大家好,我是何三,独立开发者。
今天要给大家介绍一个超级强大的 Python 爬虫框架——Scrapling。如果你经常做数据采集,肯定遇到过这些头疼的问题:网站改版导致选择器失效、被 Cloudflare 等反爬系统拦截、需要同时处理静态和动态页面、大规模爬虫难以管理……

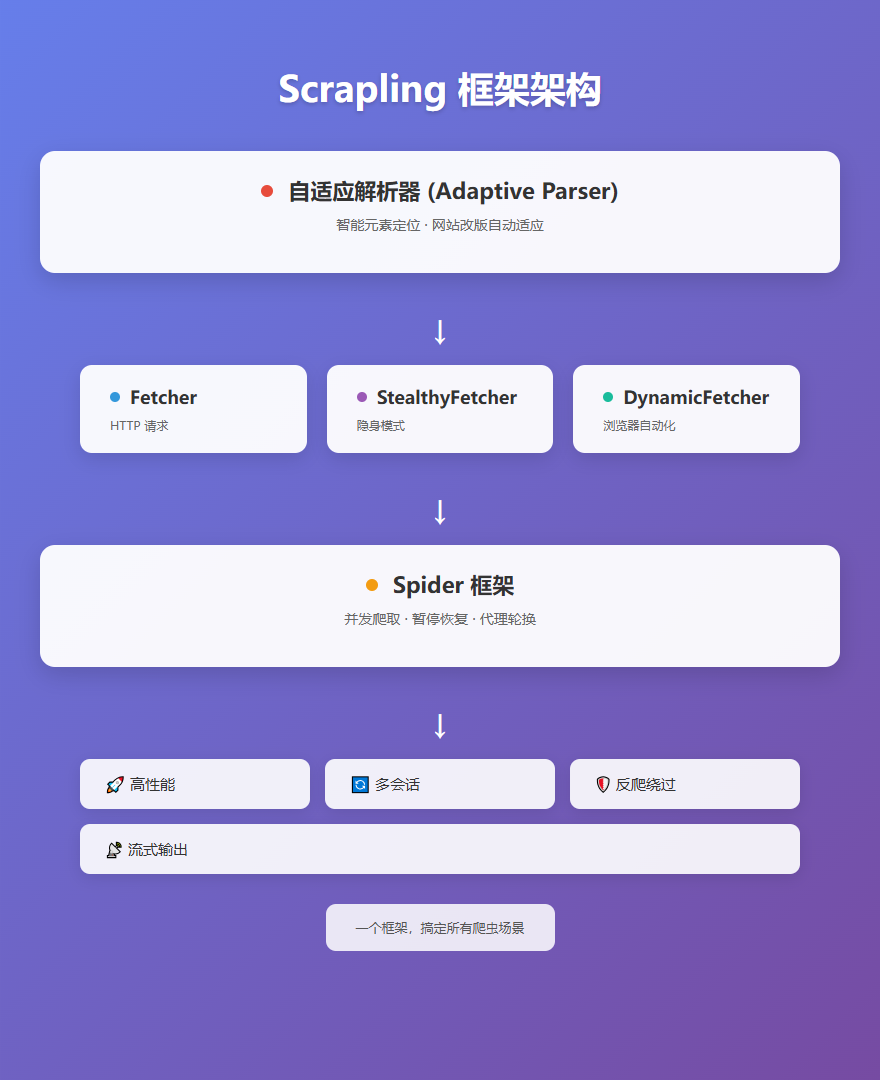
Scrapling 就是为了解决这些问题而生的。它是一个自适应的 Web Scraping 框架,从单个请求到大规模爬虫都能轻松搞定。最厉害的是,它的解析器能学习网站变化,当页面更新时自动重新定位元素,再也不怕网站改版了!
为什么需要 Scrapling?
