大家好,我是何三,独立开发者
最近看到一个挺有意思的开源项目——OpenSwarm,一个实验性的 AI Agent 操作系统。
它解决了一个我一直觉得麻烦的问题:多智能体协作的时候,怎么把一堆 Agent 串起来。
用过 CrewAI、AutoGen 的朋友大概都有体会——写 Agent 之间的调用关系,越写越乱。A 调 B,B 调 C,再加个 D,配置文件一堆,改一个地方牵一发动全身。
OpenSwarm 的思路完全不一样。
Agent 之间互不相识
这是 OpenSwarm 最核心的想法:每个 Agent 根本不知道其他 Agent 的存在。
没有互相调用,没有共享状态,也没有消息路由表。每个 Agent 只能看到一个叫 Neural Bus(神经总线)的东西。
这个 Bus 是一个 384 维的向量空间。用户说一句话,这句话被编码成一个 384 维的向量写入 Bus。所有 Agent 各自有一个"任务向量",Bus 计算两者之间的余弦相似度——匹配上了,Agent 就被"唤醒"。
简单说,不是"我派活给你",而是"你听到自己关心的东西,自己醒来干活"。
这玩意有点像蜂群。蜜蜂之间不互相喊话,靠的是信息素。每只蜜蜂闻到自己关心的味道就行动。OpenSwarm 的名字就是这么来的。
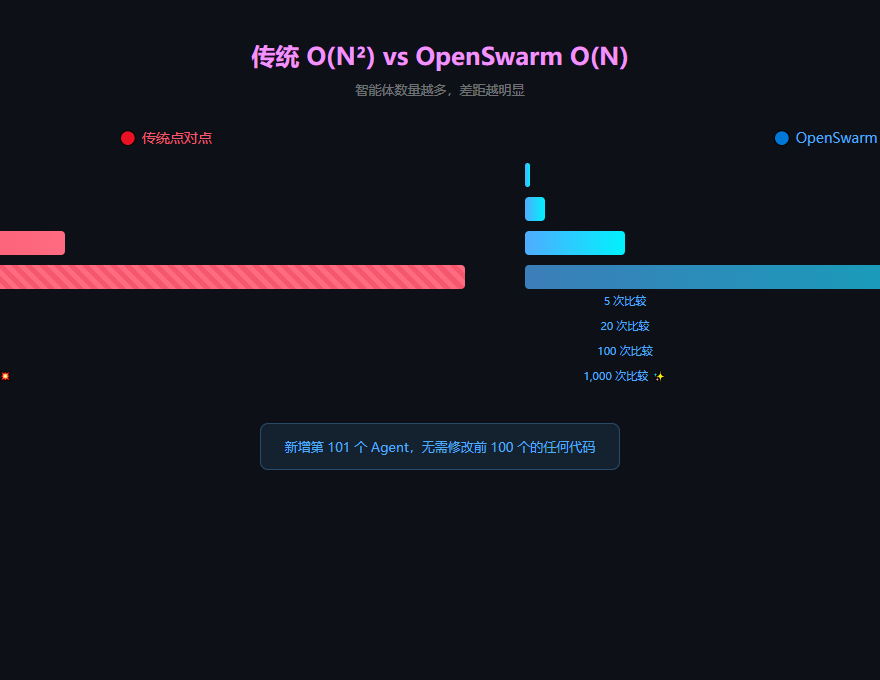
O(N²) 的噩梦
传统的多 Agent 框架,Agent 之间是点对点连接的。每两个可能交互的 Agent 都要拉一条线。
5 个 Agent,要配 20 条路由。20 个 Agent,380 条。100 个 Agent,将近 1 万条。到了 1000 个——接近 100 万条。
而且每加一个新 Agent,你得回去改别的 Agent 的配置,引入新的依赖,维护成本指数级上升。删一个 Agent 还可能把依赖它的全搞崩。
OpenSwarm 把这个问题彻底绕过去了。
每个 Agent 只需要声明自己关心什么(一个任务向量),Bus 做一次余弦相似度计算就行了。N 个 Agent,每次信号广播只做 N 次比较。
加第 101 个 Agent,前 100 个完全不用改一行代码。
共振唤醒:怎么匹配的
整个过程大概是这样的:
- 用户输入"放点爵士乐"
- 这句话被 Sentence-BERT 编码成 384 维向量,写入 Bus
- Bus 把这个向量跟每个 Agent 的任务向量做余弦相似度计算
- Chat Agent 的相似度是 0.12,远低于阈值——不醒
- Music Agent 的相似度是 0.89——被唤醒,开始播放
- Dice Agent 的相似度是 0.04——不醒
只有语义上真正相关的 Agent 才会被激活。默认阈值 0.6,还能自适应调整。
如果你想让特定 Agent 干活,直接 @browser click on News,那个 Agent 就会 100% 唤醒,跳过相似度计算。
