大家好,我是何三,独立开发者
你有没有遇到过这种情况:跟 ChatGPT 聊了一上午的项目细节,关掉窗口,下午重新打开,它什么都不记得了。
这不是bug,这就是AI的默认状态——无记忆。
每次对话都是一张白纸。你跟它说"我用 TypeScript"、"我喜欢函数式编程"、"我住在上海",下一轮对话,它又问你"请问你用的是什么语言"。
真的很烦。
最近在 GitHub 上刷到一个项目,20.9k Star,专门解决这个问题。叫 Supermemory,来自 supermemoryai 团队。
它做的事情说起来很简单:给 AI 一层持久化的记忆。但仔细看下去,你会发现它的野心远不止于此。
Memory ≠ RAG,这是两个东西
聊 Supermemory 之前,先得搞清楚一个容易混淆的概念。
很多人觉得"给 AI 加记忆"就是搞个向量数据库,存一些文档切片,需要的时候 RAG 检索出来。没错,这是知识检索,但这不是记忆。
RAG 是无状态的。同样一个问题,不管谁问,返回的结果都一样。它检索的是文档片段,不关心你是谁。
Memory 是有状态的。它追踪的是关于用户的事实,而且这些事实会随时间变化。比如"我住在 NYC"和三个月后的"我刚搬到 SF",记忆系统得知道后者覆盖了前者。
Supermemory 把这两件事做了明确的区分,然后在底层统一处理。
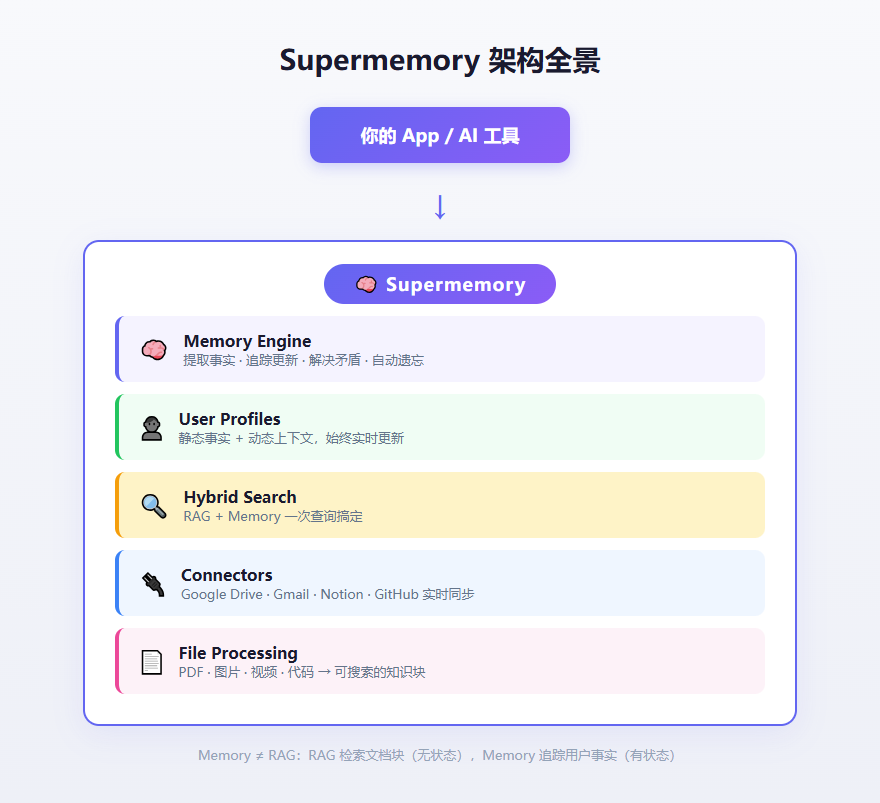
它到底能干什么
直接看核心能力:
🧠 记忆引擎 — 从对话中自动提取事实,处理时间线上的变化、矛盾信息,还能自动遗忘过期的内容。比如你说"明天有个考试",过了明天,这条记忆就该失效。
👤 用户画像 — 每个用户自动维护一份 profile,包含长期稳定的事实(职位、偏好)和近期的动态上下文(当前在做什么项目)。一次调用,大约 50ms 就能拿到。
🔍 混合搜索 — RAG + Memory 放在一次查询里。查"怎么部署"的时候,既能返回文档里的部署指南,也能返回你之前的部署偏好。
🔌 连接器 — Google Drive、Gmail、Notion、OneDrive、GitHub,全部支持实时同步。文档变了,知识库自动更新。
📄 多模态处理 — PDF、图片(OCR)、视频(转录)、代码(AST 感知的分块),扔进去就能搜。
所有这些跑在同一个记忆结构和本体论上。
Benchmark 全榜第一
AI 记忆这个方向,学术界有三个主要 benchmark:
| Benchmark | 衡量什么 | Supermemory 成绩 |
|---|---|---|
| LongMemEval | 跨会话长期记忆 + 知识更新 | 81.6% — #1 |
| LoCoMo | 扩展对话中的事实召回(单跳/多跳/时序/对抗) | #1 |
| ConvoMem | 个性化偏好学习 | #1 |
三个榜单,全部第一。

而且他们还开源了一个叫 MemoryBench 的评测框架,方便大家拿 Supermemory 和 Mem0、Zep 这些竞品做对比。这份自信,有点东西。
怎么用:两条路线
Supermemory 提供了两种使用方式,取决于你是 AI 用户还是开发者。
路线一:给日常用的 AI 加记忆
如果你只是想让 Claude、Cursor 这些工具记住你,不需要写代码。
直接装他们的 MCP Server:
npx -y install-mcp@latest https://mcp.supermemory.ai/mcp --client claude --oauth=yes
把 claude 换成你的客户端就行——cursor、windsurf、vscode 都支持。
装完之后,你的 AI 就多了三个能力:
memory— 保存或遗忘信息。AI 会在对话中自动调用,把值得记住的东西存下来recall— 按查询搜索记忆,返回相关记忆 + 用户画像摘要context— 在对话开始时注入你的完整画像(偏好、近期活动)
也可以手动配置,在你的 MCP 客户端配置里加上:
{
"mcpServers": {
"supermemory": {
"url": "https://mcp.supermemory.ai/mcp"
}
}
}
路线二:给自家的 AI 产品加记忆
如果你在开发 AI Agent 或者应用,Supermemory 提供了一套完整的 API。
安装:
npm install supermemory
# 或者
pip install supermemory
核心用法就几行代码:
import Supermemory from "supermemory";
const client = new Supermemory();
// 存一条记忆
await client.add({
content: "用户喜欢 TypeScript,偏好函数式编程",
containerTag: "user_123",
});
// 获取用户画像 + 相关记忆,一次调用
