大家好,我是何三,独立开发者
你有没有想过,一个几十块钱的 ESP32 芯片,就能跑起完整的 AI 语音对话?
能听、能说、能理解指令、甚至能控制家电。不是那种云端依赖、动辄几千块的商业方案,而是开源的、你自己就能搞定的。
最近我发现了一个叫 ESP-AI 的开源项目,GitHub 上 783 星,MIT 协议,用 C 语言写的硬件端 + Node.js 做服务端,整套方案打通了语音唤醒、语音识别、大模型对话、语音合成这一整条链路。
说实话,这种把大模型"塞进"嵌入式硬件的玩法,做得这么完整的项目不多。

为什么 AIoT 这块还没爆发?
大模型火了这么久,但落地到硬件上的案例还是偏少。原因也简单:
- 门槛太高:从音频采集到 ASR 再到 LLM 再到 TTS,每一环都要自己对接
- 成本不友好:商业方案动辄几百上千,个人开发者玩不起
- 生态碎片化:各种开发板、各种语音服务,没有统一的标准
ESP-AI 想解决的就是这个事。它把自己定位成一个"赋能服务平台"——ESP 是 Enablement Service Platform 的缩写。
翻译成人话就是:你负责硬件,AI 的事它来搞定。
核心原理:整条链路都给你串好了
ESP-AI 的架构设计思路很清晰。它采用 C/S 架构,硬件端跑在 ESP32 上,服务端用 Node.js 部署,两者通过 WebSocket 通信。
整条语音对话链路是这样的:
麦克风采集 → 语音唤醒(离线) → ASR 语音识别 → LLM 大模型推理 → TTS 语音合成 → 喇叭输出

每个环节都用了流式传输——不是等一整段话处理完再返回,而是边说边听、边想边说。自研的数据帧协议把延迟压到了很低。还做了预请求、预处理、结果缓存这些优化,实际体验上能做到接近实时的对话。
更关键的是,它把每个环节都做成了插件化设计。
不喜欢官方的 ASR 服务?自己写一个插件换上去就行。想用 GPT、Claude 还是国内的通义千问、文心一言?换个大模型插件就行。TTS 也是同理,甚至连离线语音唤醒都提供了多种方案——内置唤醒、语音唤醒、按钮唤醒、触摸唤醒、串口唤醒。
你甚至可以不直接用 ESP32,而是把它当作一个"AI 语音模块",通过串口跟你真正的主控板通信。这就意味着,不管你用的是 STM32 还是树莓派,都能接入这套 AI 能力。
3 步上手:从零搭建你的 AI 语音设备
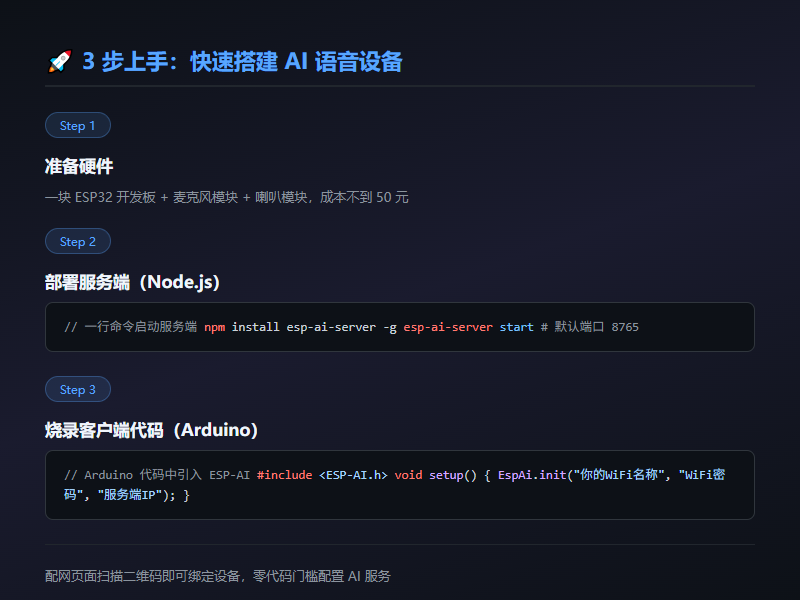
硬件准备
你只需要三样东西:
- ESP32 开发板 — 几十块,某宝随便买
- 麦克风模块 — INMP441 或类似 I2S 麦克风,十几块
- 喇叭/功放模块 — MAX98357A + 小喇叭,二十块以内
总硬件成本不超过 100 块。如果你嫌麻烦,ESP-AI 官方也有开源 PCB 和成品开发板可以买。
服务端部署
服务端基于 Node.js,安装非常简单:
# 全局安装
npm install esp-ai-server -g
# 启动服务
esp-ai-server start
服务默认跑在 8765 端口,负责对接各大 AI 服务(ASR、LLM、TTS),然后把结果推送给硬件端。如果你有自己的 LLM API Key,直接在配置里填上就行。
ESP-AI 还提供了开放平台(espai.fun),免费提供基础服务,你甚至不需要自己部署服务端。在配网页面扫码绑定设备,填个秘钥就完事了。
客户端代码
硬件端用 Arduino 框架开发,代码量非常少:
