大家好,我是何三,独立开发者。
今天给大家介绍一个超级实用的工具——Shimmy。如果你想在本地运行大语言模型,但又不想折腾复杂的配置,那这篇文章就是为你准备的。
为什么要本地运行 LLM?
现在用大语言模型,主要有两种方式:云服务和本地部署。
云服务包括国内的DeepSeek、智普、月之暗面、通义千问、文心一言、混元等,国外的 OpenAI、Claude 等。虽然方便,但也有几个痛点:
成本问题:按 token 计费,用多了钱包受不了。特别是开发调试阶段,反复测试会消耗不少费用。国内云服务虽然价格相对便宜,但长期使用也是一笔不小的开销。
隐私问题:代码和数据都要上传到云端,对于一些敏感项目来说,这不太合适。企业级应用尤其担心数据泄露风险。
网络问题:国外服务需要翻墙,网络不稳定;国内服务虽然访问方便,但高峰期也可能遇到限流或服务不稳定的情况。
限流问题:免费账号有速率限制,付费账号也有 QPS 限制,高并发场景下容易遇到瓶颈。
模型选择受限:云服务提供的模型是固定的,想测试新模型或切换不同模型,需要等待服务商更新。
这些问题,本地运行 LLM 都能解决。但本地运行也有自己的难题——配置复杂、依赖多、不同模型需要不同的后端支持。
Shimmy 是什么?
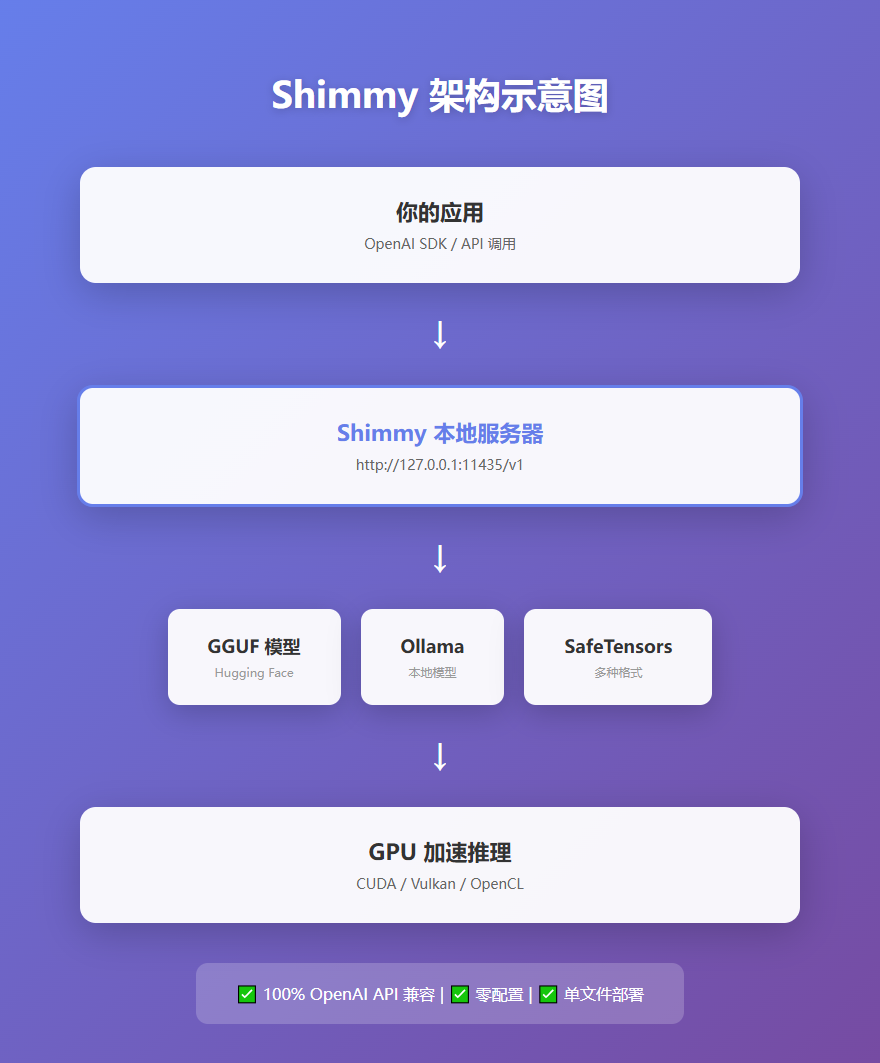
Shimmy 是一个用 Rust 编写的轻量级 OpenAI API 兼容服务器。简单说,它就是一个本地版的 OpenAI API,你只需要下载一个可执行文件,就能在本地运行各种大语言模型。
它的核心特点包括:
零配置:自动发现 Hugging Face 缓存、Ollama、本地目录中的模型,不需要任何配置文件。
完全兼容 OpenAI API:只需修改 API 地址,现有的 OpenAI SDK 代码就能直接用,无需改代码。
单文件部署:预编译的二进制文件包含了所有 GPU 后端(CUDA、Vulkan、OpenCL),下载就能用。
支持多种模型格式:支持 GGUF、SafeTensors 等主流格式,还支持 LoRA 适配器。
