大家好,我是何三,独立开发者
最近在研究本地 AI 部署方案,之前找这类方案总遇到集成难、速度慢的问题 —— 直到发现 Nexa SDK 这个开源项目,算是给本地 AI 需求搭了个"高集成度方案"。
今天就来聊聊这个能让你在手机上跑大模型的工具。
什么是 Nexa SDK?
简单来说,Nexa SDK 是一个完整的 AI 模型推理工具包,它让你能够在本地轻松运行各种 AI 模型,而不需要依赖云端服务。
这就好比你想做饭,以前需要去餐厅点外卖(调用云端 API),现在 Nexa SDK 给你配了一套完整的厨房设备,让你在家就能自己做,而且想做什么菜都行。
它支持多种模型格式,包括 GGUF、MLX 和 Nexa 格式,能够跨 NPU、GPU 和 CPU 运行。这意味着无论你的设备配置如何,都能找到合适的运行方式。
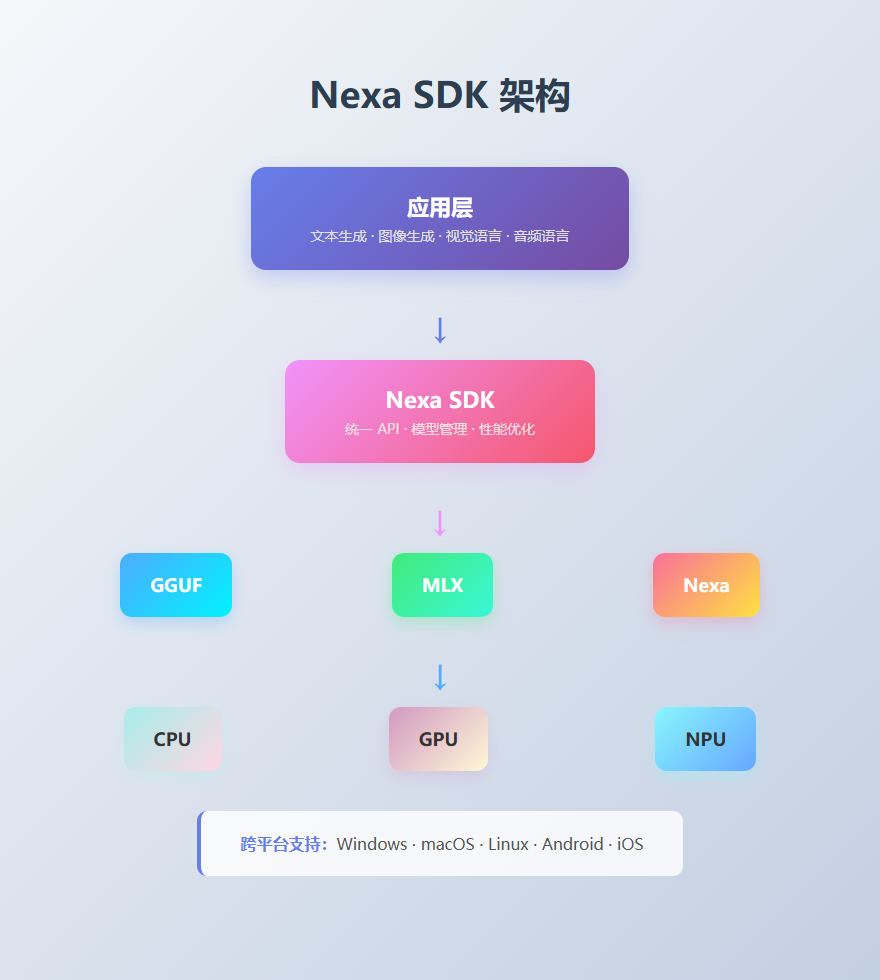
为什么选择本地部署?
说到这里,可能有人会问:云端 API 用得好好的,为什么要折腾本地部署?
主要有这几个原因:
1. 数据隐私:本地运行,数据不出设备,对于处理敏感信息特别重要
2. 离线可用:断网也能用,出差、旅行时照样可以工作
3. 成本控制:不用按次付费,一次性部署,无限次使用
4. 响应速度:本地推理,没有网络延迟,响应更快

Nexa SDK 的核心功能
Nexa SDK 支持的功能非常丰富,主要包括:
文本生成:支持各种大语言模型,比如 Llama、Mistral 等
图像生成:可以运行 Stable Diffusion 等图像生成模型
视觉语言模型:支持多模态模型,能看图说话
音频语言模型:支持语音相关的 AI 模型
最厉害的是,它支持端侧部署,这意味着你可以在手机、平板等移动设备上运行这些模型。
快速上手
安装 Nexa SDK 非常简单,只需要一行命令:
pip install nexa-sdk
安装完成后,就可以开始使用了。比如运行一个文本生成模型:
from nexa import NexaClient
# 创建客户端
client = NexaClient()
# 加载模型
model = client.load_model("llama-2-7b-chat")
# 生成文本
result = model.generate("你好,请介绍一下自己")
print(result)
就这么简单!几行代码就能在本地运行大模型。
实战案例:本地 AI 助手
让我们用 Nexa SDK 来实现一个简单的本地 AI 助手:
from nexa import NexaClient
import time
class LocalAIAssistant:
def __init__(self, model_name="llama-2-7b-chat"):
self.client = NexaClient()
self.model = self.client.load_model(model_name)
self.conversation_history = []
def chat(self, user_input):
# 添加用户输入到历史记录
self.conversation_history.append(f"User: {user_input}")
# 构建上下文
context = "\n".join(self.conversation_history[-5:])
# 生成回复
response = self.model.generate(context)
# 添加回复到历史记录
self.conversation_history.append(f"Assistant: {response}")
return response
def clear_history(self):
self.conversation_history = []
# 使用示例
assistant = LocalAIAssistant()
while True:
user_input = input("你: ")
if user_input.lower() in ["退出", "exit", "quit"]:
break
response = assistant.chat(user_input)
print(f"AI: {response}")
这个简单的助手可以在本地运行,不需要联网,保护你的隐私。
性能优化技巧
Nexa SDK 提供了一些优化技巧,可以提升模型推理效率:
1. 选择合适的模型格式 - GGUF:适合 CPU 推理,兼容性好 - MLX:适合 Apple Silicon 设备,性能优秀 - Nexa:优化的专有格式,性能最佳
2. 调整量化参数
model = client.load_model("llama-2-7b-chat", quantization="4bit")
使用 4-bit 量化可以大幅减少内存占用,同时保持较好的性能。
3. 批量处理
responses = model.generate_batch([
"问题1",
"问题2",
"问题3"
])
批量处理可以提高吞吐量。
应用场景
Nexa SDK 的应用场景非常广泛:
1. 移动端应用 - 智能客服 - 个人助理 - 离线翻译
2. 边缘计算 - 智能摄像头 - 工业检测 - 物联网设备
3. 个人开发 - 快速原型开发 - 本地测试 - 学习研究

总结
Nexa SDK 是一个强大的本地 AI 推理工具,它让本地部署 AI 模型变得简单易用。
核心优势: - 支持多种模型格式 - 跨平台运行 - 简单易用的 API - 丰富的功能支持
适用人群: - 想要保护数据隐私的开发者 - 需要离线 AI 服务的用户 - 对 AI 感兴趣的学习者 - 需要快速原型开发的团队
如果你也想体验本地 AI 的魅力,不妨试试 Nexa SDK。GitHub 地址:https://github.com/NexaAI/nexa-sdk