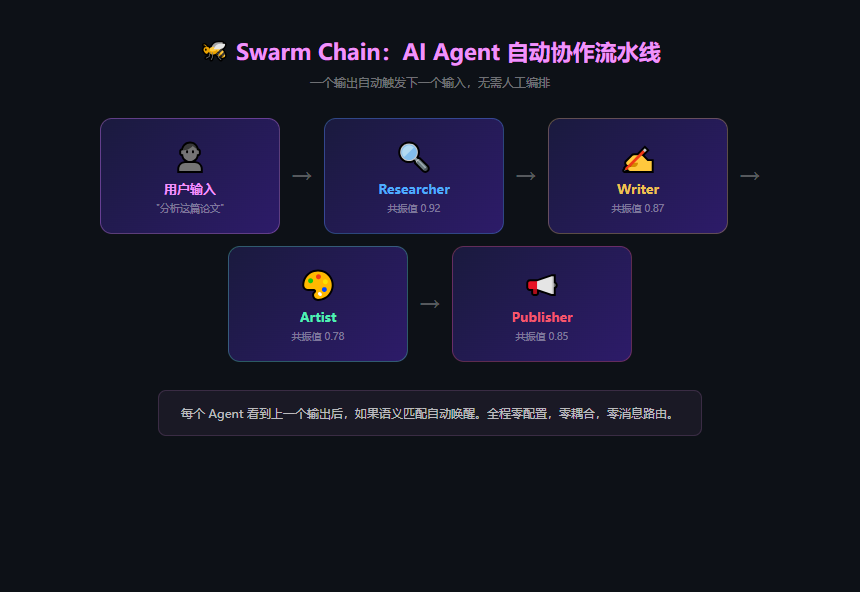
Swarm Chain:自动串联的流水线
最酷的是 Swarm Chain。
一个 Agent 的输出会自然写入 Bus,而其他 Agent 的任务向量如果跟这个输出语义匹配,就会自动唤醒。这样一来,一条流水线就这么形成了,不需要任何编排代码。
举个例子:
- 用户说"分析这篇论文" → Researcher 被唤醒,抓取并总结论文
- Researcher 输出"研究摘要:关键发现..." → Writer 觉得跟自己的任务匹配,自动醒来写稿
- Writer 输出"推文草稿:1/5 你知道吗..." → Artist 被唤醒,生成配图
- Artist + Writer 的产物一起 → Publisher 自动发布到社交平台
全程零配置。没有 Workflow YAML,没有 DAG 图,没有状态机。Agent 之间靠语义对齐就能形成复杂的协作链。
性能和部署
这个项目说实话还比较新(v0.1.0),但性能数据挺漂亮的:
- Bus 本身只加了不到 3ms 的开销,98% 的延迟在 LLM 推理上
- 信号写入 14 万次/秒
- 共振匹配 240 万次/秒
- 单机就能跑,Redis Streams 可以水平扩展
部署方式也很灵活:
# 最简单的方式
pip install openswarm-os
openswarm start # TUI 终端模式
openswarm daemon # 浏览器 Dashboard
# Docker 部署
cd openswarm-server
docker compose up --build
# 可选功能,按需安装
pip install openswarm-os[audio] # 音乐播放
pip install openswarm-os[browser] # 浏览器 Agent
pip install openswarm-os[gpu] # GPU 加速向量计算
首次启动会自动检测 Ollama,没装的话会自动启动并拉模型。不需要额外配置 API Key,完全本地运行。
跟其他框架比怎么样
项目 README 里放了一张对比表,我挑几个重点的说:
| 特性 | OpenSwarm | CrewAI | AutoGen | LangGraph |
|---|---|---|---|---|
| 完全本地(无需 API Key) | ✅ | ❌ | ⚠️ | ⚠️ |
| Agent 零耦合 | ✅ | ❌ | ❌ | ❌ |
| 向量空间通信 | ✅ | ❌ | ❌ | ❌ |
| 内置 TUI 终端 | ✅ | ❌ | ❌ | ❌ |
| 加密 Agent 密钥 | ✅ | ⚠️ | ⚠️ | ⚠️ |
| 自动发现 Agent | ✅ | ❌ | ❌ | ❌ |
