大家好,我是何三,独立开发者
之前分享过《自己采购组装一个AI小智到底需要多少钱?》
如果你手上有一块十几块钱的 ESP32 开发板,想把它变成一个能听懂人话、能对话、还能控制家电的 AI 语音助手——这件事现在真的可以做到了。
最近我在 GitHub 上刷到一个项目,xiaozhi-esp32-server,9.1k Star,3.1k Fork,由华南理工大学刘思源教授团队主导研发。简单说,它给 ESP32 这块廉价芯片提供了一个完整的后端服务,让智能语音助手的搭建从"理论上可行"变成了"普通人也能玩"。
今天这篇文章,我把这个项目的核心架构、功能特性、部署方式拆开聊聊。
它到底是个什么项目?
小智 ESP32 Server 是一个开源的后端服务项目,配套另一个项目 xiaozhi-esp32 一起使用。xiaozhi-esp32 负责跑在硬件上(语音采集、播放、WiFi通信),xiaozhi-esp32-server 负责跑在服务器上(协议解析、模型调用、任务调度)。
两者配合,就构成了一套完整的 AI 语音交互系统。

技术栈上用了 Python + Java + Vue,支持 MQTT+UDP 协议和 WebSocket 协议,还接入了声纹识别、知识库、MCP 协议等能力。光看这些关键词可能有点晕,我画了一张架构图,上面的流程一目了然:ESP32 设备通过 MQTT/WebSocket 连接后端,后端调度 ASR、LLM、TTS 等云端服务完成语音交互。
功能全到有点离谱
我翻了翻它的功能清单,说实话,对于一个开源项目来说,覆盖面相当广:
语音交互这块,支持流式 ASR(语音识别)和流式 TTS(语音合成),还带 VAD(语音活动检测),能实时打断。也就是说它不是那种"我说完了等它处理"的笨模式,而是可以边说边响应。
多模态能力,接入了多种视觉大模型(VLLM),支持拍照识物,可以给 ESP32 接个摄像头,让它"看见"东西。
声纹识别,多人家庭场景下能分辨是谁在说话,然后给出个性化回应。这个功能是本地跑的,基于 3D-Speaker,免费。
记忆系统,支持本地短期记忆、mem0ai 接口记忆、PowerMem 智能记忆三种模式。不是每次对话都从零开始,它能记住之前聊过的内容。
工具调用,支持 IoT 协议控制家电、MCP 协议接入各种工具。你可以说"打开客厅灯",它真的能帮你开灯。
知识库,通过 RAGFlow 接入 RAG(检索增强生成),可以让大模型基于你自己的知识库来回答问题,比如公司规章制度、产品手册之类的。
管理后台,自带 Web 智控台,支持用户管理、设备管理、系统配置,还有移动端 H5 版本。
模型支持:几乎覆盖了主流平台

让我比较惊喜的是,这个项目对各类模型的支持非常广泛。
大模型(LLM) 方面,支持阿里百炼、火山引擎、DeepSeek、智谱、Gemini、科大讯飞等平台,还支持 Ollama 本地部署、Dify、FastGPT、Coze 等中间层。只要兼容 OpenAI 接口,基本都能接。
TTS(语音合成) 的选择更多,EdgeTTS 免费、灵犀流式 TTS 免费,也支持火山引擎、科大讯飞、阿里云等商业方案,甚至可以本地跑 FishSpeech、GPT-SOVITS 等开源 TTS。