const { profile, searchResults } = await client.profile({
containerTag: "user_123",
q: "用户偏好什么编程风格?",
});
// profile.static → ["喜欢 TypeScript", "偏好函数式编程"]
// profile.dynamic → ["正在做 API 集成"]
Python 版本也差不多:
from supermemory import Supermemory
client = Supermemory()
client.add(
content="用户喜欢 TypeScript,偏好函数式编程",
container_tag="user_123"
)
result = client.profile(container_tag="user_123", q="编程风格")
print(result.profile.static) # 长期事实
print(result.profile.dynamic) # 近期上下文
不需要配向量数据库,不需要搭 embedding 流水线,不需要纠结分块策略。它全帮你处理了。
搜索模式
搜索支持三种模式:
// 混合搜索(默认)— RAG + Memory 一起查
const results = await client.search.memories({
q: "怎么部署?",
containerTag: "user_123",
searchMode: "hybrid",
});
// 返回部署文档(RAG)+ 用户部署偏好(Memory)
// 只搜记忆
const results = await client.search.memories({
q: "用户偏好",
containerTag: "user_123",
searchMode: "memories",
});
框架集成
主流 AI 框架都有现成的封装:
// Vercel AI SDK
import { withSupermemory } from "@supermemory/tools/ai-sdk";
const model = withSupermemory(openai("gpt-4o"), "user_123");
// Mastra
import { withSupermemory } from "@supermemory/tools/mastra";
const agent = new Agent(withSupermemory(config, "user-123", { mode: "full" }));
支持 Vercel AI SDK、LangChain、LangGraph、OpenAI Agents SDK、Mastra、Agno、n8n 等等。
自动遗忘:这才是真正的记忆
我觉得 Supermemory 最有意思的一个设计是自动遗忘。
很多记忆系统只管存不管忘。但真实的人类记忆不是这样的。"我明天有个面试"这种信息,过了明天就没意义了。"我住在 NYC"在你说出"我刚搬到 SF"的那一刻就应该被覆盖。
Supermemory 在引擎层处理了这些问题:
- 临时事实按时间自动过期
- 矛盾信息自动解决(新的覆盖旧的)
- 噪音不会变成永久记忆
这个能力在现有的开源方案里,做得相当完善。
项目信息
- GitHub:https://github.com/supermemoryai/supermemory
- Star:20.9k
- 协议:MIT
- 语言:TypeScript(61.8%)+ MDX(31.1%)+ Python(6.4%)
- 技术栈:Postgres、Cloudflare Workers、Remix、Drizzle ORM
开源,MIT 协议,可以自由使用和二次开发。
说说我的看法
AI 记忆这个赛道今年越来越热了。Mem0 之前也火过一阵,但 Supermemory 的差异化很明显——它不只是在做"向量存储 + 检索",而是真正在构建一个有状态的记忆引擎。
能处理矛盾、能自动遗忘、能维护用户画像,这些才是"记忆"区别于"检索"的关键。
不过也有几点需要注意:
- 核心的记忆引擎虽然开源,但托管服务是走他们自己的平台的,API 调用依赖他们的后端
- 如果你需要完全本地化、私有化部署,可能需要自己跑一套完整的后端服务
- 作为研究型团队的产品,API 稳定性和企业级支持还需要时间验证
但不管怎么说,20.9k Star,三大 Benchmark 全部第一,MIT 开源。对于正在做 AI Agent 的开发者来说,这个项目值得认真看一下。
有时候我就在想,AI 的能力已经这么强了,差的就是这一层"记忆"。等 AI 真的能记住你的一切——你的偏好、你的项目、你说过的话——那交互体验会完全不同。
或许那一天,很快就会来。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