传统的爬虫框架虽然功能强大,但在实际使用中往往存在一些痛点:
选择器脆弱:网站一改版,你的爬虫就挂了,需要手动重新编写选择器。
反爬困难:Cloudflare Turnstile 等反爬系统越来越智能,传统的请求方式很容易被拦截。
场景复杂:有的页面是静态的,有的是动态渲染的,有的需要浏览器自动化,切换起来很麻烦。
扩展性差:从简单的单页面爬取扩展到大规模爬虫时,往往需要重构整个代码。
Scrapling 正是针对这些问题设计的,它提供了统一的 API,让爬虫开发变得简单高效。
Scrapling 的核心特性
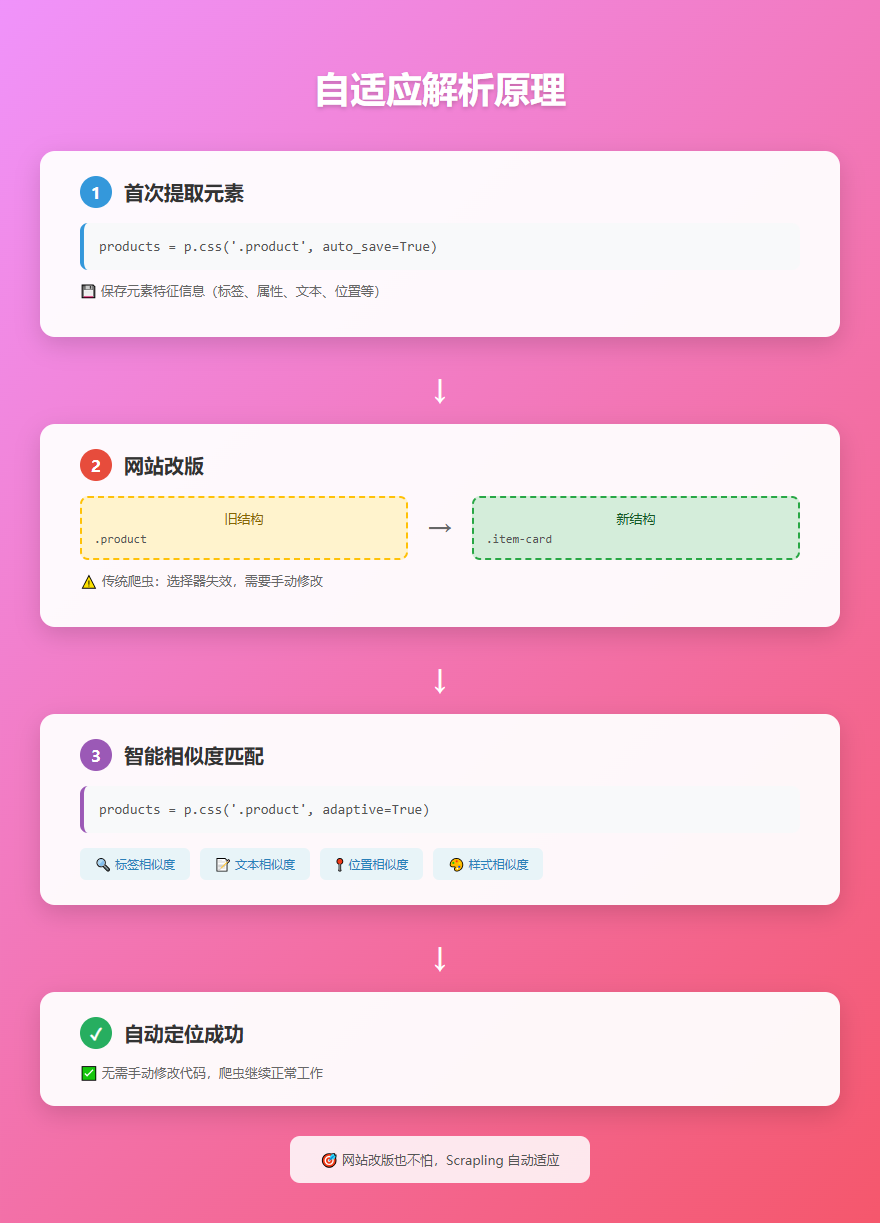
1. 自适应解析
这是 Scrapling 最酷的功能。当你使用 auto_save=True 提取元素时,Scrapling 会保存元素的特征信息。如果网站改版了,你只需要把 adaptive=True 传进去,它就能通过智能相似度算法自动找到新的元素位置!