免费开源:永久免费,没有"现在免费以后收费"的套路。
30 秒快速上手
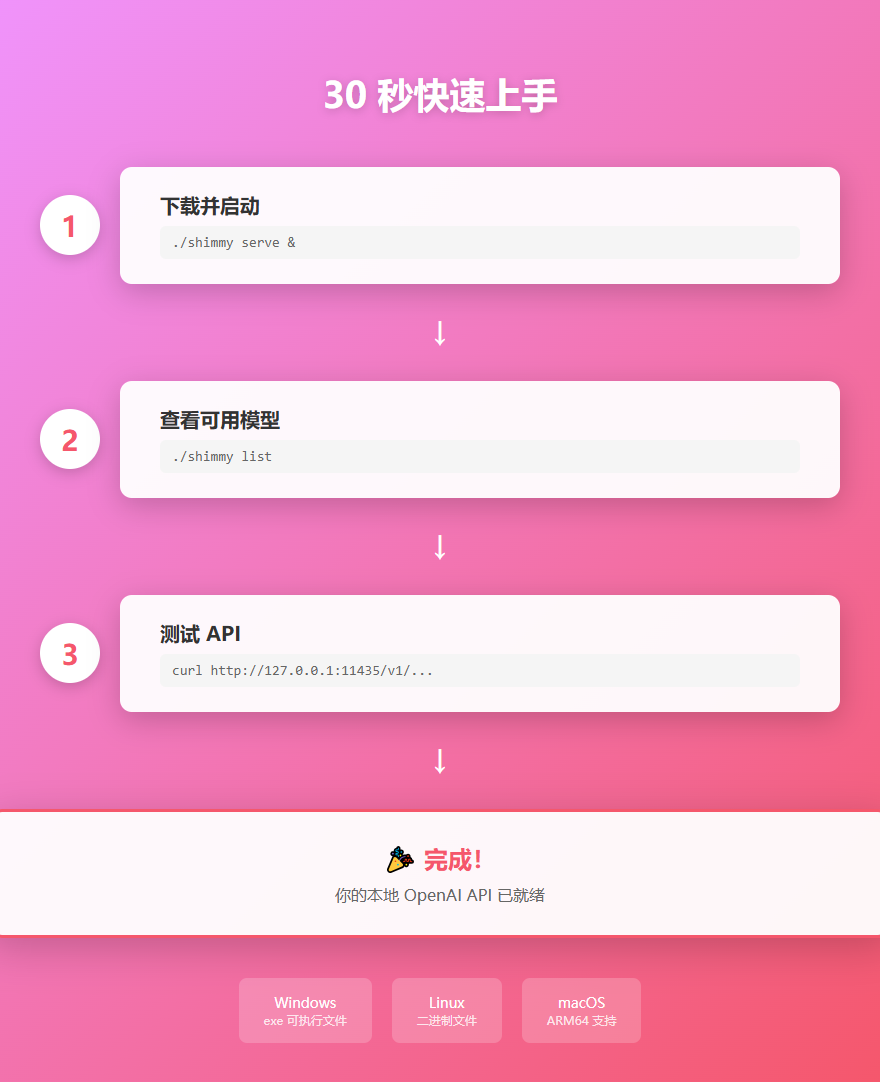
Shimmy 的使用非常简单,三步就能跑起来。
第一步:下载并启动服务
# Windows 用户
curl -L https://github.com/Michael-A-Kuykendall/shimmy/releases/latest/download/shimmy-windows-x86_64.exe -o shimmy.exe
./shimmy.exe serve &
# Linux 用户
curl -L https://github.com/Michael-A-Kuykendall/shimmy/releases/latest/download/shimmy-linux-x86_64 -o shimmy && chmod +x shimmy
./shimmy serve &
# macOS 用户(Apple Silicon)
curl -L https://github.com/Michael-A-Kuykendall/shimmy/releases/latest/download/shimmy-macos-arm64 -o shimmy && chmod +x shimmy
./shimmy serve &
第二步:查看可用模型
./shimmy list
这个命令会列出所有发现的模型,包括 Hugging Face 缓存、Ollama 和本地目录中的模型。
第三步:测试 API
curl -s http://127.0.0.1:11435/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model":"REPLACE_WITH_MODEL_FROM_list",
"messages":[{"role":"user","content":"Say hi in 5 words."}],
"max_tokens":32
