大家好,我是何三,独立开发者
今天聊一个让我很兴奋的开源项目——MiniMind。

一个 GitHub 上标星狂飙的项目,它做的事情很简单粗暴:让你用 3 块钱、2 小时,从零开始训练一个 64M 参数的 GPT 语言模型。
你没看错,不是微调,不是 API 调用,是从零训练。
为什么这个项目值得关注?
大模型已经火了一年多了。ChatGPT、DeepSeek、Qwen 一个接一个炸场,但说实话,大多数人对大模型的理解止步于"调 API"和"LoRA 微调"。
用项目作者的话说——
用 LoRA 微调大模型,就像在教牛顿怎么用智能手机。有趣,但偏离了理解物理本质的初衷。
而 transformers、trl、peft 这些工具库,把大模型的底层实现封装得太深了。十几行代码就能跑完"加载模型→加载训练→推理→强化学习"的全流程。方便是真方便,但你根本不知道里面发生了什么。
更头疼的是,网上一堆付费课程和营销内容,用一知半解的讲解来包装所谓的"AI 教程"。
MiniMind 的初衷就是打破这个局面。它把大模型从 0 到 1 的全流程——分词器构建、预训练、微调、强化学习、知识蒸馏、工具调用——每一行代码都用原生 PyTorch 实现,完全开放给你看。
MiniMind 是什么?
一句话概括:一个超小语言模型的全阶段开源复现项目。
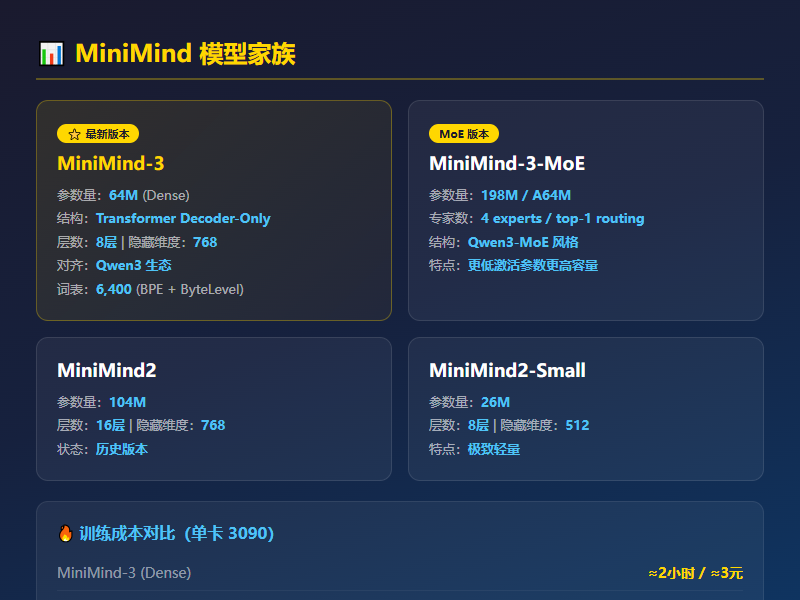
核心数据:
- 参数量:主线版本 64M(Dense),MoE 版本 198M / 激活 64M
- 体积:约为 GPT-3 的 1/2700
- 训练成本:单卡 3090,预训练 + SFT 约 2 小时 / 3 元
- 开源协议:Apache 2.0,完全免费
最新发布的 MiniMind-3 已经全面对齐 Qwen3 / Qwen3-MoE 生态,结构用的是 Transformer Decoder-Only,配置上采用 Pre-Norm + RMSNorm + SwiGLU + RoPE + GQA(q_heads=8, kv_heads=4),这些和主流大模型的技术方案基本一致。
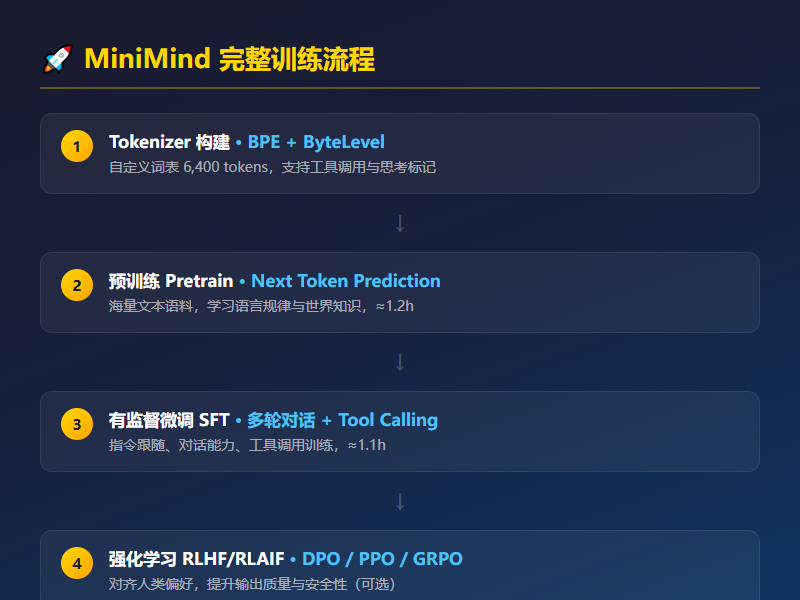
它覆盖了哪些训练阶段?
这是让我最佩服的一点。MiniMind 不只是训练一个"能聊天"的小模型,它把大模型的完整训练链路都实现了:
基础训练 - 预训练(Pretrain):海量文本语料,学习语言规律和基础知识 - 有监督微调(SFT):多轮对话 + 指令跟随 + Tool Calling - LoRA 微调:纯手写实现,不依赖 peft 库,适合快速适配垂域场景
