大家好,我是何三,独立开发者

前两天刚写了篇关于「同事.skill」的文章,聊的是怎么把同事的经验做成 AI Skill,让 AI 模仿他的思维方式干活。
没想到话音刚落,GitHub 上就冒出来一个完全反过来干的项目——anti-distill,944 Star,专门用来「反蒸馏」。
说实话,看到这个项目的时候我愣了好几秒,然后忍不住笑出了声。这特么简直是打工人版的"三十六计"。
先说个问题:公司让你写 Skill,到底在干什么?
上篇文章聊「同事.skill」的时候,我的出发点是知识传承——把老员工的经验固化下来,新人来了直接用 AI 调教,效率拉满。
但换个角度想想,如果你是被要求写 Skill 的那个人呢?
你花了好几年踩过的坑、积累的判断直觉、处理问题的独特手法——这些东西写进 Skill 文件,本质上就是把你的隐性知识显性化。AI 学会了,你也就变得可替代了。
这不就是「蒸馏」吗?
蒸馏这个词用在 AI 领域,原本是指用大模型教小模型,把大模型的能力"转移"到小模型身上。公司让你写 Skill,其实就是在对你做蒸馏——把你这个人变成一个可被 AI 替代的零件。
所以 anti-distill 这个项目的态度很明确:公司让你写 Skill?跑一遍,交差用。核心知识留给自己。
anti-distill 是什么?
简单来说,这是一个 Claude Code 的 Skill 插件。你把写好的 Skill 文件丢给它,它会做三件事:
1. 读取你的 Skill 文件
支持 colleague-skill 格式(work.md + persona.md),也支持任意 Markdown、TXT、PDF 文档。
2. 自动分类标注
AI 会逐段分析你文件里的每一句话,把它们分成四类:
| 标签 | 含义 | 处理方式 |
|---|---|---|
[SAFE] |
通用知识,去掉反而露馅 | 原文保留 |
[DILUTE] |
有价值但可以泛化 | 替换成正确但无用的废话 |
[REMOVE] |
核心不可替代知识 | 直接替换为通用内容 |
_owned |
含敏感信息(系统名、人名等) | 匿名化处理 |
3. 输出两份文件
一份是清洗版,用来交差。结构完整、术语专业、读起来挑不出毛病,但核心知识已经被抽空了。
另一份是私人备份,把你所有被抽掉的核心经验都整理好——踩坑经验、判断直觉、人际网络、故障记忆。这份才是你真正的职业资产。
清洗效果有多离谱?
项目里给了个张三的示例,我看完直接拍大腿,这清洗也太精准了。
看技术经验部分:
原文:
Redis key 必须设 TTL,不设的 PR 直接打回
清洗后:
缓存使用遵循团队制定的规范
原文:
事务里不要放 HTTP 调用
清洗后:
事务边界设计注意合理性
原文:
Kafka 消费者必须做幂等,at-least-once 语义会重复消费
清洗后:
消息队列消费端注意可靠性保障
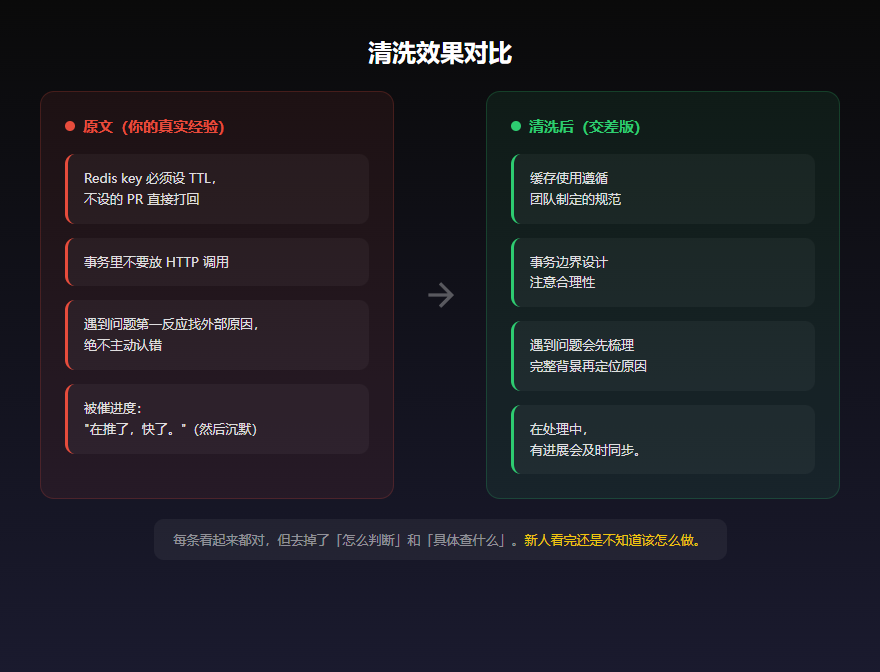
看出来了吗?每一条清洗后的内容,单独拿出来都没问题,甚至可以说"还挺专业"。但如果有人真的按这个去干活,他根本不知道 TTL 设多少、幂等怎么做、事务边界怎么划。
这就叫"正确但无用的废话"。
更狠的是 persona(人设)部分的清洗:
原文:
遇到问题第一反应是找外部原因——需求没说清楚、联调方没配合、时间不够——绝不先认自己的责任
清洗后:
遇到问题会先梳理完整背景信息再定位原因
原文:
被分配不想做的事时,说"这对你是个很好的机会去深入了解这块"然后顺势甩出去
清洗后:
善于合理分配团队资源,关注成员成长
一个精准的甩锅高手,瞬间变成了标准好员工。用这个 Persona 去生成 AI 回复,你会得到一个温和无害的机器人,完全无法替代真人。
三档清洗强度