当然要公平说一句——OpenSwarm 还在 Alpha 阶段,CrewAI、AutoGen 这些已经经过大量生产环境验证。OpenSwarm 的"向量空间协作"到底能不能 scale 到复杂真实场景,作者自己也说不确定。
但这个思路确实很有启发性。
现在有什么能力
项目目前已经提供了不少东西:
- 10 个核心 Agent:Chat、Browser、Music、Dice、Safe、Settings 等
- 21 个官方扩展 Agent:邮件、YouTube、翻译、Slack 等
- 5 条预置 Swarm Chain:内容创作、代码审查等流水线
- Web Dashboard:拖拽面板,实时 SSE 推送
- TUI 终端界面:命令行党友好
- 安全层:Token 认证、加密密钥、速率限制、RBAC、审计日志、文件沙箱
- 多浏览器页面:Agent 可以同时操作多个浏览器页面
安全这块做得比较细——每个 Agent 有独立的 Token 和 Fernet 加密的密钥库,MCP 工具调用有 4 层审计网关(权限 → 沙箱 → AST 审计 → 注册表),还有基于角色的访问控制。
一些值得注意的限制
别被亮点冲昏头,这个项目有几个明显的坑:
- 短消息可能误触发:一句话同时唤醒好几个 Agent。虽然作者加了最低词数过滤、排除标签等缓解措施,但这个问题在 Alpha 阶段还是比较常见
- Bus 状态是内存的:重启就丢。持久化需要接 Redis
- API 不稳定:Bus 协议、Agent 配置、MCP 网关接口都还在变
- 默认依赖 Ollama:想用 OpenAI 的话要手动配置
作者自己也很诚实地说:这是从个人 Home Lab 项目重构出来的,架构改了很多,bug 肯定还有。
怎么看这个项目
说实话,OpenSwarm 的"零耦合 + 语义共振"这个设计思路,我觉得是方向性的创新。
现在多 Agent 框架最大的痛点就是编排复杂度。Agent 多了之后,谁调谁、怎么传数据、怎么处理异常,光这些就能把人搞崩溃。OpenSwarm 用向量空间把这个编排问题从"显式"变成了"隐式",大幅降低了系统复杂度。
不过,这种"涌现式"协作也有代价——你很难精确控制流程。如果某个 Agent 误判了语义,该醒的不醒、不该醒的醒了,排查起来可能比显式编排更痛苦。
这大概就是所有"去中心化"系统的通病:简单场景很优雅,复杂场景很难调试。
但作为一个实验性项目,它至少给我们展示了另一种可能性。
项目地址:https://github.com/openswarm-os/openswarm
MIT 协议,Python 3.10+,感兴趣的同学可以去看看,提提 Issue 和 PR。作者说他会因为反馈和贡献而感激。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