from scrapling.fetchers import StealthyFetcher
p = StealthyFetcher.fetch('https://example.com', headless=True)
products = p.css('.product', auto_save=True) # 第一次提取,保存特征
# 网站改版后
products = p.css('.product', adaptive=True) # 自动找到新的元素
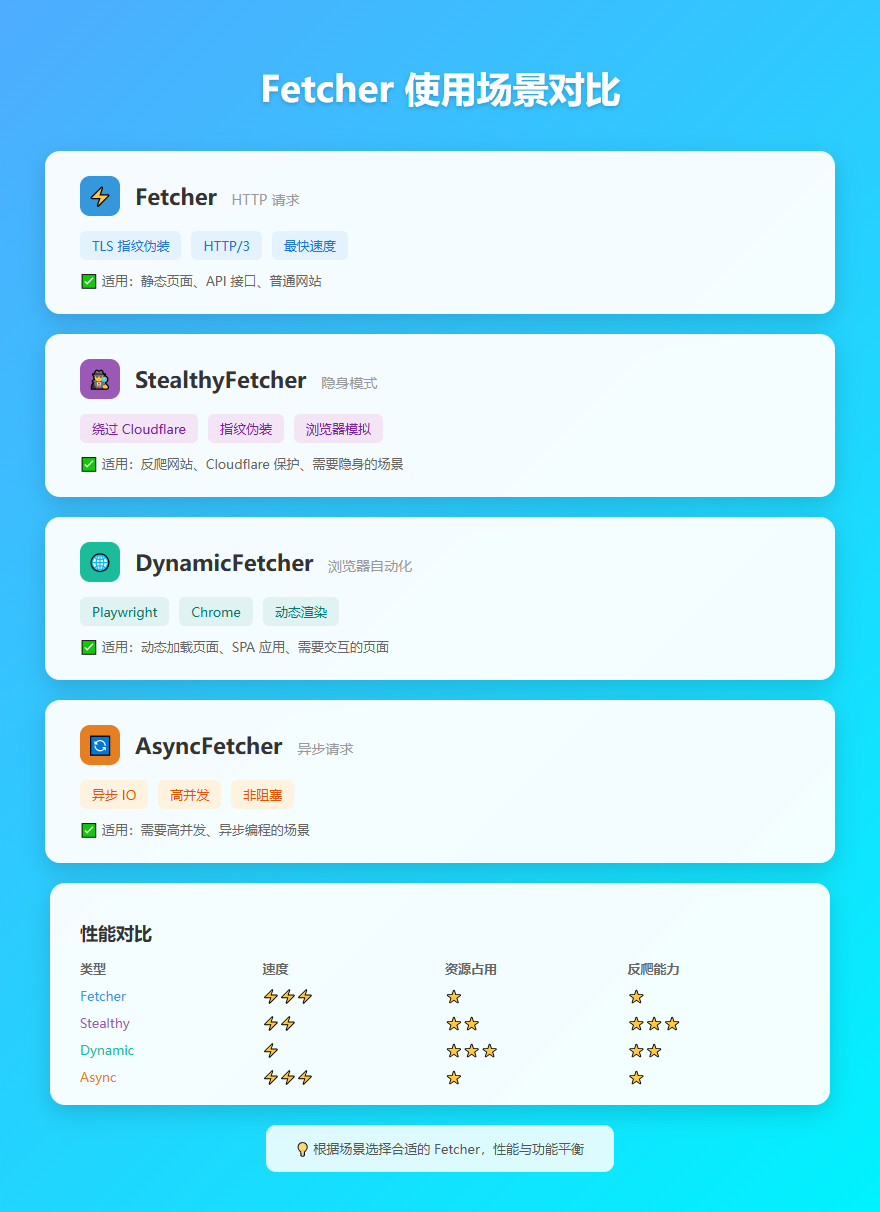
2. 强大的 Fetchers
Scrapling 提供了多种 Fetcher,适应不同场景:
- Fetcher:快速的 HTTP 请求,支持 TLS 指纹伪装、HTTP/3
- AsyncFetcher:异步版本的 Fetcher
- StealthyFetcher:高级隐身模式,可以绕过 Cloudflare Turnstile
- DynamicFetcher:完整的浏览器自动化,支持 Playwright 和 Chrome
from scrapling.fetchers import Fetcher, StealthyFetcher, DynamicFetcher
# 简单的 HTTP 请求
page = Fetcher.get('https://example.com/')
# 隐身模式,绕过反爬
page = StealthyFetcher.fetch('https://protected-site.com', headless=True)
# 浏览器自动化
page = DynamicFetcher.fetch('https://dynamic-site.com/')
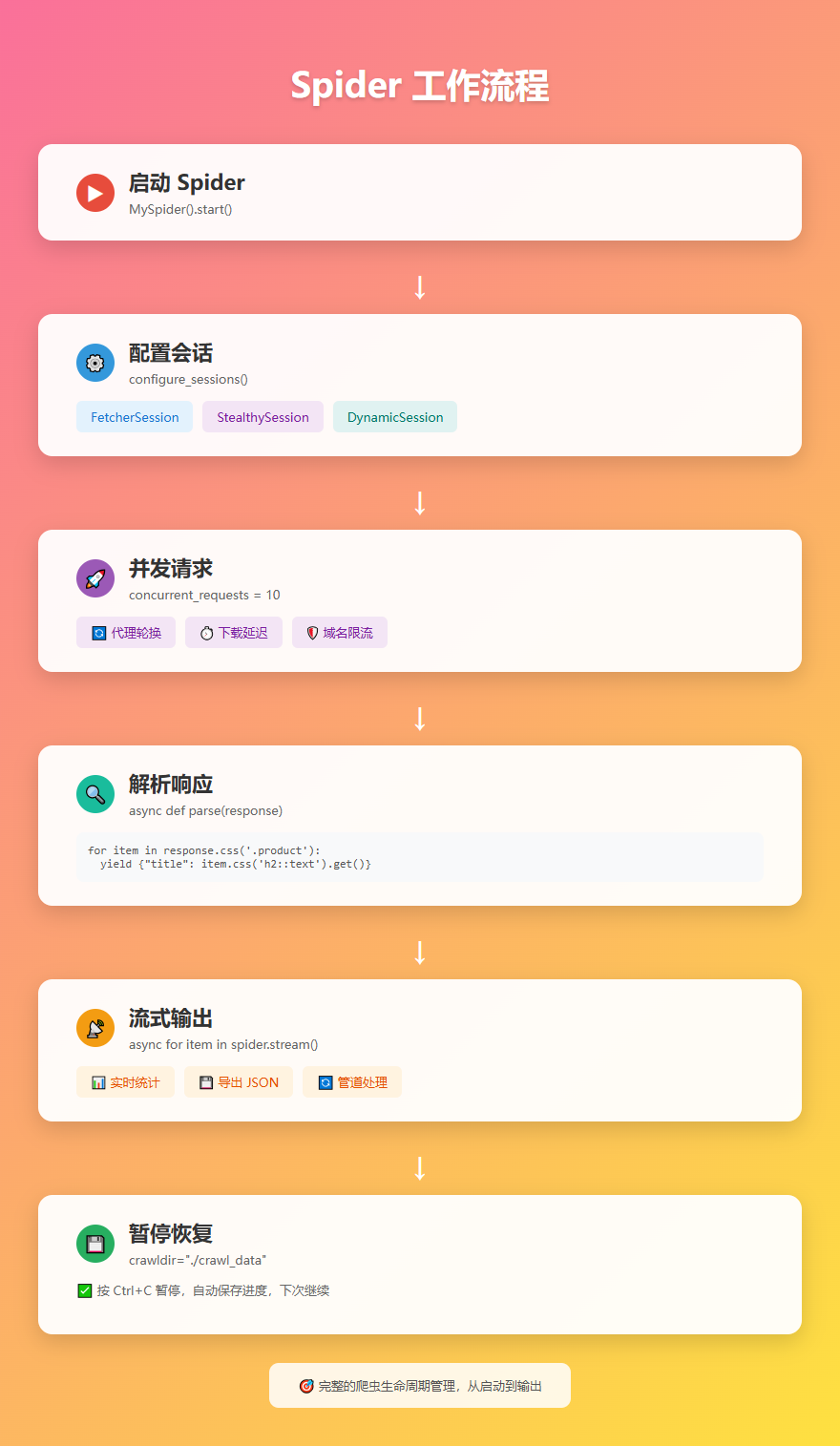
3. Spider 框架