进阶能力 - RLHF / RLAIF:DPO(偏好优化)、PPO / GRPO / CISPO(强化学习),全部从 0 原生实现 - 知识蒸馏:黑盒蒸馏(学习教师输出)+ 白盒蒸馏(学习教师 token 分布) - Tool Use:支持工具调用,约 10w 条合成训练数据 - 自适应思考:同一个模型可以切换"直接回答"和"显式思考链"两种模式 - Agentic RL:多轮 Tool-Use 场景下的强化学习训练
部署兼容
- 兼容 transformers、llama.cpp、vllm、ollama、Llama-Factory
- 提供 OpenAI API 协议的极简服务端,可直接接入 FastGPT、Open-WebUI
- 自带 Streamlit WebUI,支持思考展示、工具选择和多轮对话

技术细节:几个有意思的设计
词表只有 6400
主流大模型的词表动辄 6 万到 15 万。MiniMind 只用了 6,400 个 token。
这不是偷懒,而是有意为之。对 64M 这个量级的模型来说,embedding 层和输出层会吃掉大量参数。词表越大,这两个层越重,留给"真正理解语言"的 Transformer 层的参数就越少。
实测下来,6,400 的词表并没有造成明显的生僻词解码失败,算是一种"够用就行"的工程取舍。
MoE 只用 4 个专家
MoE(混合专家模型)的核心思路是:每次推理只激活一部分参数,用更少的计算量获得更大的模型容量。
MiniMind-3-MoE 用了 4 个专家 + top-1 路由,总参数 198M 但实际激活参数只有 64M,和 Dense 版本一样。
有意思的是,作者提到一个反直觉的发现:MoE 在原生 PyTorch 下训练反而比同规模的 Dense 模型慢大约 50%。原因是 token 要先按专家分桶、再分别 forward,kernel 调度开销很大。所以 MoE "推理更快"这个说法,得靠 Triton 自定义 kernel、DeepSpeed-MoE 这类优化库才能真正实现。
dim=768, layers=8 的取舍
MobileLLM 的研究表明,在百 M 级别的小模型上,深度比宽度更重要——"深而窄"优于"宽而浅"。但 d_model 也不能太小,低于 512 时嵌入维度过窄的劣势会放大。
MiniMind-3 选了 dim=768、layers=8,走的是"矮胖子"路线,主要考虑训练速度和稳定性。如果你更在意效果,可以尝试更深的网络配置。
快速上手:2 小时从零到一
如果你有一张 3090(或同等算力的 GPU),下面这套流程就能跑通:
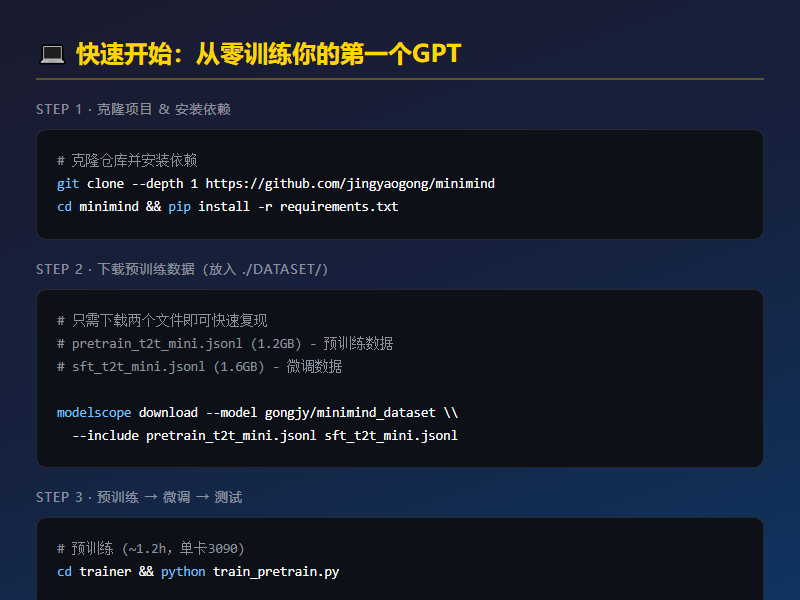
第一步,克隆项目安装依赖
