大家好,我是何三,独立开发者
语音AI领域,微软又扔了个重磅炸弹。
VibeVoice,GitHub 32.4k Star,3.6k Fork。MIT 协议开源。一套模型家族,同时覆盖 TTS(文本转语音)和 ASR(语音识别),而且其中 TTS 论文直接被 ICLR 2026 接收为 Oral。
这是什么概念?语音合成领域顶会 Oral,微软直接把代码开源了。

我花了一些时间研究这个项目,今天把它的核心架构、三个模型的能力边界、以及实际能怎么用,聊清楚。
三兄弟:一个家族,三种能力
VibeVoice 不是一个单体模型,而是由三个模型组成的家族:
- VibeVoice-ASR-7B:语音转文字
- VibeVoice-TTS-1.5B:文本转语音
- VibeVoice-Realtime-0.5B:实时流式语音合成
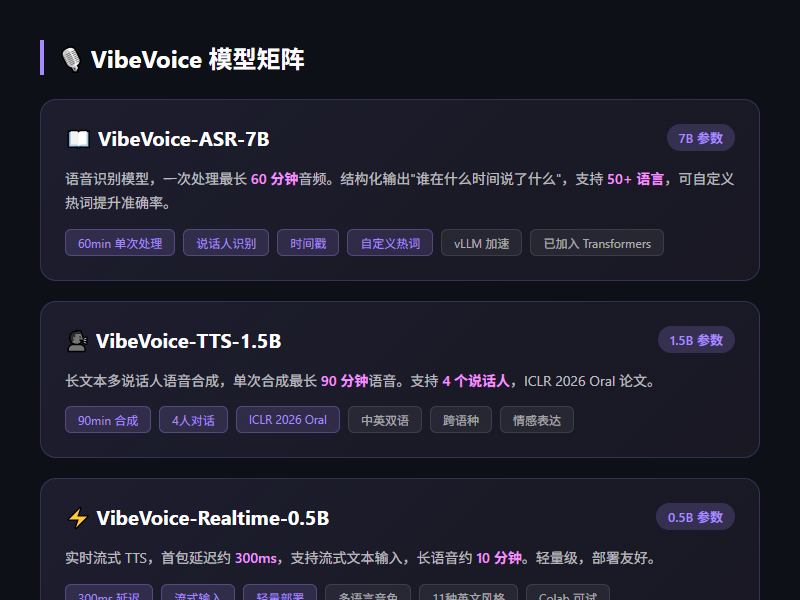
三个模型各有分工,覆盖了语音 AI 的核心场景。先逐个拆开看。
ASR:一口气吃下60分钟音频
传统 ASR 有个老问题——长音频处理得切片。
你丢进去一段一小时的开会录音,它先切成 30 秒一段,每段分别识别,最后拼起来。问题就出在拼接上:跨段说话人跟踪丢了、全局语义断了、时间戳对不上了。
VibeVoice-ASR 的思路很直接:不切。
它用 64K Token 的上下文窗口,一次接收完整 60 分钟音频,单次 pass 直接输出结构化转录结果。输出包含三个维度:
- Who:谁在说话(说话人识别/日志化)
- When:什么时间说的(时间戳)
- When:说的什么内容(文字转录)
更实用的是支持自定义热词。你可以告诉模型特定的专有名词、人名、术语,识别准确率在专业领域会有明显提升。50 多种语言原生支持,中文没问题。
另外,这个模型已经被 Hugging Face Transformers v5.3.0 正式集成了。也就是说你可以像用任何 HF 模型一样,几行代码直接调用。
TTS:90分钟,4个人,一次合成
这个是重头戏。
VibeVoice-TTS 能一次性合成最长 90 分钟的语音,单说话人或最多 4 个说话人的对话都行。而且全程保持说话人一致性和语义连贯性。
90 分钟是什么概念?基本上一整期播客、一场完整的讲座、一部有声书的几个章节——一次性搞定,不需要分段再拼。
多说话人支持也是个亮点。4 个人的对话场景,每人声音特征独立,轮流发言自然连贯。对播客制作者、有声内容创作者来说,这个能力直接就能落地用。
支持的特性也不少:中英双语、跨语种合成、情感表达,甚至能做即兴演唱。
不过有个事得说一下——TTS 代码之前短暂开源后又关闭了。微软发现被用于不符合项目声明的场景,出于 AI 负责任使用的原则做了处理。目前只有 ASR 和 Realtime 模型完全可用。
Realtime:300ms 首包延迟的流式 TTS
0.5B 参数,轻量级,部署友好。
这个模型主打实时场景:流式文本输入,一边生成文本一边合成语音。首包可听延迟大约 300ms,长语音能跑大约 10 分钟。
支持九种语言的多语言音色,还有 11 种不同风格的英文声音。对于需要集成实时语音能力的应用——比如语音助手、实时翻译、对话系统——这个模型的尺寸和延迟表现都比较合适。
Google Colab 上有现成的 Demo,可以直接跑。
底层技术:为什么能做到这么长?