#include <ESP-AI.h>
void setup() {
// 初始化 WiFi 连接和服务端地址
EspAi.init("你的WiFi名称", "WiFi密码", "服务端IP");
}
void loop() {
EspAi.loop();
}
把这段代码烧录进 ESP32,通电之后会自动弹出配网热点,手机连上去扫码配置就搞定了。
对,零代码门槛。如果你只是想给一个玩具接上 AI 对话功能,用开放平台连设备都不用写代码。
不只是对话:它能做的事比你想的多
语音对话只是基础。ESP-AI 还做了一堆有意思的功能:
指令识别 — 你可以自定义指令规则,比如"打开客厅灯"、"播放儿歌"。支持同时执行多个指令,还能根据上下文动态判断意图。
免费音色克隆 — 只需要 15 秒左右的录音样本,就能克隆出你想要的语音风格。想给孩子的玩具配上卡通声音?没问题。
音乐播放 — 开放平台有音乐库,上传你喜欢的音乐或故事,设备就能播放。甚至可以让 AI 根据你的心情即兴创作一首歌。
闹钟和倒计时 — 不是普通的闹钟。你可以设定"每隔 30 分钟讲一个故事",哄娃神器。
在线更换唤醒词 — 在小程序或网页上直接改,不用重新烧录固件。支持设置多个唤醒词。
一键固件制作 — 想给玩偶定制一双灵动的眼睛?或者把你的 IP 形象放到设备屏幕上?开放平台提供了可视化的一键固件制作工具。
它甚至还做了个 ESP-AI-Studio——在线嵌入式开发环境。对教育行业或者不想折腾本地开发环境的程序员来说,直接在浏览器里写代码、编译、烧录,一条龙。
插件生态和社区
ESP-AI 的一大优势是生态开放。除了核心框架开源,它还建了:
- 插件市场 — 社区贡献的 LLM、TTS、ASR 插件
- 固件社区 — 别人做好的固件,直接下载刷入
- 音色社区 — 分享和下载克隆好的语音风格
- 开源 PCB — 硬件设计文件完全开源,可以自己打板
行业方案方面,官方已经给出了儿童玩具和智能家居两个方向。儿童玩具市场我觉得特别有想象空间——一个几十块钱成本、能跟你家孩子对话的 AI 玩偶,这个产品力已经够了。
一些个人看法
从技术角度看,ESP-AI 做得比较扎实的地方在于:
- 全链路流式设计,没有哪个环节是等全部处理完再返回的,这对语音交互体验至关重要
- 插件化解耦,框架和服务完全分开,你不会被绑定在某个特定的 AI 服务上
- 开放平台免费服务降低了体验门槛,不用自己搭服务端就能玩起来
当然也有一些现实问题。ESP32 的算力毕竟有限,复杂的边缘计算还是得靠服务端。语音唤醒虽然是离线的,但 ASR 和 LLM 都依赖网络,断网就歇菜了。对于商业产品来说,延迟和稳定性还需要做不少优化。
但作为一个开源项目,能做到这个程度已经很可以了。代码质量、文档完善度、社区活跃度都在线。而且已经删除了商用授权协议,开放商用——这很重要,意味着你可以用它来做产品赚钱。
试试看?
如果你对 AIoT 感兴趣,或者手头刚好有一块 ESP32 吃灰,强烈建议试试 ESP-AI。
项目地址:https://github.com/wangzongming/esp-ai
官方文档:https://espai.fun
几十块钱的硬件成本,开源免费的软件方案,大模型对话能力直接落地到实体设备上。这种从"云端 AI"走向"身边 AI"的趋势,我觉得才刚刚开始。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