}' | jq -r '.choices[0].message.content'
就这么简单!你的本地 OpenAI API 服务已经跑起来了。
代码实战:用 Python 调用 Shimmy
Shimmy 完全兼容 OpenAI SDK,所以你只需要修改 base_url 和 api_key,其他代码都不用动。
from openai import OpenAI
# 创建客户端,指向本地 Shimmy 服务
client = OpenAI(
base_url="http://127.0.0.1:11435/v1",
api_key="sk-local" # Shimmy 会忽略这个参数,但 OpenAI SDK 需要
)
# 调用聊天接口
resp = client.chat.completions.create(
model="REPLACE_WITH_MODEL", # 替换为你的模型名称
messages=[{"role": "user", "content": "你好,请用5个字打招呼"}],
max_tokens=32,
)
print(resp.choices[0].message.content)
如果你用的是 Node.js,代码也几乎一样:
import OpenAI from "openai";
const openai = new OpenAI({
baseURL: "http://127.0.0.1:11435/v1",
apiKey: "sk-local",
});
const resp = await openai.chat.completions.create({
model: "REPLACE_WITH_MODEL",
messages: [{ role: "user", content: "Say hi in 5 words." }],
max_tokens: 32,
});
console.log(resp.choices[0].message?.content);
高级功能:MOE 混合推理
