大家好,我是何三,独立开发者
说到TTS(文字转语音),很多人第一反应是调OpenAI的API,或者跑Python环境装一堆依赖。
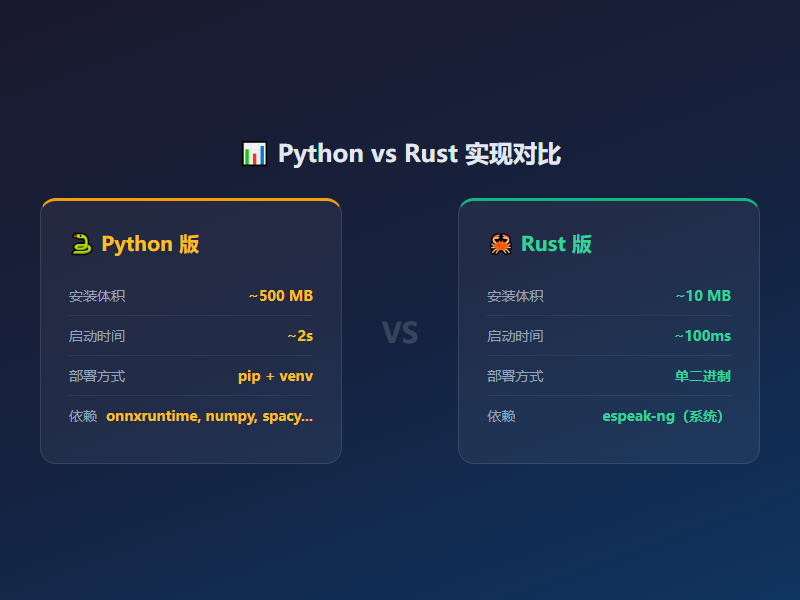
但最近我发现了一个叫 kitten_tts_rs 的开源项目,用Rust重写了KittenTTS,把整个TTS能力塞进了一个不到10MB的二进制文件里,最小模型才25MB。
这是什么概念?你连Python都不用装,下载一个可执行文件就能跑。
这项目干了什么
kitten_tts_rs 是 second-state 团队做的,他们把原版Python的KittenTTS移植成了Rust实现。
原版KittenTTS本身就很轻量,模型参数从1500万到8000万不等。但Python版本的部署依然需要装onnxruntime、numpy、spacy这些依赖,整个虚拟环境加起来快500MB了。
Rust版本直接把这些全砍了。一个编译好的二进制文件,加上espeak-ng做音素转换,就能跑。
而且不只是CLI工具,它还内置了一个 OpenAI兼容的API服务,支持SSE流式传输。也就是说,你可以直接用它替换OpenAI的TTS接口。
模型有多大
四个模型可选,我直接拉一张图:

说实话,25MB这个模型大小让我有点意外。现在动不动就是几个G的大模型,25MB连一张高清图片都比它大。
性能方面,在Mac M4 Pro上测试,nano-int8版本的RTF(Real-Time Factor)只有0.11,意味着生成1秒的音频只需要0.11秒,比实时快了9倍。
就算最大的80M参数mini模型,RTF也在0.26左右,依然比实时快4倍。
这对实时语音应用来说,相当够用了。
怎么用
安装
先装espeak-ng(这是唯一的系统依赖):
# macOS
brew install espeak-ng
# Ubuntu/Debian
sudo apt-get install -y espeak-ng
然后从GitHub Releases下载对应的预编译二进制:
# Linux x86_64
curl -LO https://github.com/second-state/kitten_tts_rs/releases/latest/download/kitten-tts-x86_64-linux.tar.gz
tar xzf kitten-tts-x86_64-linux.tar.gz
# macOS Apple Silicon
curl -LO https://github.com/second-state/kitten_tts_rs/releases/latest/download/kitten-tts-aarch64-macos.tar.gz
tar xzf kitten-tts-aarch64-macos.tar.gz
下载模型
curl -LO https://github.com/second-state/kitten_tts_rs/releases/latest/download/kitten-tts-models.tar.gz
tar xzf kitten-tts-models.tar.gz
命令行生成语音
# 基本用法
./kitten-tts ./models/kitten-tts-mini 'Hello, world!' Bruno
# 指定音色、语速和输出文件
./kitten-tts ./models/kitten-tts-mini 'Hello, world!' --voice Luna --speed 1.2 --output hello.wav
# 查看可用音色
./kitten-tts ./models/kitten-tts-mini "" --list-voices
内置了8个音色:Bella、Jasper、Luna、Bruno、Rosie、Hugo、Kiki、Leo,男女各半。
启动API服务
这才是我觉得最有价值的部分:
./kitten-tts-server ./models/kitten-tts-mini --host 0.0.0.0 --port 8080
启动后就是一个标准的OpenAI兼容接口:
curl -X POST http://localhost:8080/v1/audio/speech \
-H 'Content-Type: application/json' \
-d '{
"model": "kitten-tts",
"input": "Hello, world! This is KittenTTS running as an API server.",
"voice": "alloy"
}' \
--output speech.mp3
注意这里的voice用的是OpenAI的名字(alloy、echo、fable等),项目内部自动映射到KittenTTS的音色。这意味你现有的代码如果调的是OpenAI的TTS接口,改个URL就能直接用。
支持mp3、opus、flac、wav、pcm多种输出格式,还能通过SSE做流式传输,适合实时语音对话场景。
工作原理
拆开看其实不复杂,整个流程分六步:
- 文本预处理 — 把数字"42"展开成"forty-two","$10.50"展开成"ten dollars and fifty cents"
- 音素转换 — 用espeak-ng把英文文本转成IPA音素
- Token编码 — 把音素映射成整数token ID
- 音色选择 — 从NPZ文件加载音色embedding
- ONNX推理 — 输入tokens、音色风格、语速参数,跑模型
- 音频编码 — 输出MP3/WAV/Opus等格式
核心推理用的是ONNX Runtime,不需要GPU,纯CPU跑就行。当然如果你想加速,也支持CUDA、TensorRT、CoreML等后端,通过Cargo feature flag开启。
不过作者也说了,对于这种小模型(15M-80M参数),CPU反而更快。他们在M4 Pro上测试,CoreML跑mini模型比CPU慢了1.7倍。原因很简单——模型太小,GPU调度的开销反而大于计算本身。
适合什么场景
我觉得这几个场景特别适合:
- 边缘设备:树莓派、手机上跑TTS,25MB的模型完全没问题
- AI Agent:作为Agent的语音输出能力,CLI工具非常方便调用
- 私有化部署:不想把文本发给OpenAI,本地跑一个API服务就搞定
- 实时对话:SSE流式传输,接EchoKit这类实时语音应用
最后说两句
独立开发者做产品,TTS是经常用到的能力。之前要么调云服务API(要花钱、有隐私问题),要么本地跑Python(部署麻烦)。
kitten_tts_rs这种"一个二进制+一个小模型"的方案,刚好卡在了一个很舒服的位置:够轻量、够快、部署够简单。
项目Apache-2.0协议,222个Star,地址放下面了:
GitHub:https://github.com/second-state/kitten_tts_rs
有兴趣的朋友可以star一下,或者直接跑起来试试。

