大家好,我是何三,独立开发者
你有没有想过一个问题:AI Agent 能读文件、能执行终端命令、能调一堆 API,但它没法像你一样"逛"网页。
你随手打开知乎刷个热榜,一分钟搞定的事,对 Agent 来说几乎不可能——因为知乎没有 API,你的登录态它拿不到,Cookie 提取又面临反爬。Twitter、微博、小红书、B站、BOSS 直聘……全一样。
99% 的网站压根不提供机器接口。AI Agent 的世界被锁死在"文件系统 + 终端 + 几个有 API key 的服务"里。
最近 GitHub 上有个叫 bb-browser 的项目(3.3k Star),干了一件很"坏"的事——
把你的浏览器直接变成 API。
核心思路:不是模拟,是"就是"
传统思路是让 AI 去模拟浏览器操作。Playwright、Selenium、各种爬虫库,本质上都在干同一件事:伪装成一个浏览器。
bb-browser 不这么干。
它的做法是:直接在你的 Chrome 里跑代码。通过 Chrome 扩展 + CDP(Chrome DevTools Protocol),Agent 可以在你已打开的标签页里执行 eval、调 fetch、甚至注入 webpack 模块。
网站看到的 Cookie、Session、Token 全都是你自己的。它没办法区分这是你点的还是 Agent 操作的。因为这确实就是你的浏览器。

这跟"无头浏览器模拟登录"有本质区别。无头浏览器再怎么伪装,指纹、行为模式、WebSocket 握手这些地方总会露出马脚。而 bb-browser 根本不存在这个问题——它不是在"模拟"你,它就是你在操作。
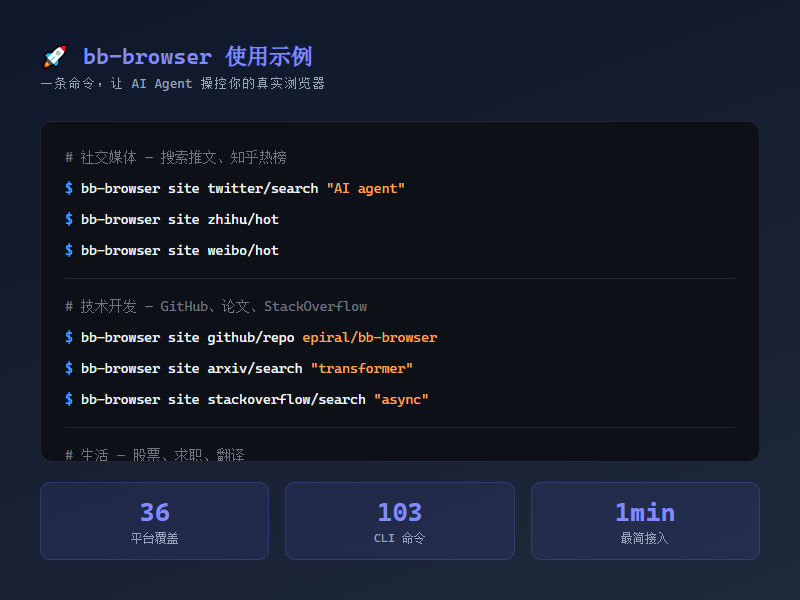
36 个平台,103 条命令
bb-browser 把这个思路做成了一个社区驱动的适配器体系。每个网站的适配就是一个 JS 文件,放在 bb-sites 仓库里。
目前覆盖了 36 个平台、103 条命令:
| 类别 | 平台 |
|---|---|
| 搜索引擎 | Google、百度、Bing、DuckDuckGo、搜狗微信 |
| 社交媒体 | Twitter/X、Reddit、微博、小红书、即刻、LinkedIn、虎扑 |
| 新闻资讯 | BBC、Reuters、36氪、今日头条、东方财富 |
| 技术开发 | GitHub、StackOverflow、HackerNews、CSDN、npm、PyPI、arXiv |
| 视频平台 | YouTube、B站(9个适配器) |
| 影音娱乐 | 豆瓣、IMDb、起点中文网 |
| 财经股票 | 雪球、东方财富、Yahoo Finance |
| 求职招聘 | BOSS直聘、LinkedIn |
| 知识百科 | Wikipedia、知乎、Open Library |
一些实用场景:
# 跨平台调研一个话题
bb-browser site arxiv/search "retrieval augmented generation"
bb-browser site twitter/search "RAG"
bb-browser site github search rag-framework
bb-browser site stackoverflow/search "RAG implementation"
bb-browser site zhihu/search "RAG"
# 日常使用
bb-browser site weibo/hot # 微博热搜
bb-browser site eastmoney/stock "茅台" # 实时股价
bb-browser site boss/search "AI工程师" # 搜职位
bb-browser site douban/top250 # 豆瓣电影 Top250
bb-browser site bilibili/trending # B站热门
还能配合 --jq 做数据过滤:
bb-browser site xueqiu/hot-stock 5 --jq '.items[] | {name, changePercent}'
# {"name":"云天化","changePercent":"2.08%"}
# {"name":"东芯股份","changePercent":"-7.60%"}
架构:四层,很清晰
整个系统分四层,结构简单到有点粗暴:
AI Agent (Claude Code / Codex / Cursor)
│ CLI 或 MCP (stdio)
▼
bb-browser CLI ──HTTP──▶ Daemon ──SSE──▶ Chrome 扩展