VibeVoice 的核心技术贡献,总结下来就两点。

第一,7.5Hz 超低帧率的连续语音 Tokenizer。
传统的语音离散化方案,帧率通常很高(比如 50Hz),意味着每秒要生成 50 个 token。处理长音频时,token 序列长度爆炸,计算量扛不住。
VibeVoice 用了声学和语义两套连续 Tokenizer,帧率压到 7.5Hz——每秒只生成 7.5 个 token。音质没明显损失,但计算量降了一个数量级。这才让 60 分钟(90 分钟)长序列的处理变得可行。
第二,Next-Token Diffusion 框架。
架构上分成两部分:一个 LLM 主干理解文本上下文和对话流程,一个扩散头负责生成高保真的声学细节。
LLM 部分用的是 Qwen2.5 1.5B,相当于给它一个"懂语言的大脑"来理解文本。然后扩散头把语义理解转化为精确的声学特征。两个模块协同,既保证了语义准确性,又保证了语音自然度。
简单说就是:LLM 负责"懂",扩散头负责"好听"。
能怎么用?
实际落地的场景,我想到几个:
会议记录自动化。丢进去一小时的会议录音,出来就是结构化的转录——谁在什么时候说了什么。自带时间戳和说话人标注,比手动做纪要快太多。
播客/有声书制作。用 TTS 模型合成多说话人的长篇音频,单次跑完 90 分钟。虽然 TTS 代码目前关闭了,但 Realtime 模型可以流式跑,适合短到中等长度的场景。
语音助手后端。Realtime 模型 300ms 首包延迟 + 流式输入,配合 ASR 模型做语音识别,基本就是一个完整的语音交互后端。
代码集成门槛很低。ASR 已经进了 Hugging Face Transformers,标准的 pipeline 调用就行。vLLM 推理加速也支持,进一步降低部署成本。
几个需要注意的点
项目明确标注了仅供研究和开发用途,不建议直接在商业或生产环境中使用。
高保真合成语音有被滥用的风险——深度伪造、诈骗、虚假信息传播这些老问题。微软在 README 里专门强调了这一点。
TTS 部分代码目前不可用,这是个硬伤。整个家族里最能打的功能暂时用不了,只能通过 Hugging Face 页面的 Demo 体验效果。社区在呼吁微软重新开放,但短期内估计不会。
ASR 模型 7B 参数量不算小,本地跑需要一定的 GPU 资源。不过有 vLLM 加速和 finetuning 代码,对有基础设施的团队来说问题不大。
说点什么
语音 AI 这两年发展很快,但大多数开源项目要么只做 TTS,要么只做 ASR,能同时覆盖两端、还做到长序列处理的项目不多。VibeVoice 把两头都做到了 60-90 分钟级别,技术上确实有突破。
32.4k Star 说明社区认可度很高。ICLR 2026 Oral 论文的含金量也在。
唯一遗憾是 TTS 代码关了。如果微软后续能找到合适的开源策略重新开放,这个项目的价值会再上一个台阶。
对语音 AI 方向感兴趣的开发者,建议先从 ASR 模型和 Realtime 模型入手,跑一跑 Hugging Face 和 Colab 的 Demo,感受一下效果。
项目地址:https://github.com/microsoft/VibeVoice 项目主页:https://microsoft.github.io/VibeVoice ASR Playground:https://aka.ms/vibevoice-asr Realtime Colab:https://colab.research.google.com/github/microsoft/VibeVoice/blob/main/demo/vibevoice_realtime_colab.ipynb
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

