第四阶段:分析 + 报告,计算每个节点的度(连接数),找出核心节点;跨文件、跨社区寻找意外关联;生成推荐问题。
第五阶段:导出,输出交互式 HTML 图谱(用 vis.js 渲染)、Obsidian 笔记库、JSON 持久化文件等。
每条边都带"可信度标签"
这个设计我觉得挺值得说的。
graphify 给每条关系边都打了三种标签:
| 标签 | 含义 |
|---|---|
| EXTRACTED | 源码中明确存在的(比如 import 语句、直接调用) |
| INFERRED | 合理推理出来的(比如共享数据结构、隐含依赖) |
| AMBIGUOUS | 不确定的,标记出来让人工复核 |
很多知识图谱工具的问题是"幻觉"——它告诉你两个东西有关系,其实根本没有,只是AI编的。graphify 至少诚实,它会明确告诉你哪条关系是它"猜"的。Karpathy 那个测试中,81% 的关系是 EXTRACTED,19% 是 INFERRED,0% AMBIGUOUS。
这种"说实话"的设计理念,在到处都是"AI万能"包装的当下,算是一股清流。
Token 暴降 71 倍是什么概念

用 graphify 作者的原话说:71.5x fewer tokens per query vs reading the raw files。
翻译一下,就是每次查询时,你只需要读取图谱中相关的子图,而不是把52个文件全部重新喂给 LLM。428K tokens 变成 6K tokens。按 GPT-4 的价格算,每次查询从 $6.42 掉到 $0.09。
而且这个压缩比和文件数量正相关:6个文件只有约1倍提升(因为本来就不大,直接读也够),但52个文件就能到71倍。你收藏的东西越多,它越值。
graph.json 做了持久化,图谱建好后存在本地。几周后你想再问"Attention 机制和 Optimizer 有什么关系?",直接查图谱就行,不用把所有文件重新跑一遍。
代码实战:从安装到出图
前提条件:需要先装好 Claude Code 和 Python 3.10+。
安装就一行:
pip install graphifyy && graphify install
PyPI 上的包名暂时叫 graphifyy(多一个y),但 CLI 命令和 Skill 触发命令都是 graphify。
安装完后,在 Claude Code 里打开任意目录,输入:
/graphify .
就这一行,它会自动跑完整个流水线。
常用的几个命令:
# 对指定文件夹生成图谱
/graphify ./my-project
# 更新模式:只重新处理变更过的文件,合并进现有图谱
/graphify ./my-project --update
# 深度模式:更激进地推理隐含关系
/graphify ./my-project --mode deep
# 把网页丢进去(论文、推文都行)
/graphify add https://arxiv.org/abs/1706.03762
# 查询:BFS广度遍历,适合获取广泛上下文
/graphify query "what connects attention to the optimizer?"
# 查路径:两个概念之间的最短路径
/graphify path "AuthModule" "Database"
# 解释某个节点
/graphify explain "SwinTransformer"
还有几个高级功能值得一提:
--watch模式:后台运行,文件变了自动更新图谱。代码文件用 AST 秒级重建,文档/图片变更会通知你手动跑--update。适合多 Agent 并行写代码的场景。graphify hook install:装一个 git post-commit hook,每次 commit 后自动重建图谱。不需要后台进程,任何编辑器都能用。--wiki模式:生成类 Wikipedia 风格的 Markdown 文章,每个社区一篇,带index.md入口。可以把任何 Agent 指向index.md,它就能通过读文件来导航整个知识库,不用解析 JSON。--mcp模式:启动一个 MCP stdio server,让其他 Agent 通过标准协议查询图谱。--svg/--graphml/--neo4j:导出为各种格式,可以接 Gephi、yEd、Neo4j 等专业图分析工具。
技术栈和架构
graphify 的技术栈很"实在":
- NetworkX:Python 图处理库
- Leiden (graspologic):社区发现算法
- tree-sitter:多语言 AST 解析
- Claude:语义提取和 Vision 分析
- vis.js:交互式图谱可视化
没有 Neo4j,不需要服务器,全部本地运行。
架构设计也比较干净——每个阶段是单独的模块,模块之间通过纯 Python dict 和 NetworkX Graph 通信,没有共享状态,副作用只出在 graphify-out/ 目录里。想扩展新语言,加个 tree-sitter 解析器就行。
谁适合用 graphify
几个典型场景:
接手新代码库——先跑一下 /graphify,看 GRAPH_REPORT.md,比翻文档快10倍。你不用一行行读代码,先看核心节点是谁、哪些模块之间有意外关联。
收藏了一堆论文和笔记——全丢进一个文件夹,跑一次 /graphify --wiki,生成可导航的知识库。以后想查"这篇论文和那个概念什么关系",直接问图谱。
多 Agent 协作开发——--watch 模式保持图谱实时更新,多个 Agent 写完代码,图谱自动反映最新结构。
个人的 /raw 文件夹——这就是 graphify 最初的灵感来源。随手收藏的东西丢进去,让它慢慢长成一张知识网,想查什么随时查。
一些真实的问题
它也不是万能的。
6个文件的小项目,压缩比只有约1倍——这时候 graphify 的价值不在省 Token,而在结构清晰度。你能看清模块之间的实际关系,这个比压缩数字更重要。
在 Karpathy 仓库的测试中,它识别出了65个孤立节点——只有0-1条连接的概念,可能是真的孤立的,也可能是漏了边。还有不少"薄社区"(只有2个节点),效果存疑。
INFERRED 的关系也不是100%对的。虽然它区分了"确定的"和"猜的",但19%的推理关系里,有多少是真的有价值、有多少是噪音,还得人自己判断。
另外它目前强绑定 Claude Code,如果你的主力 AI 编程工具不是 Claude Code,用起来会有门槛。
写在最后
graphify 解决的不是"AI能不能读文件"的问题——任何 LLM 都能读。它解决的是大规模非结构化信息的结构化管理问题。
收藏夹里那200篇论文、3个代码仓库的笔记、一堆随手存的截图,它们之间的关联是什么?哪些概念是反复出现的"God Node"?有没有跨领域的意外联系?这些问题,光靠人脑记不住,光靠 LLM 每次从头读成本太高。
graphify 走了第三条路:建一次图谱,持久化,反复查。
项目还在早期阶段(v0.3.1),PyPI 包名都还没争回来。但它解决的问题很真实,设计理念也够诚实。如果你是 Claude Code 用户,收藏夹里又堆了不少东西,值得试一试。
GitHub: https://github.com/safishamsi/graphify
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