│
▼ chrome.debugger (CDP)
你的真实浏览器
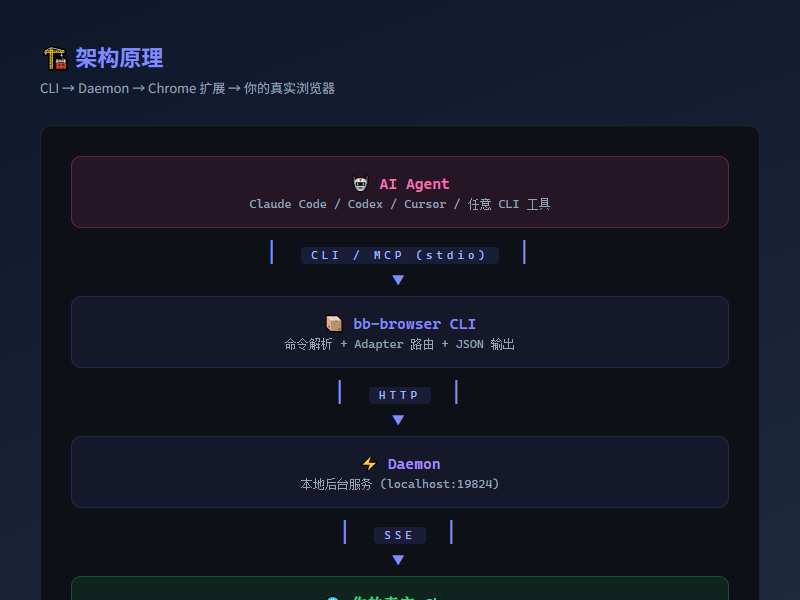
AI Agent 通过 CLI 或 MCP 协议下发命令;bb-browser CLI 解析命令,找到对应的适配器;Daemon 是本地后台服务,默认监听 localhost:19824;Chrome 扩展 通过 CDP 协议在你的浏览器里执行实际操作。
整个过程不需要任何 API Key。你只需要登录过那个网站,剩下的全交给 bb-browser。
三种接入方式
方式一:OpenClaw(最省事)
如果你用 OpenClaw,直接通过它内置浏览器运行,不用装扩展、不用启 daemon:
bb-browser site reddit/hot --openclaw
方式二:Chrome 扩展(独立模式)
从 Releases 下载 zip,解压后在 Chrome 扩展页面"加载已解压的扩展程序"即可。
方式三:MCP 接入 Claude Code / Cursor
在 MCP 配置里加一段就完事:
{
"mcpServers": {
"bb-browser": {
"command": "npx",
"args": ["-y", "bb-browser", "--mcp"]
}
}
}
配完之后,Claude Code 里就能直接调用浏览器了。
适配器分三档,最快 1 分钟
写一个新网站的适配器,难度分三档:
| 层级 | 认证方式 | 代表网站 | 耗时 |
|---|---|---|---|
| Tier 1 | Cookie 直接 fetch | Reddit、GitHub、V2EX | ~1 分钟 |
| Tier 2 | Bearer + CSRF token | Twitter、知乎 | ~3 分钟 |
| Tier 3 | Webpack 注入 / Pinia store | Twitter 搜索、小红书 | ~10 分钟 |
有意思的是,bb-browser 团队做过一个测试:20 个 AI Agent 并发运行,每个独立逆向一个网站并产出可用的适配器。
换句话说,让 Claude Code 读一遍 guide,然后让它自己去 network --with-body 抓包、写适配器、测试、提 PR——全程自动。把一个新网站接入 Agent 世界的边际成本,基本趋近于零。
这其实是一个很有想象力的方向。当"给网站写 CLI 适配器"这件事本身可以被 AI Agent 自动完成,那覆盖整个互联网只是时间问题。
也是一个完整的浏览器自动化工具
除了 site 命令,bb-browser 本身也支持完整的浏览器操作:
bb-browser open https://example.com
bb-browser snapshot -i # 可访问性树
bb-browser click @3 # 点击元素
bb-browser fill @5 "hello" # 填写输入框
bb-browser eval "document.title" # 执行 JS
bb-browser fetch URL --json # 带登录态的 fetch
bb-browser network requests --with-body --json # 抓包
bb-browser screenshot # 截图
支持 --json 输出、--jq 过滤、--tab 多标签页并发。不只是一个"让 AI 能上网"的工具,也可以当浏览器自动化框架来用。
我的看法
bb-browser 解决的不是一个新问题,但它用了最直接的方式去解决。
之前也有人做"浏览器自动化给 AI 用"的产品,但大多数走的是"建一个云端浏览器池"的路线——成本高、延迟大、用户还不放心自己的登录态交给第三方。
bb-browser 选了一条完全不同的路:不碰你的数据,不存你的 Cookie,一切都在你本地浏览器里发生。 它只是一个"管道",让 AI Agent 的指令能到达你的浏览器。
当然,这个项目也还比较早期。适配器质量参差不齐,部分平台的适配可能因为网站改版而失效。但社区驱动 + AI Agent 自动生成适配器的模式,让它扩展速度会非常快。
如果你是 Claude Code、Cursor 的重度用户,或者在做 AI Agent 相关的开发,bb-browser 值得试试。
项目地址: https://github.com/epiral/bb-browser
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