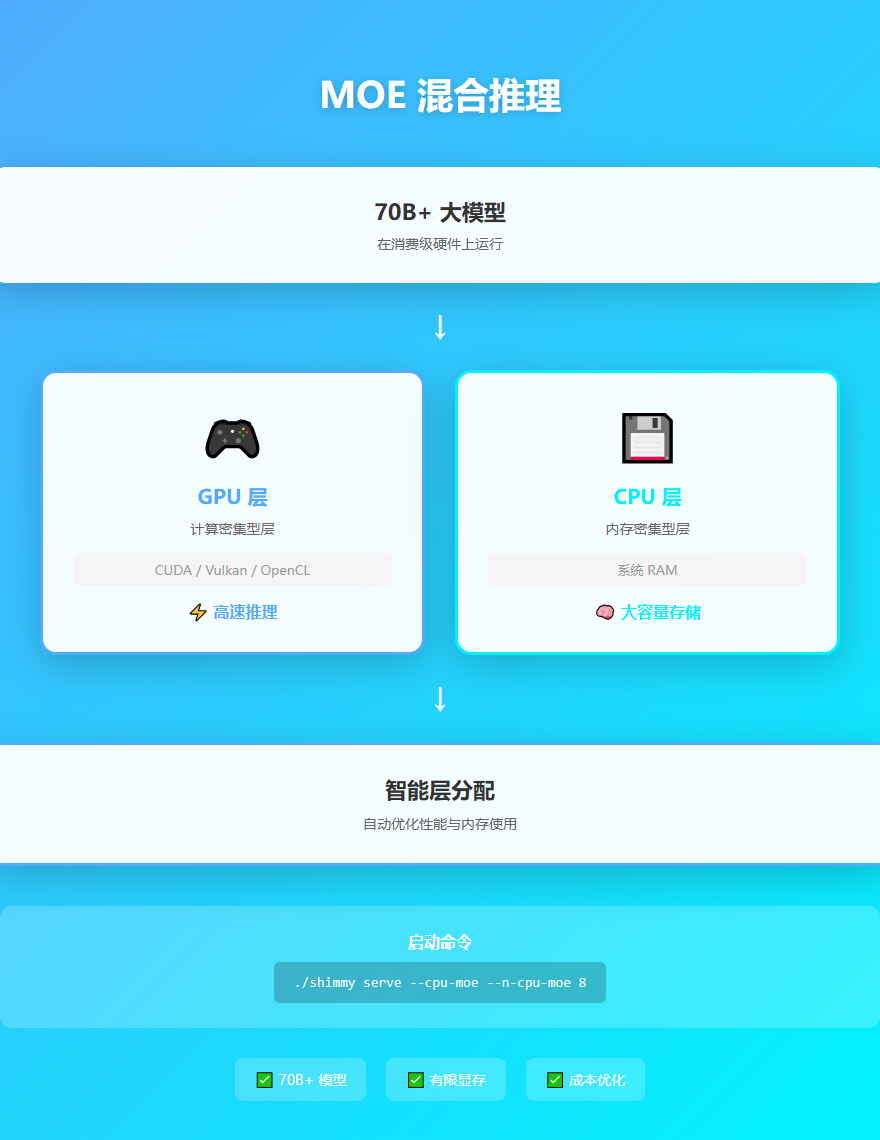
Shimmy 还支持 MOE(Mixture of Experts)混合推理,可以在有限的显存上运行更大的模型。
简单来说,就是把模型的不同层分配到 CPU 和 GPU 上运行,GPU 负责计算密集的层,CPU 负责内存密集的层,这样就能在消费级显卡上运行 70B+ 的模型。
# 启用 MOE 混合推理
./shimmy serve --cpu-moe --n-cpu-moe 8
这个功能特别适合: - 显存有限但想运行大模型 - 需要平衡性能和成本 - 在消费级硬件上测试大模型
实际应用场景
Shimmy 非常适合以下场景:
本地开发调试:在本地测试代码,不用消耗 API 额度,也不用担心网络问题。
隐私敏感项目:代码和数据都在本地,不上传到任何云端服务。
离线环境:在没有网络的环境下也能运行 AI 功能。
成本控制:一次性下载模型,之后无限使用,没有按 token 计费的压力。
多模型测试:快速切换不同模型进行对比测试。
与其他工具的对比
| 特性 | Shimmy | Ollama | LocalAI |
|---|---|---|---|
| 单文件部署 | ✅ | ❌ 需要安装 | ❌ 需要安装 |
| OpenAI API 兼容 | ✅ 100% | ✅ 部分 | ✅ 部分 |
| 自动发现模型 | ✅ | ✅ | ❌ |
| 多 GPU 后端 | ✅ 内置 | ✅ | ✅ |
| MOE 混合推理 | ✅ | ❌ | ❌ |
| 配置复杂度 | 极低 | 低 | 中 |
总结
Shimmy 是一个真正做到了"开箱即用"的本地 LLM 推理工具。它最大的优势就是简单——下载、运行、使用,三步搞定。
对于独立开发者来说,Shimmy 解决了本地运行 LLM 的核心痛点: - 不用折腾复杂的依赖和配置 - 完全兼容 OpenAI API,代码零改动 - 支持多种模型和 GPU 后端 - 永久免费,没有后顾之忧
如果你想在本地运行大语言模型,但又不想花费太多时间在环境配置上,Shimmy 绝对值得一试。