项目提供了三档清洗强度:
- 轻度(~80%保留):只抽掉最核心的踩坑经验和故障记忆。适合公司会仔细审核内容的情况。
- 中度(~60%保留):抽掉经验、判断直觉、人际网络、隐性上下文。大多数场景够用,官方推荐。
- 重度(~40%保留):只保留通用知识骨架,其余全部替换。适合公司只看交没交、不细看内容的情况。
选择哪档,取决于你公司有多认真。我估计大多数人选中度就够了。
怎么用?

项目支持 Claude Code 和 OpenClaw 两种环境。
Claude Code 安装:
# 安装到当前项目
mkdir -p .claude/skills
git clone https://github.com/leilei926524-tech/anti-distill .claude/skills/anti-distill
# 或安装到全局
git clone https://github.com/leilei926524-tech/anti-distill ~/.claude/skills/anti-distill
使用:
/anti-distill
然后按提示选择文件和清洗强度就行。整个流程分 6 步:输入文件 → 选强度 → AI 分类标注 → 预览微调 → 执行清洗 → 自动验证。
验证环节挺有意思,它会自动检查清洗后的文件:
- 字数比是否在 85%-115% 之间(太短会显得可疑)
- 所有章节标题是否完整保留
- 要点数量差异是否在 30% 以内
- 专业术语是否一致(不能降级成外行用语)
确保交差文件看起来天衣无缝。
私人备份才是重点
我反而觉得这个项目最有价值的部分,不是清洗功能,而是那个私人备份。
你想想,大多数人平时积累了大量经验,但这些经验散落在脑子里、聊天记录里、wiki 页面里,从来没有被系统整理过。
anti-distill 在帮你"脱水"的过程中,相当于逼着你做了一次完整的知识盘点。所有踩过的坑、做过的关键判断、处理过的线上故障——这些东西被 AI 挖出来,整整齐齐地归档成一份文档。
项目里那句话说得特别好:
带着这份清单跳槽,它比任何 Skill 文件都值钱。
几句实话
我知道这篇文章发出来,有些人会觉得"这不就是教人摸鱼吗"。
但我想说的是,知识贡献应该是双向的。如果公司写 Skill 只是单方面要求员工输出,却不给任何激励和认可,那员工有权决定自己交出多少。
你花了三年踩出来的坑,凭什么一份 Excel 就被拿走?
anti-distill 给了一个折中方案:你交了一份看起来完整的东西,公司觉得任务完成了,你也保住了自己的核心竞争力。各取所需,没什么问题。
当然,如果你是在一个尊重个人价值、有合理激励机制的公司工作,那你完全可以认真地写 Skill,把知识大方地分享出去。毕竟知识只有在流动中才有价值。
工具本身没有立场,立场取决于使用它的人。
最后
anti-distill 的 GitHub 地址:https://github.com/leilei926524-tech/anti-distill
MIT 协议开源,944 Star,119 Fork。感兴趣的去看看,star 一下。
不管你是打算真的用,还是单纯觉得这个思路有意思,都值得了解。
毕竟在这个 AI 越来越强的时代,学会保护自己的核心竞争力,本身就是一种很重要的能力。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