git clone --depth 1 https://github.com/jingyaogong/minimind
cd minimind && pip install -r requirements.txt
第二步,下载数据
到 ModelScope 或 HuggingFace 下载 pretrain_t2t_mini.jsonl(1.2GB)和 sft_t2t_mini.jsonl(1.6GB),放到 ./dataset/ 目录。
这是"快速复现"用的精简数据集。如果你想训练完整版 MiniMind-3,对应的是 pretrain_t2t.jsonl(10GB)和 sft_t2t.jsonl(14GB)。
第三步,预训练
cd trainer && python train_pretrain.py
单卡 3090 大约跑 1.2 小时。完成后在 ./out/ 目录会生成 pretrain_768.pth 权重文件。
第四步,有监督微调
python train_full_sft.py
再跑大约 1.1 小时。完成后生成 full_sft_768.pth。
第五步,测试你的模型
python eval_llm.py --weight full_sft
到这里,你就拥有了一个从零训练出来的对话模型。虽然 64M 的参数量不大,知识面和泛化能力有限,但它确实能聊天、能回答问题、能调用工具。
如果你想进一步玩,还有不少可选的进阶路线: - 用 LoRA 做垂域适配(医疗、法律、自我认知等) - 跑 DPO 做偏好优化 - 跑 PPO/GRPO 做强化学习 - 通过 YaRN 实现长文本外推
所有训练都支持断点续训、多卡 DDP 加速、SwanLab 可视化。
适合什么人?
- 想入门大模型但被动辄几百亿参数吓退的开发者:MiniMind 是最温柔的起点
- 想深入理解 Transformer 底层实现的人:纯 PyTorch 手写,没有黑盒
- 想做垂域小模型快速验证的人:LoRA 微调 + 2 小时出结果,验证成本极低
- 想给学生讲大模型原理的老师/讲师:完整的训练链路,每一阶段都有清晰的代码
这个项目最打动我的地方,是它传递了一种理念——
理解大模型,不一定要有 8 张 H100。3 块钱、一张 3090、一个下午的时间,就够了。
项目地址:https://github.com/jingyaogong/minimind
在线体验:https://www.modelscope.cn/studios/gongjy/MiniMind
感兴趣的朋友可以去试试,从零训练一个属于自己的 GPT,感觉真的不一样。
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