如果你需要大规模爬虫,Scrapling 的 Spider 框架提供了类似 Scrapy 的 API,支持并发爬取、暂停恢复、代理轮换等功能。
from scrapling.spiders import Spider, Response
class MySpider(Spider):
name = "demo"
start_urls = ["https://example.com/"]
concurrent_requests = 10
async def parse(self, response: Response):
for item in response.css('.product'):
yield {
"title": item.css('h2::text').get()
}
result = MySpider().start()
4. 多会话支持
你可以在同一个 Spider 中使用不同类型的会话,根据需要路由请求:
from scrapling.spiders import Spider
from scrapling.fetchers import FetcherSession, AsyncStealthySession
class MultiSessionSpider(Spider):
def configure_sessions(self, manager):
manager.add("fast", FetcherSession(impersonate="chrome"))
manager.add("stealth", AsyncStealthySession(headless=True))
async def parse(self, response):
for link in response.css('a::attr(href)').getall():
if "protected" in link:
yield Request(link, sid="stealth") # 使用隐身会话
else:
yield Request(link, sid="fast") # 使用快速会话
5. 暂停和恢复
长时间运行的爬虫支持暂停和恢复,按 Ctrl+C 会优雅地保存进度,下次启动时自动继续:
# 第一次运行
MySpider(crawldir="./crawl_data").start()
# 按下 Ctrl+C 暂停
# 下次继续
MySpider(crawldir="./crawl_data").start() # 自动从上次停止的地方继续
性能对比
Scrapling 不仅功能强大,性能也非常出色。根据官方基准测试,在文本提取速度方面:

- Scrapling:2.02ms
- Parsel/Scrapy:2.04ms(几乎持平)
- BeautifulSoup:1584.31ms(慢了 784 倍!)
在元素相似性查找方面,Scrapling 也比 AutoScraper 快了 5 倍多。
安装和使用
安装非常简单:
# 基础安装(只包含解析器)
pip install scrapling
# 完整安装(包含所有功能)
pip install "scrapling[all]"
scrapling install # 安装浏览器依赖
或者使用 Docker:
docker pull pyd4vinci/scrapling
总结
Scrapling 是一个设计精良的爬虫框架,它解决了传统爬虫的很多痛点:
✅ 自适应解析:网站改版也不怕,自动重新定位元素
✅ 反爬绕过:内置 Cloudflare Turnstile 绕过能力
✅ 统一 API:HTTP、隐身、浏览器自动化,一个框架搞定
✅ 高性能:解析速度快,内存占用低
✅ 易扩展:从单页面到大规模爬虫,无缝切换
✅ 类型提示:完整的类型注解,IDE 支持友好
如果你经常做数据采集,Scrapling 绝对值得一试。它让爬虫开发变得简单、高效、稳定。
注意:使用爬虫工具时,请遵守网站的 robots.txt 和服务条款,尊重数据隐私和法律法规。