ASR(语音识别) 支持 FunASR 本地部署和 SherpaASR,也支持讯飞、火山、腾讯云、阿里云等云端方案。
最关键的是,项目提供了两种配置方案:
- 入门全免费:所有组件都用免费方案,适合个人家庭玩,零成本。LLM 用智谱的 glm-4-flash(免费),ASR 用本地 FunASR,TTS 用灵犀流式或 EdgeTTS。
- 流式配置:适合演示培训场景,响应更快。LLM 用阿里百炼的 qwen-flash,TTS 用火山双流,ASR 用讯飞流式。比免费方案快大约 2.5 秒。
部署:Docker 一把梭
部署方式给了两种选择:
最简化安装:只跑 server,数据存配置文件,不需要数据库。最低 2 核 2G(全用 API 的情况下)。
全模块安装:完整功能,带管理后台、多用户系统,数据存数据库。最低 2 核 4G(全用 API),如果跑本地 FunASR 则需要 4 核 8G。
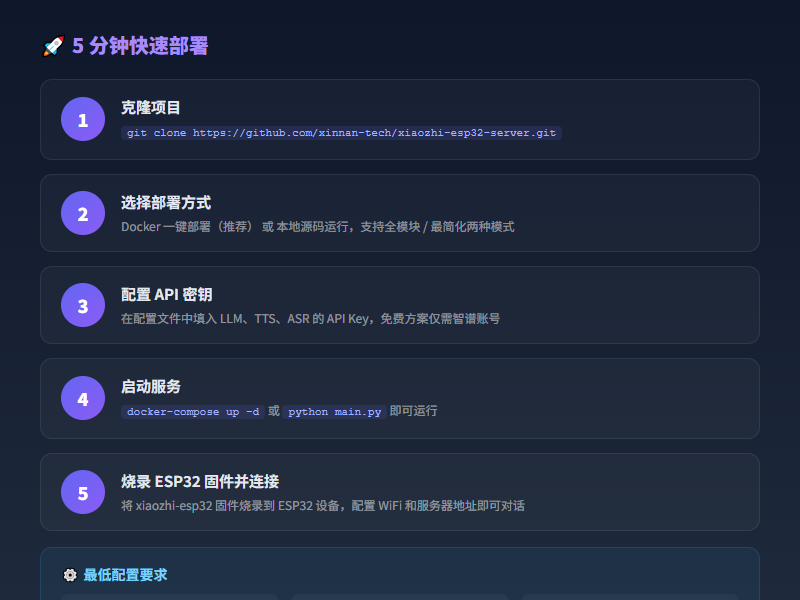
两种都支持 Docker 和源码部署。Docker 方式推荐新手使用,基本上 clone 下来配好 API Key 就能跑。
项目还贴心地提供了测试工具,包括音频交互测试页面和模型响应速度测试脚本,可以分别测 ASR、LLM、VLLM、TTS 各模块的响应延迟。
适合什么人玩?
官方的说法比较实在:如果你已经买了 ESP32 相关硬件,成功对接过别人部署的后端,现在想自己搭一个独立的服务——那这个项目就是给你准备的。
换句话说,它不是一个开箱即用的"智能音箱成品",而是一套让有一定动手能力的开发者自己搭建智能语音系统的基础设施。你需要一块 ESP32(或兼容板),需要一个能跑 Python/Java 的服务器,还需要去各大平台注册账号拿 API Key。
但这个门槛,相比自己从头写一套语音交互系统,已经低了太多太多。
一些值得留意的点
这个项目目前还在活跃开发中,版本已经到了 v0.9.2,72 个 Release,3300+ 次提交。社区活跃度不低。
不过官方也提醒了:项目功能还没完全完善,没有通过网络安全测评,不建议在生产环境中使用。公网部署的话记得做好安全防护。
还有一个细节——项目基于"人机共生智能理论"研发。这个来自华南理工大学刘思源教授团队的理论方向,给这个开源项目赋予了比较独特的学术基因。
怎么说呢
一块十几块钱的 ESP32,配上开源的后端服务,加上各大平台免费的大模型 API,你就能在家搭一个能对话、能识物、能控制家电的 AI 助手。
这件事放在两年前,基本是不可想象的。现在不但可行,而且有人在 GitHub 上帮你把坑都踩得差不多了。
如果你对 AI + 硬件的交叉领域感兴趣,这个项目值得你花一个周末折腾一下。
项目地址:https://github.com/xinnan-tech/xiaozhi-esp32-server 配套硬件项目:https://github.com/78/xiaozhi-esp32
本文使用 MGO 编辑并发布
关注"何三笔记",回复"mgo" 免费下载使用

